摘自https://www.cnblogs.com/pinard/p/6519110.html
一、RNN回顾

略去上面三层,即o,L,y,则RNN的模型可以简化成如下图的形式:
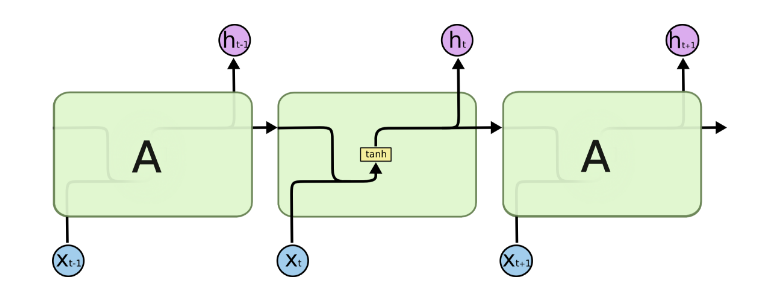
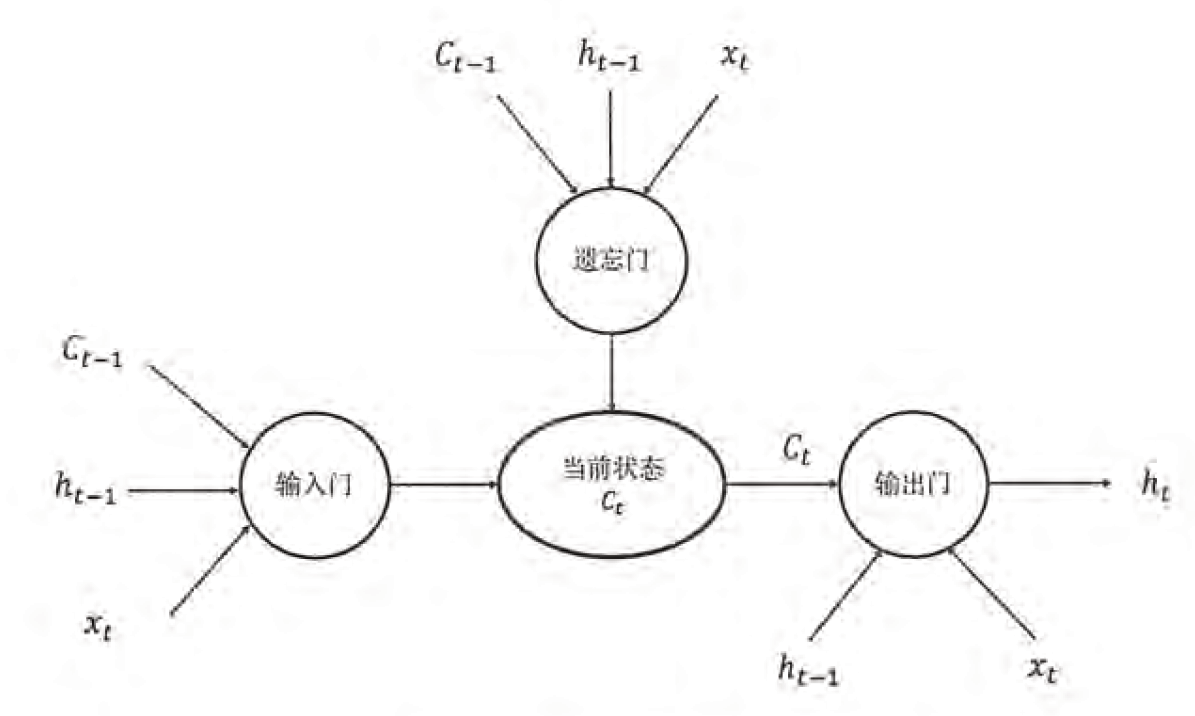
二、LSTM模型结构:
整体模型:
由于RNN梯度消失的问题,大牛们对于序列索引位置t的隐藏结构做了改进,可以说通过一些技巧让隐藏结构复杂了起来,来避免梯度消失的问题,这样的特殊RNN就是我们的LSTM。由于LSTM有很多的变种,这里我们以最常见的LSTM为例讲述。LSTM的结构如下图:
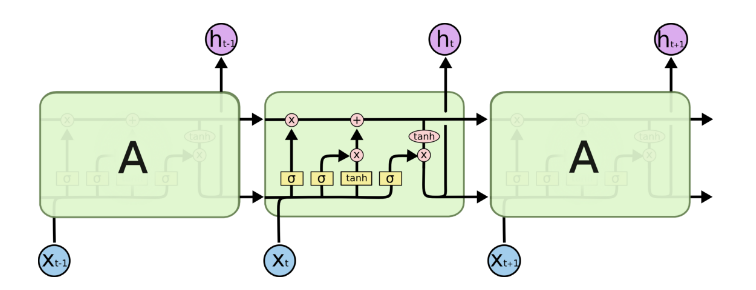
记忆细胞:
从上图中可以看出,在每个序列索引位置t时刻向前传播的除了和RNN一样的隐藏状态h(t),还多了另一个隐藏状态,如图中上面的长横线。这个隐藏状态我们一般称为细胞状态(Cell State),记为C(t)。如下图所示:
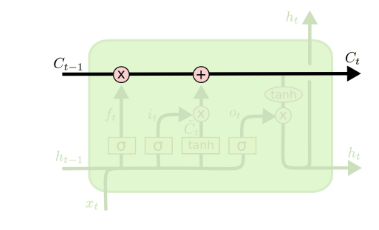
门控结构:
除了细胞状态,LSTM图中还有了很多奇怪的结构,这些结构一般称之为门控结构(Gate)。LSTM在在每个序列索引位置t的门一般包括遗忘门,输入门和输出门三种。下面我们就来研究上图中LSTM的遗忘门,输入门和输出门以及细胞状态。
-
遗忘门:是控制是否遗忘的,在LSTM中即以一定的概率控制是否遗忘上一层的隐藏细胞状态。遗忘门子结构如下图所示:


-
输入门:负责处理当前序列位置的输入,它的子结构如下图:
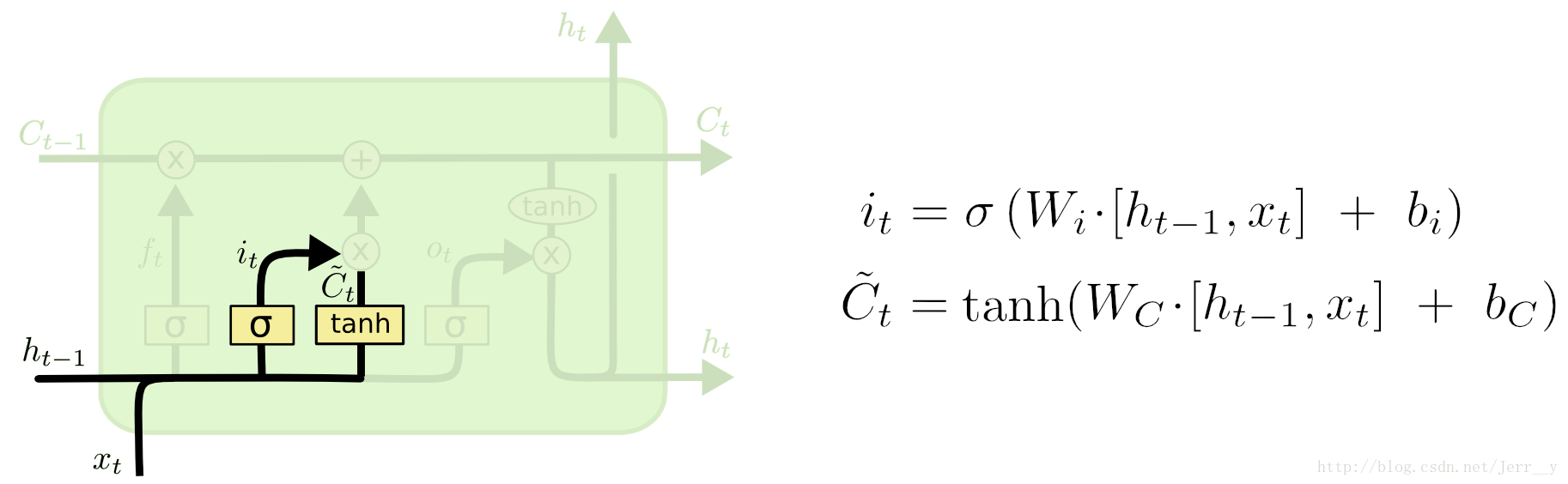

LSTM之细胞状态更新:
在研究LSTM输出门之前,我们要先看看LSTM之细胞状态。前面的遗忘门和输入门的结果都会作用于细胞状态C(t)。我们来看看从细胞状态C(t−1)如何得到C(t)。如下图所示:
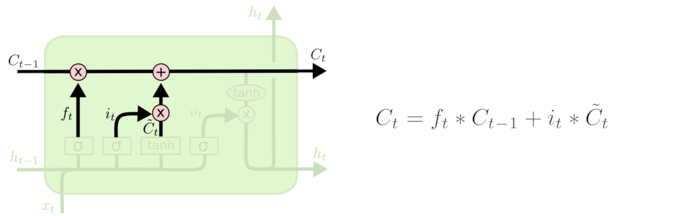
我们把旧状态与ft相乘,丢弃掉我们确定需要丢弃的信息。接着加上it∗Ct~。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。

-
输出门:有了新的隐藏细胞状态C(t),我们就可以来看输出门了,子结构如下:


三、LSTM的前向传播
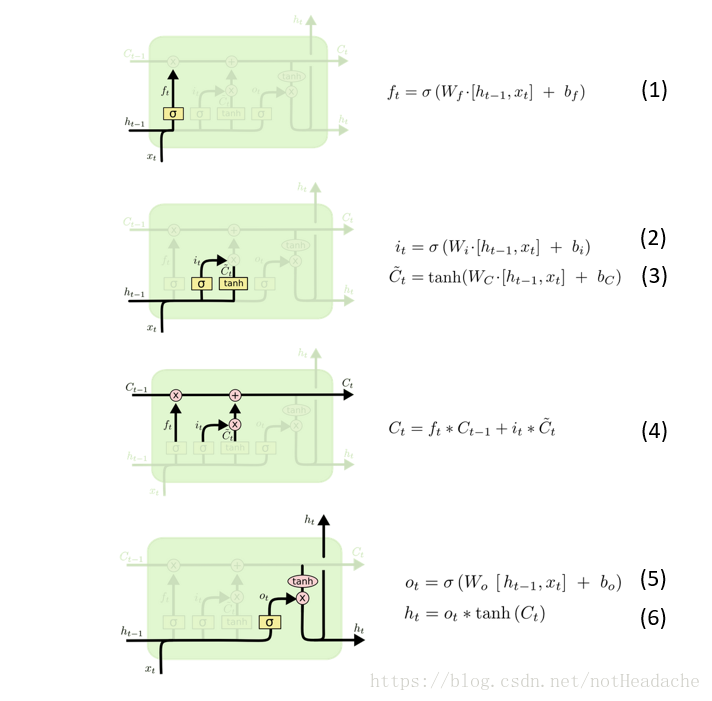

四、LSTM反向传播算法



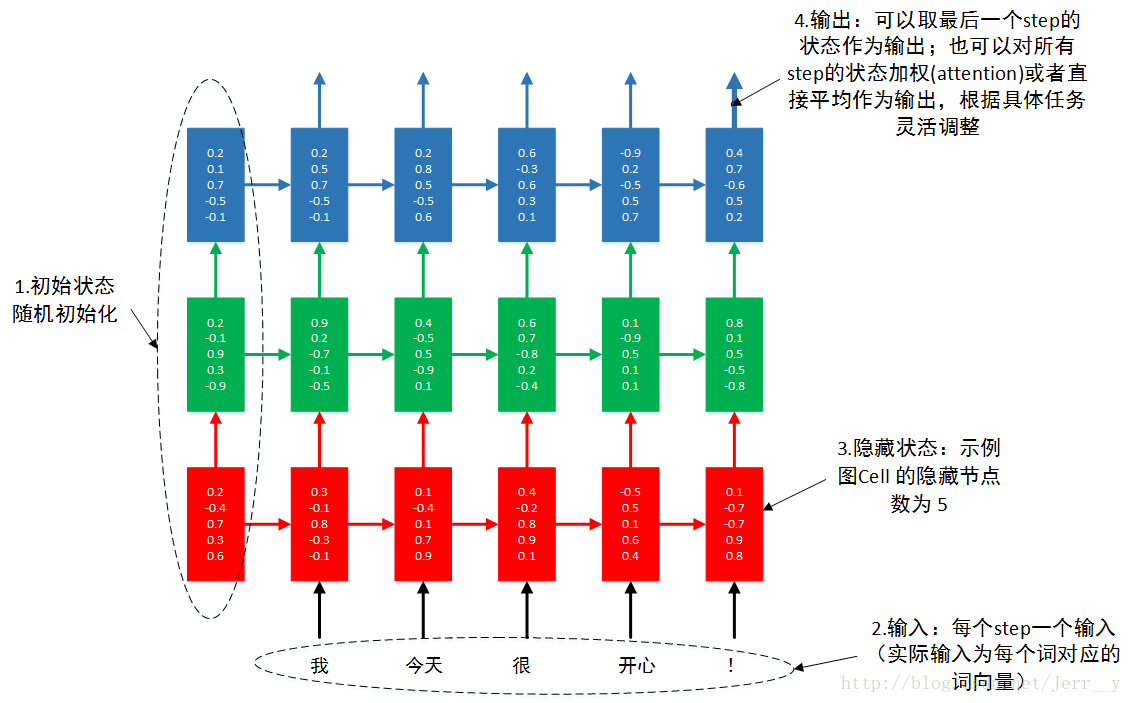
总结:
五、简单的LSTM代码实现:
# 定义一个 LSTM 结构,LSTM 中使用的变量会在该函数中自动被声明 lstm = tf.contrib.rnn.BasicLSTMCell(lstm_hidden_size) # 将 LSTM 中的状态初始化为全 0 数组,batch_size 给出一个 batch 的大小 state = lstm.zero_state(batch_size, tf.float32) # 定义损失函数 loss = 0.0 # num_steps 表示最大的序列长度 for i in range(num_steps): # 在第一个时刻声明 LSTM 结构中使用的变量,在之后的时刻都需要服用之前定义好的变量 if i>0: tf.get_variable_scope().reuse_variables() # 每一步处理时间序列中的一个时刻。将当前输入(current_input)和前一时刻状态(state)传入定义的 LSTM 结构就可以得到当前 LSTM 结构的输出 lstm_output 和更新后的状态 state lstm_output, state = lstm(current_input, state) # 将当前时刻 LSTM 结构的输出传入一个全连接层得到最后的输出 final_output = fully_connected(lstm_output) # 计算当前时刻输出的损失 loss += calc_loss(final_output, expected_output)