1.选一个自己感兴趣的主题。
2.用python 编写爬虫程序,从网络上爬取相关主题的数据。
3.对爬了的数据进行文本分析,生成词云。
4.对文本分析结果进行解释说明。
5.写一篇完整的博客,描述上述实现过程、遇到的问题及解决办法、数据分析思想及结论。
6.最后提交爬取的全部数据、爬虫及数据分析源代码。
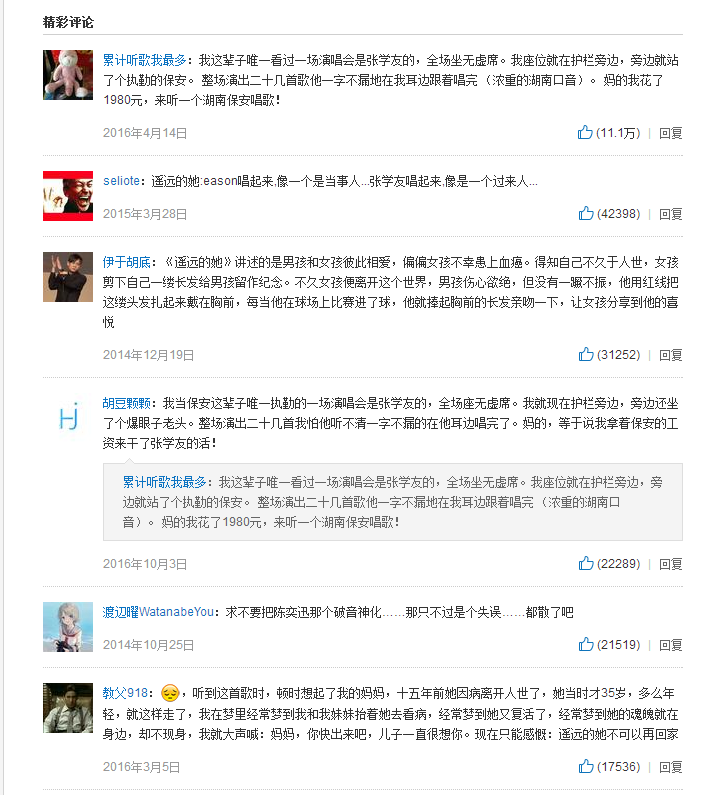
此次实验中,通过爬取网易云音乐-遥远的她网页中的热门评论来做词频分析
爬取热门评论并保存至txt文本的代码:
# -*- coding : UTF-8 -*- # -*- author : Kamchuen -*- # -*- file : project1 -*- # -*- time: 2018/4/28 -*- # -*- description: 歌曲热门评论获取-*- # -*- songname: 遥远的她-*- import requests import json def getcomments(musicid): url = 'http://music.163.com/weapi/v1/resource/comments/R_SO_4_191232?csrf_token=5594eaee83614ea8ca9017d85cd9d1b3'.format(musicid) payload = { 'params': '5KX6Y3k92jAA0++OK5aeNVeABXbc97L0PMviuChCa4cr1OW3wHCWDSLEtRyQwXdMC2+BbLjG3qA8N9gLOgL5WPBSl2qyIv++7YRnEn3BxO2hq6opl5B3Jgbi/I/PPkxneLfgYuIo71F0VxqAVaoJlMefBej5M/fZ5eO3YkvOKWaAHbtJYL+g17z8XskUfcHm', 'encSecKey': '5baedada4b87cc31a46b38d0a3893895da30fe3bddaf8a24020ce17fa004f2e646cb15e109c4786e55eca0e88dbd6dc905aa55fd6cd7f4de1e625937d986dd4e1217a19e4f4a2f0e00504763308148ab3215ae25a5ac99e65ba8e46f2f8a734182fc20c5a7281f1d127a513a954b17d66a75f4a06f0044fc6c783dd356b017a7' } headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36', 'Referer': 'http://music.163.com/song?id={}'.format(musicid), 'Host': 'music.163.com', 'Origin': 'http://music.163.com' } response = requests.post(url=url, headers=headers, data=payload) data = json.loads(response.text) hotcomments = [] for hotcomment in data['hotComments']: item = { 'nickname': hotcomment['user']['nickname'], 'content': hotcomment['content'] } hotcomments.append(item) # 返回热门评论 return [content['content'] for content in hotcomments] if __name__ == '__main__': hot = getcomments(191232) print(hot) file = open('hot.txt','w') for hotword in hot: file.write(hotword+' ') file.close()
打开txt文本生成词云的代码:
# -*- coding : UTF-8 -*- # -*- author : Kamchuen -*- # -*- file : wordcloudTest1 -*- # -*- time: 2018/4/28 -*- # -*- description: 词云测试-*- from os import path from PIL import Image import numpy as np import matplotlib.pyplot as plt from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator d = path.dirname(__file__) text = open(path.join(d, 'hot.txt')).read() alice_coloring = np.array(Image.open(path.join(d, "奥特曼.jpg"))) stopwords = set(STOPWORDS) stopwords.add("said") wc = WordCloud(background_color="white", max_words=2000, mask=alice_coloring, stopwords=stopwords, max_font_size=85, font_path="STHUPO.TTF",random_state=50) wc.generate(text) image_colors = ImageColorGenerator(alice_coloring) # show plt.imshow(wc, interpolation="bilinear") plt.axis("off") plt.figure() plt.imshow(wc.recolor(color_func=image_colors), interpolation="bilinear") plt.axis("off") plt.figure() plt.imshow(alice_coloring, cmap=plt.cm.gray, interpolation="bilinear") plt.axis("off") plt.show()
结果: