1. 理论review
1.1 RNN
-
Agenda
- From feed-forward to recurrent / Tricks & treats / Presidential tweets
-
BPTT
- Use sum of gradients each all timesteps to update parameters
- Computationally expensive for a lot of timesteps
-
Truncated BPTT: A fixed number of timesteps + BPTT
- Won’t be able to capture the full sequential dependencies
- In non-eager TensorFlow, have to make sure all inputs are of the same length
-
Exploding/vanishing Gradients
-
the problems of RNN: In practice, RNNs aren’t very good at capturing long-term dependencies
1.2 LSTMs
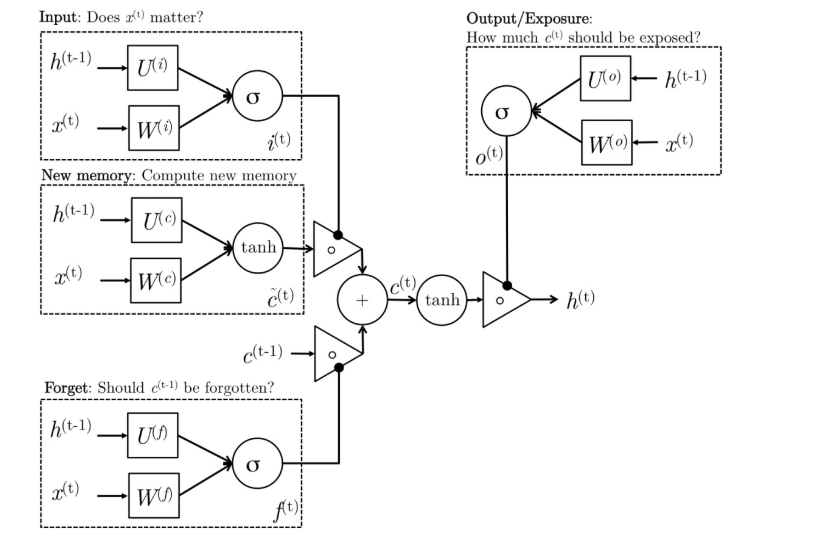
- Using a gating mechanism to control what information to enter and emit from the cell at each timestep
- input gate: how much of the current input to let through.
- forget gate: how much of the previous state to take into account.
- output gate: how much of the hidden state to expose to the next step.
- candidate gate (cell unit ?)
- final memory cell
- 感觉必要时,需要参考cs224d(stanford)
1.3 GRUs(Gated Recurrent Units)
-
简化的LSTMs(性能相当,但是计算成本更低)
-
理解LSTM 和 GRU,来自 cs224d
-
-
Intuitively, we can think of the gate as controlling what information to enter and emit from the cell at each timestep. All the gates have the same dimensions.
- input gate: decides how much of the current input to let through.
- forget gate: defines how much of the previous state(cell state) to take into account.
- output gate: defines how much of the hidden state to expose to the next timestep.
- candidate gate: similar to the original RNN, this gate computes the candidate hidden state based on the previous hidden state and the current input.
- final memory cell: the internal memory of the unit combines the candidate hidden state with the input/forget gate information. Final memory cell is then computed with the output gate to decide how much of the final memory cell is to be output as the hidden state for this current step.
-
LSTM vs GRU

-
1.4 what RNNs can do ? (还是看cs224d吧)
2. RNNs in Tensorflow
2.1 基本介绍
-
BasicRNNCell / RNNCell / BasicLSTMCell / LSTMCell / GRUCell
-
简单代码
# cell cell = tf.nn.rnn_cell.GRUCell(hidden_size) # layers layers = [tf.nn.rnn_cell.GRUCell(size) for size in hidden_sizes] cells = tf.nn.rnn_cell.MultiRNNCell(layers) # 感觉是把上面的cells link 起来 # Construct Recurrent Neural Network 1) tf.nn.dynamic_rnn: uses a tf.While loop to dynamically construct the graph when it is executed. Graph creation is faster and you can feed batches of variable size. 2) tf.nn.bidirectional_dynamic_rnn: dynamic_rnn with bidirectional # Stack multiple cells layers = [tf.nn.rnn_cell.GRUCell(size) for size in hidden_sizes] cells = tf.nn.rnn_cell.MultiRNNCell(layers) output, out_state = tf.nn.dynamic_rnn(cell, seq, length, initial_state) # Most sequences are not of the same length # Dealing with variable sequence length 1) Pad all sequences with zero vectors and all labels with zero label (to make them of the same length) 2) Most current models can’t deal with sequences of length larger than 120 tokens, so there is usually a fixed max_length and we truncate the sequences to that max_length # the problem Padded/truncated sequence length 1) The padded labels change the total loss, which affects the gradients # apporach to solve above problem Apporach-1 1-1) Maintain a mask (True for real, False for padded tokens) 1-2) Run your model on both the real/padded tokens (model will predict labels for the padded tokens as well) 1-3) Only take into account the loss caused by the real elements # full_loss = tf.nn.softmax_cross_entropy_with_logits(preds, labels) loss = tf.reduce_mean(tf.boolean_mask(full_loss, mask)) # Approach-2: Let your model know the real sequence length so it only predict the labels for the real tokens # cell = tf.nn.rnn_cell.GRUCell(hidden_size) rnn_cells = tf.nn.rnn_cell.MultiRNNCell([cell] * num_layers) tf.reduce_sum(tf.reduce_max(tf.sign(seq), 2), 1) output, out_state = tf.nn.dynamic_rnn(cell, seq, length, initial_state) -
Tips and Tricks
-
Vanishing Gradients
- Use different activation units:
- tf.nn.relu / tf.nn.relu6 / tf.nn.crelu / tf.nn.elu
- In addition to: tf.nn.softplus / tf.nn.softsign / tf.nn.bias_add / tf.sigmoid / tf.tanh
- Use different activation units:
-
Exploding Gradients
-
Clip gradients with tf.clip_by_global_norm
gradients = tf.gradients(cost, tf.trainable_variables()) # take gradients of cosst w.r.t. all trainable variables clipped_gradients, _ = tf.clip_by_global_norm(gradients, max_grad_norm) # clip the gradients by a pre-defined max norm optimizer = tf.train.AdamOptimizer(learning_rate) train_op = optimizer.apply_gradients(zip(gradients, trainables)) # add the clipped gradients to the optimizer
-
-
Anneal the learning rate
# Optimizers accept both scalars and tensors as learning rate learning_rate = tf.train.exponential_decay(init_lr, global_step, decay_steps, decay_rate, staircase=True) optimizer = tf.train.AdamOptimizer(learning_rate) -
Overfitting
-
Use dropout through tf.nn.dropout or DropoutWrapper for cells
# tf.nn.dropout hidden_layer = tf.nn.dropout(hidden_layer, keep_prob) # DropoutWrapper cell = tf.nn.rnn_cell.GRUCell(hidden_size) cell = tf.nn.rnn_cell.DropoutWrapper(cell, output_keep_prob=keep_prob)
-
-
2.2 Language Modeling
-
Language Modeling: Main approaches
- Word-level: n-grams
- Character-level
- Subword-level: somewhere in between the two above
-
Language Modeling: N-grams
- The traditional approach up until very recently. Train a model to predict the next word based on previous n-grams
- problem of above N-grams ?
- Huge vocabulary
- Can’t generalize to OOV (out of vocabulary)
- Requires a lot of memory
-
Language Modeling: Character-level
-
Introduced in the early 2010s. Both input and output are characters
-
the Pros & Cons of above Ch..-Level ?
-
Pros:
- Very small vocabulary
- Doesn’t require word embeddings
- Faster to train
Cons:
- Low fluency (many words can be gibberish)
-
-
Language Modeling: Hybrid
- Word-level by default, switching to character-level for unknown tokens
-
Language Modeling: Subword-Level (介于 Character-level 与 Word-level 之间)
-
Input and output are subwords
-
Keep W most frequent words
-
Keep S most frequent syllables
-
Split the rest into characters
-
Seem to perform better than both word-level and character-level models*
-
举例:
new company dreamworks interactive new company dre+ am+ wo+ rks: in+ te+ ra+ cti+ ve:
-
2.3 demo code: Char-RNN Language Modeling
-
Goal: Presidential Tweet Bot (用tweet dataset训练一个发 tweet 的 bot,即 基于字符级别的文本生成)
-
Dataset: 19,469 Donald Trump’s tweets
-
参考:
[2] https://docs.google.com/document/d/1_ZqzBqFMV8YmdC2PmaTXOB9O1BZ14yLNTQd2_Bkff9Y/edit#
(重点看关于 tweet bot的细节)
[3] http://karpathy.github.io/2015/05/21/rnn-effectiveness/ (Andrej Karpathy的一些神奇发现)
-
更多实验细节,todo