2.4十进制数的表示
1> 用ASCⅡ码字符串的方式来表示十进制数,0~9分别对应30H~39H.ASCⅡ
2> BCD码
2.5非数值数据的编码表示
1> 逻辑值: 逻辑值是计算机语言,意为逻辑状态下赋予的真或者假。逻辑值有两种情况:成立和不成立。成立的时候我们说逻辑值为真,使用True或1表示,不成立的时候我们说逻辑值为假,使用false或0表示。在程序设计里面,一般关系运算符的结果、逻辑运算符运算的结果都是逻辑值。
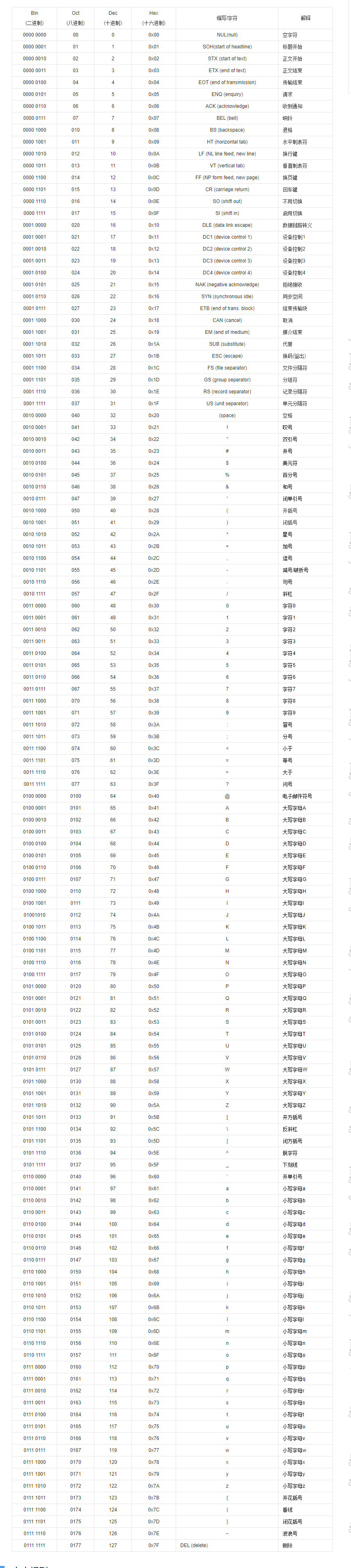
2> 西文字符:目前计算机中使用最广泛的西文字符集及其编码是ASCⅡ码↓
3> 汉字字符:
1.汉字输入码: 汉字输入码也称外码,是为将汉字输入到计算机设计的代码。汉字输入码种类较多,选择不同的输入码方案,则输入的方法及按键次数、输入速度均有所不同。综合起来,汉字输入码可分为流水码、拼音类输入法、拼形类输入法和音形结合类输入法几大类。
2.字符集与汉字内码
2.6数据的宽度和储存
1> 数据的宽度和单位: 在电子学领域里,表带宽是用来描述频带宽度的。但是在数字传输方面,也常用带宽来衡量传输数据的能力。用它来表示单位时间内(一般以“秒”为单位)传输数据容量的大小,表示吞吐数据的能力。这也意味着,宽的带宽每秒钟可以传输更多的数据。所以我们一般也将“带宽”称为“数据传输率”(硬盘的数据传输率是衡量硬盘速度的一个重要参数)。
字节 (byte):8个二进制位为一个字节(B),最常用的单位。计算机存储单位一般用B,KB,MB,GB,TB,PB,EB,ZB,YB,BB来表示,它们之间的关系是:
1B(Byte字节)=8bit
1KB (Kilobyte 千字节)=1024B,
1MB (Mega byte 兆字节 简称“兆”)=1024KB,
1GB (Giga byte 吉字节 又称“千兆”)=1024MB,
1TB (Tera byte 万亿字节 太字节)=1024GB,其中1024=2^10 ( 2 的10次方),
1PB(Peta byte 千万亿字节 拍字节)=1024TB,
1EB(Exa byte 百亿亿字节 艾字节)=1024PB,
1ZB (Zetta byte 十万亿亿字节 泽字节)= 1024 EB,
1YB (Yotta byte 一亿亿亿字节 尧字节)= 1024 ZB,
1BB (Bronto byte 一千亿亿亿字节)= 1024 YB
1NB(Nona byte )= 1024BB
1DB(Dogga byte)= 1024NB
市面上卖硬盘的都是按1000计算,号称500G硬盘=50010001000*1000B。
毫无疑问,全地球所有的硬盘总容量加起来也可能不到1BB。1BB是什么概念?。我这样说:地球上有60亿人,每人要有16万个1TB容量的硬盘,则全球硬盘总容量才能达到1BB。换个方法说:假设地球上有100个硬盘厂家,那么每个厂家要生产10万亿个1TB的硬盘,地球硬盘总容量才能达到1BB。
2.7数据校验码
数据在传输的过程中,会受到各种干扰的影响,如脉冲干扰,随机噪声干扰和人为干扰等,这会使 数据产生差错。为了能够控制传输过程的差错,通信系统必须采用有效措施来控制差错的产生。
常用的差错控制方法让每个传输的数据单元带有足以使接收端发现差错的冗余信息,这种方法不能 纠正错误,但可以发现数据错误,这种方法容易实现,检错速度快,可以通过重传使错误纠正,所 以是非常常用的检错方案。
一般来说,合理地增加校验位、增大码距,就能提高检错/纠错的能力
1> 奇偶校验码:为了判断数据在传送中是否发生了错误,可按照如下步骤来判断↓
第一步:在源部件求出奇(偶)校验位。
第二步:在目标部件求出奇(偶)校验位。
第三步:计算最终的校验位,并根据其值判断有无奇偶错。
2> 海明检验码: 将有效信息按某种规律分成若干组,每组安排一个校验位,做奇偶测试,就能提供多位检错信息,以指出最大可能是哪位出错,从而将其纠正。实质上,海明校验是一种多重校验。
3> 循环冗余校验码 : 循环冗余校验码(cyclie redundancy check)简称CRC(循环码),是一种能力相当强的检错、纠错码,并且实现编码和检码的电路比较简单,常用于串行传送(二进制位串沿一条信号线逐位传送)的辅助存储器与主机的数据通信和计算机网络中。
循环码是指通过某种数学运算实现有效信息与校验位之间的循环校验(而海明码是一种多重校验)。
这种编码基本思想是将要传送的信息M(X)表示为一个多项式L,用L除以一个预先确定的多项式G(X),得到的余式就是所需的循环冗余校验码。
这种校验又称多项式校验。
理论上可以证明循环冗余校验码的检错能力有以下特点:①可检测出所有奇数位错;②可检测出所有双比特的错;③可检测出所有小于、等于校验位长度的突发错