论文地址:基于深度波形U-Net进行单耳语音增强
论文代码:https://github.com/Hguimaraes/SEWUNet
引用格式:Guimarães H R, Nagano H, Silva D W. Monaural speech enhancement through deep wave-U-net[J]. Expert Systems with Applications, 2020, 158: 113582.
摘要
在本文中,我们提出了一种端到端的语音增强方法--通过Wave-U-Net(SEWUNet)来降低语音信号中的噪声。该背景环境对几个下游系统是有害的,包括自动语音识别(ASR)和单词定位,这反过来会对终端用户应用产生负面影响。与文献中已有的机制相比,我们的方案确实提高了信噪比(SNR)和误字率(WER)。在实验中,网络输入是一个被加性噪声破坏的16 kHz采样率音频波形。我们的方法是基于Wave-U-Net结构,并针对我们的问题做了一些修改。提出了四种简单的增强措施,并用消融研究对其进行了测试,以证明它们的有效性。特别是,在进行主要去噪任务的训练之前,我们通过一个自动编码器突出了权值的初始化,从而更有效地利用了训练时间,获得了更高的性能。通过度量,我们证明了我们的方法优于经典的维纳滤波方法,并且表现出比其他最先进的方案更好的性能。
关键字:语音增强、噪声减少、Wave-U-Net、深度学习、信噪比、误字率
1 引言
我们见证了能够执行自动语音识别(ASR)和单词识别的系统的研究和使用的巨大增长。在广泛的领域都有应用:家庭和车载助理(Kepuska&;Bohouta,2018;Lockwood&;Boudy,1991);电信和联系中心(Rabiner,1997;Eilbacher,Bodner,Lubowsky,Boudreau,&;Jakobsche,2004);国土安全(Neustein&;Patil,2012);营销决策(Wedel&;Kannan,2016);为残疾人设计的软件(Wald, 2005);医疗文件(Edwardset al., 2017);游戏(Luisi, 2007)等等。
在这个端到端的过程中,一个关键的部分是语音到文本的转换,这可能会受到音频噪声的负面影响,并产生具有高错字率(WER)的文本。例如,错误的词或成分可能会影响分类的极性,在极限情况下,这些下行应用程序可能会变得不可用。
从语音信号中提取背景内容是语音去噪的主要任务,除了ASR问题外,对人类理解也是有用的,因此本工作的目的是扩展所有那些原本将被限制在较安静环境中的应用的操作范围,从语音信号中提取背景内容是语音去噪的主要任务。在音频域,我们注意到,由于音频本身的复杂性(例如,每秒高采样数、频率等),单声道记录上的这种干净的语音提取是一个高度不确定的问题。
这类问题与众所周知的鸡尾酒会效应有关,在鸡尾酒会效应中,大脑试图集中在特定的刺激中,同时过滤背景背景和其他噪声,类似于在聚会中发生转换。设$y$是带噪信号,$x$是干净的语音信号,而$\delta $是用来产生有噪信号的噪声。在这项工作中,我们将假设数据是干扰原始信号本身的加性噪声,如公式1中所定义:
$$公式1:y[n]=x[n]+\delta [n]$$
我们的目标是使用公式2,使用非线性变换创建映射,以尽可能映射纯净语音
$\hat{y}[n] \approx x[n]$
最近解决这个问题的方法依赖于谱信息和其他预处理技术。该方法的一个重要问题是在进行短时傅立叶逆变换时,增强后的信号会出现伪影。这个问题可以通过在原始波形上使用直接管道来缓解。另一方面,由于我们在1秒内有超过16000个样本,并且很难有效地处理非常长范围的时间依赖,因此计算成本和复杂度将会增加。
近年来,人们发现深度神经网络在语音处理任务中非常成功。LeCun和Bengio(1995)提出了一类特殊的神经网络,称为卷积神经网络(CNN),专注于处理具有网格状拓扑的数据,如音频,可以被认为是一维网格(Goodfloor,Bengio,&;Courville,2016)。
本文提出了一种端到端的深度学习方法--SEWUNet(Speech Enhancementthrough Wave-U-Net),利用全卷积神经网络来解决语音音频去噪的问题,并在此基础上提出了一种基于全卷积神经网络的端到端深度学习算法SEWUNet(Speech Enhancementthrough Wave-U-Net)。也就是说,我们试图增强语音信号,使其更适合ASR及后续系统。在实践中,我们开发了一个基于一维时域U-Net模型的体系结构,正如Wave-U-Net论文(Stoller,Ewert,&;Dixon,2018)所提出的那样,但有了增强。因此,本文的贡献在于对Wave-U-Net结构提出了四个简单的改进,这些改进有助于提高模型的性能和效率(即减少处理时间)。
我们希望采用我们的机制可以为所有的ASR和单词识别应用带来更好的性能和效率,其中一个重要的最终目标是改进它们,以便更好地进行决策。
本文的剩余的结构如下:第2节描述了对我们工作有启发的技术和问题;第3节介绍了我们的模型;第4节介绍了实验框架;第5节总结了结果;第6节总结了结论和未来的工作方向
2 相关工作
3 语音增强通过Wave-U-Net(SEWUNet)
在这里,我们在3.1、3.2和3.3小节中描述建模中采用的概念。第3.4节强调了我们与Stoller等人有关的工作的创造性方面。(2018年)
3.1 自动编码
训练成在输出层复制自己的输入的神经网络称为自动编码器。该网络可以看作是一个由编码器组成的两部分网络,该编码器负责映射h?f x?,其中x是我们干净的语音输入。另一部分是负责重建操作的解码器。自动编码器目标是按照如下方式训练网络。我们可以将概念从确定性函数推广到随机的角度,其中自动编码器试图映射p编码器和p解码器(GoodFellowet al.,2016),其中自动编码器试图映射p编码器和p解码器(GoodFellowet al.,2016)
即使将输入复制到网络的输出似乎没有意义,但我们真正感兴趣的是网络需要学习的有用特性,以便在一个小维度空间上表示输入。
在本文中,我们建议使用来自数据集保留部分的干净信号,将我们的模型训练为自动编码器,以在语音去噪训练之前执行权重初始化。
3.2 语义分割和U-Net
卷积网络的典型用途在于分类问题,其中输出是用于识别图像的类标签。 语义分割是一个流行的研究领域,尤其是在生物医学图像处理中,其思想是在像素级别理解图像,即可以为每个像素分配一个类别标签(Li et al., 2018)。 Ronneberger、Fischer 和 Brox (2015) 提出的 U-Net 模型解决了电子显微镜 (EM) 堆栈中神经元结构的分割问题,并赢得了国际生物医学成像研讨会 (ISBI) 挑战。
在图 1 中,我们可以看到 U-Net 的架构。 它是一个全卷积神经网络,具有收缩路径(左侧)、瓶颈层和扩展路径(右侧)。 左侧路径遵循 CNN 的典型架构,其中它们重复应用两个没有填充的卷积,然后是非线性激活函数 (ReLU) 和用于下采样的最大池化操作。 虽然该模型对空间进行了 2 倍的下采样,但它使网络中的特征通道数量增加了一倍(Ronneberger 等人,2015 年)。 在接下来的模型描述中,我们采用以下术语: (a) 神经网络某些基本部分的层(例如卷积层、最大池化层等); (b) 用于堆叠层的块(例如卷积层和 ReLU 激活)。
正确的路径由特征图的上采样操作(通常是转置卷积或双线性插值)组成,依次将特征通道的数量减半。 在那个操作之后,但仍然在同一个块中,他们从收缩路径连接来自同一级别的相应特征图,这个操作称为跳过连接。 在每个块中,有两个卷积层,后面又是一个 ReLU。 在最后一层,应用 1x1 卷积滤波器将每个组件从特征向量空间映射到所需数量的类。 在灰度图像中,类的数量为 1,对应于应用于输入以分割图像的掩码。
跳过连接的直觉是同时将一个块的输出提供给下一个块的输入和其他一些不相邻的块。 这个想法是我们使用在收缩路径上提取的信息以用于重建阶段。 如果没有这种连接,可能会丢失一些信息。
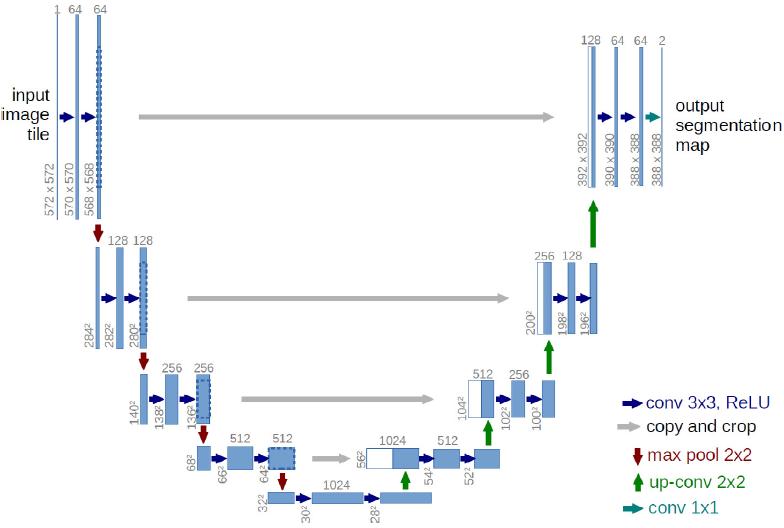
图1所示。U-Net架构定义在(Ronneberger et al., 2015)
3.3 Wave-U-Net
Wave-U-Net 通过使用原始波形和一维卷积将 U-Net 架构中的元素与 3.2 中讨论的一些架构方案相结合。 该网络由收缩路径(左侧)和扩展路径(右侧)组成,类似于 U-Net,但使用一维卷积作为基本块。 网络如图 2 所示。
Wave-U-Net 被提议用于接收混合信号$M\in [-1,1]^{l_m*c}$并将该信号在$K$个源波形中分离为$S^1,...,S^K$,其中$S^i\in[-1,1]^{L_s*C}$,$i\in\{1,...,K\}$。在该工作中,$L_m$和$L_s$表示音频信号上的样本数,C 表示通道数。在我们用单声道信号进行语音降噪的问题中,我们有$L_m=L_s$和$ C = K =1$。 可以检索背景信号,但我们只对语音感兴趣。
图中的每个块都有卷积层,后跟下采样或上采样操作。 下采样模块是一个抽取操作,我们将特征图的维度减半。 在上采样块中,我们测试了一些组合,例如线性插值和转置卷积。 除了扩展路径中的最后一层之外,所有层都有一个 LeakyReLU (Xu, Wang, Chen, & Li, 2015) 激活,$\alpha=0.1$。 最后一层(扩展路径上的block 1)具有双曲正切 (Tanh) 激活。
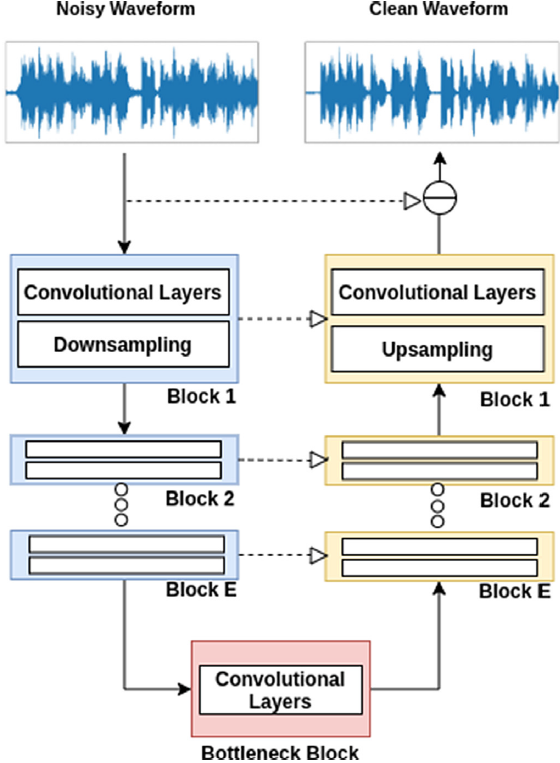
图2所示。用于语音增强的单耳波u网
3.4 我们的改进
基于Wave-U-Net模型,我们测试了多种架构和超参数。SEWUNet和最初的Wave-U-Net之间有四个主要区别:
1. 上采样方法:Stoller 等(2018) 提出了一个可学习插值层,可以在其中学习中间值。在我们的工作中,一个简单的线性插值在语音去噪任务上表现出良好的性能,并被选为主要的上采样操作。还测试了 Dumoulin 和 Visin (2016) 中描述的转置卷积。
2. 损失函数:有几篇论文针对这个问题提出了不同的损失函数,其中大部分基于回归损失。我们在 MSE 上测试了平均绝对误差 (MAE) 的性能,以构建我们的网络并在结果部分证明该选择的合理性。
3. 权重初始化:在为语音去噪的主要任务训练网络之前,我们最初将所提出的方法训练为自动编码器。这个想法是只使用干净语音数据集的保留部分来提取对语音分割有用的特征,并更有效地利用我们的训练时间,在更少的时期内实现收敛。
4. Reflection-padding:为了避免由零填充引入的边界区域上的伪影,我们使用了反射填充层。我们不是用零来跟踪边界,而是在边界区域反射样本以填充所需的空间。有关此操作的说明,请参见 pytorch.org (2019)。
4 实验
在本节中,我们将详细介绍用于开发和测试所提议的方法的设置。
4.1 数据集
我们基于LibriSpeech(Panayotov,Chen,Povey,&;Khudanpur,2015)和UrbanSound8K(Salamon,Jacoby,&Amp;Bello,2014)的混合构建了数据集。
通过改变噪声信号的幅度和能量,通过具有受控干扰水平的加法过程插入噪声。 训练集上干净的声音和混合声音之间的信噪比 (SNR) 落在 5 dB 和 15 dB ( 5; 15) 的范围内,均匀分布。 对于 ASR 测试,使用了另外两个 SNR 范围:0; 10 和 10; 20 仅在测试中。 在图 3 中,我们可以看到 SNR 为 5 dB 的附加噪声的影响。 作者公开了一些音频样本。 2
我们使用扬声器保持技术进行数据分区。 librispeech 数据集,更具体地说是 train-clean-100 子集,在说话者级别被分成两个相等的部分。 第一组用于训练自动编码器,在另一组中,我们插入噪声来训练网络以完成主要任务。 此添加噪声的数据集随后被分区以分别以 80%、10% 和 10% 的比例创建训练、验证和测试集。 对于这两个组,所有话语都是近 4:1 s 长度的非重叠段(每个音频 216 个数据样本)。
在UrbanSound8K中,我们有以下10个类别:空调、汽车喇叭、儿童玩耍、狗吠、钻孔、发动机怠速、枪声、手提钻、警报器和街头音乐。 我们还利用了噪声抑制技术,因此给定的噪声文件不能出现在多个部分(训练/验证/测试)中。 我们还遵循类别分层拆分策略,即我们尝试在不同部分之间保持类别的平均分布。
我们还使用了 LibriSpeech 的 test-clean 子集来测试系统在 ASR 模型上的有效性。 这个子集没有分成小窗口,我们使用全长的数据。 在这个子集上插入的噪声与我们在 Wave-U-Net 测试噪声的测试集上使用的噪声相同,但在多个 SNR 间隔中。 这项工作的数据库创建过程如图 4 所示。
语音数据集总共包含 72 个; 698 个干净的音频话语,对应于 82:8 小时的音频。 对于自动编码器部分,我们使用 32:9 小时进行训练,使用 8:4 小时进行测试。 对于主要任务,这个数据集被分割成 32:8; 训练、验证和测试分别为 4:3 和 4:4 小时。 有126名男性演讲者和125名女性演讲者。 UrbanSound8K数据集由8个组成; 732 个音频文件,其中有替换的样本。 如果噪声小于 4:1s,我们将重复连接音频。
4.2 硬件平台
这样的大型数据集和深度模型需要一些特定的计算努力来加载、处理和训练任务。我们使用了一台32 GB内存的桌面计算机,一个英特尔i5第9代6核处理器,以及一个NVidia RTX 2060超级GPU卡。
4.3 实现
我们使用 Pytorch 框架实现了网络,该框架在 Eager 模式下提供了易用性和灵活性,并且通过利用对异步执行的本机支持(Paszke 等人,2017 年),其性能针对研究和生产环境进行了优化。 所有带网络的源代码都是从头开始实现的,并且可以在 Github 中找到。
4.4 损失函数和度量
在原始波形上用于语音增强问题的度量有多种可能性。最简单的回归函数是MAE或MSE,但一些论文提出了自定义损失函数来解决这个问题,如Germain et al.(2018)和Rethage et al.(2018)。
在本文中,我们使用一种称为信噪比(SNR)的计算度量来理解在能量方面,分离的信号离目标有多远。度规的计算如式4所示。
$$公式4:\operatorname{SNR}(\widehat{Y}, X)=10 \log _{10}\left(\frac{\langle\widehat{Y}, \widehat{Y}\rangle}{\langle\widehat{Y}-X, \widehat{Y}-X>}\right)$$
其中$<,>$为内积,$X$为噪声信号,$\hat{Y}$为处理后的信号(去除噪声)。
为了计算对ASR系统的影响,我们使用单词错误率(WER)度量。WER基于Levenshtein距离,但基于单词级别而不是字符。
4.5 训练流程
训练神经网络时,我们使用Adam优化器,学习率为$10^{-1}$,$\beta_1=0.9$和$\beta_2=0.999$以及batch_size=16。学习速率可以在训练中调整,如果在5个时间段内没有改进,乘以0.1。在消融研究中,我们训练我们的模型超过25个epoch。权重初始化的自动编码器训练也进行了25 epoch训练。
4.6 模型
我们比较了一组五个模型,用$M=\{M0,M1,M2,M3,M4\}$表示。M0和M1遵循Wave-U-Net论文中提出的模型的实现,但对上采样块进行了简单的线性插值。它们之间的主要区别是M0使用MSE,而M1使用MAE。M2类似于M1,但我们使用的是零填充而不是反射填充。在模型M3中,我们将M1与转置卷积的用法进行了比较。最后,在模型M4中,我们利用了所有提议的增强功能。每个模型的设置如表1所示。
在所有模型中,我们使用相同的结构。在两条路径(e5)上网络的深度为5个块。在收缩路径上的卷积有一个大小为15的内核,在扩展路径上的内核大小为5。另外,为了使feature map在卷积块之后保持相同的大小,我们在卷积输入之前使用填充层,其窗口大小为$k//2$,其中$k$是内核大小。每层过滤器的数量与Wave-U-Net论文中设计的一样,但每层有8个额外的过滤器,如下公式$F=24*i+8$,其中$i\in\{1,...,L\}$。