文章发表在KDD 2018 Research Track上,链接为Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts。
一、摘要
多任务学习可被用在许多应用上,如推荐系统。如在电影推荐中,用户可购买和喜欢观看偏好的电影,故可同时预测用户购买量以及对电影的打分。
多任务学习常对任务之间的相关性较敏感,故权衡任务之间的目标以及任务内部关系十分重要。
MMOE模型可用来学习任务之间的关系,本文采用MOE(专家模型)在多个任务之间通过共享专家子网络来进行多任务学习,其中设置一个门结构来训练优化每个任务。
二、引言
- 许多基于DNN的多任务学习存在着对数据分布不平衡、任务相关性等问题,内在的任务差异冲突会损害一些任务的预测。
- 也有一些论文提出新的建模技术来处理多任务学习中的任务差异,但技术常设计为每个模型增加更多模型参数,导致计算开销变大。
- MMOE:学习任务之间的关系,学习特定任务功能,自动分配参数捕获共享任务信息或特定任务信息,避免每次添加新参数。
多任务模型通过学习不同任务的联系和差异,可提高每个任务的学习效率和质量。
(1)多任务学习的的框架广泛采用shared-bottom的结构,不同任务间共用底部的隐层。
这种结构本质上可以减少过拟合的风险,但是效果上可能受到任务差异和数据分布带来的影响。
(2)也有一些其他结构,比如两个任务的参数不共用,但是通过对不同任务的参数增加L2范数的限制;也有一些对每个任务分别学习一套隐层然后学习所有隐层的组合。
和shared-bottom结构相比,这些模型对增加了针对任务的特定参数,在任务差异会影响公共参数的情况下对最终效果有提升。
缺点就是模型增加了参数量所以需要更大的数据量来训练模型,而且模型更复杂并不利于在真实生产环境中实际部署使用。
因此,论文中提出了一个Multi-gate Mixture-of-Experts(MMoE)的多任务学习结构。MMoE模型刻画了任务相关性,基于共享表示来学习特定任务的函数,避免了明显增加参数的缺点。
MMoE模型的结构(下图c)基于广泛使用的Shared-Bottom结构(下图a)和MoE结构,其中图(b)是图(c)的一种特殊情况。
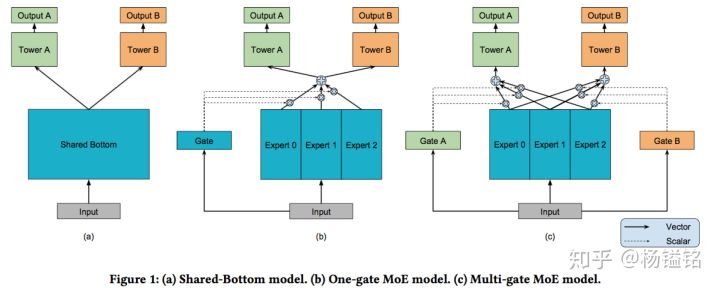
三、一般的多任务学习模型
1、框架:
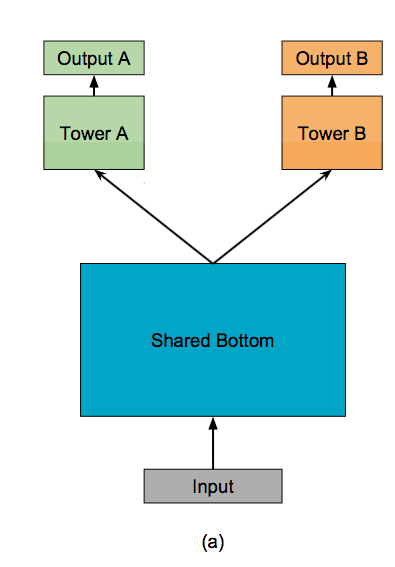
如上图a所示,shared-bottom网络(表示为函数f)位于底部,多个任务共用这一层。往上,K个子任务分别对应一个tower network(表示为 ),每个子任务的输出
。
2、任务相关性实验
接下来,我们通过一个实验来探讨任务相关性和多任务学习效果的关系。
假设模型中包含两个回归任务,而数据通过采样生成,并且规定输入相同,输出label不同。那么任务的相关性就使用label之间的皮尔逊相关系数来表示,相关系数越大,表示任务之间越相关,数据生成的过程如下:

首先,生成了两个垂直的单位向量u1和u2,并根据两个单位向量生成了模型的系数w1和w2,如上图中的第二步。w1和w2之间的cosine距离即为p,大伙可以根据cosine的计算公式得到。
随后基于正态分布的到输入数据x,而y根据下面的两个式子的到:

注意,这里x和y之间并非线性的关系,因为模型的第二步是多个sin函数,因此label之间的皮尔逊相关系数和参数w1和w2之间的cosine距离并不相等,但是呈现出一个正相关的关系,如下图:

因此,本文中使用参数的cosine距离来近似表示任务之间的相关性。
3、实验结果
基于上述数据生成过程以及任务相关性的表示方法,分别测试任务相关性在0.5、0.9和1时的多任务学习模型的效果,如下图:

可以看到的是,随着任务相关性的提升,模型的loss越小,效果越好,从而印证了前面的猜想。
四、MMOE模型
1、MOE模型
先来看一下Mixture-of-Experts (MoE)模型(文中后面称作 One-gate Mixture-of-Experts (OMoE)),如下图所示:
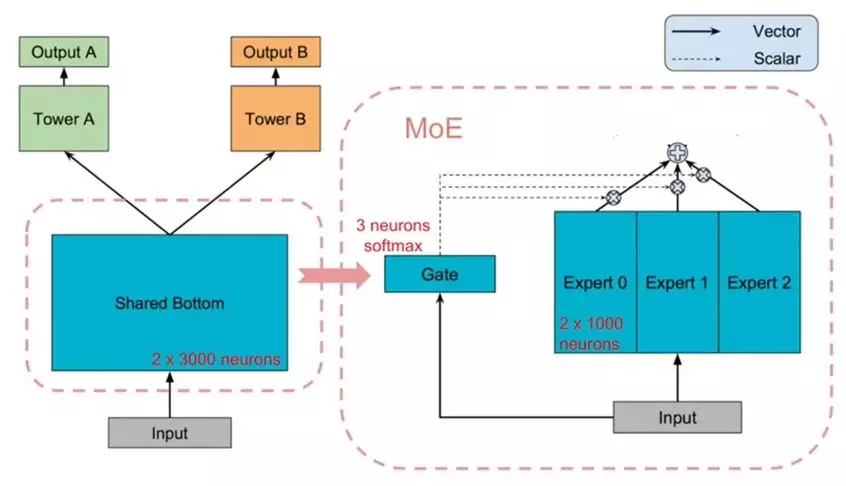
可以看到,相较于一般的多任务学习框架,共享的底层分为了多个expert,同时设置了一个Gate,使不同的数据可以多样化的使用共享层。此时共享层的输出可以表示为:

其中fi代表第i个expert的输出, 是n个expert network(expert network可认为是一个神经网络),gi代表第第i个expert对应的权重,是基于输入数据得到的,计算公式为g(x) = softmax(Wgx),其中
。g是组合experts结果的gating network,具体来说g产生n个experts上的概率分布,最终的输出是所有experts的带权加和。显然,MoE可看做基于多个独立模型的集成方法。
后面有些文章将MoE作为一个基本的组成单元,将多个MoE结构堆叠在一个大网络中。比如一个MoE层可以接受上一层MoE层的输出作为输入,其输出作为下一层的输入使用。
2、 MMoE模型
文章提出的模型(简称MMoE)目的就是相对于shared-bottom结构不明显增加模型参数的要求下捕捉任务的不同。其核心思想是将shared-bottom网络中的函数f替换成MoE层
相较于MoE模型,Multi-gate Mixture-of-Experts (MMoE)模型为每一个task设置了一个gate,使不同的任务和不同的数据可以多样化的使用共享层,模型结构如下:

此时每个任务的共享层的输出不同,第k个任务的共享层输出计算公式如下:

随后每个任务对应的共享层输出,经过多层全连接神经网络得到每个任务的输出:

从直观上考虑,如果两个任务并不十分相关,那么经过Gate之后,二者得到的权重系数会差别比较大,从而可以利用部分expert网络输出的信息,近似于多个单任务学习模型。如果两个任务紧密相关,那么经过Gate得到的权重分布应该相差不多,类似于一般的多任务学习框架。
相对于所有任务公共一个门控网络(One-gate MoE model,如上图b),这里MMoE(上图c)中每个任务使用单独的gating networks。每个任务的gating networks通过最终输出权重不同实现对experts的选择性利用。不同任务的gating networks可以学习到不同的组合experts的模式,因此模型考虑到了捕捉到任务的相关性和区别。
网络中export是切分的子网络,实现的时候其实可以看做是三维tensor,形状为:
dim of input feature * number of units per expert * number of experts
更新时是对这个三维tensor进行更新。
gate的形状则为:
dim of input feature * number of experts * number of tasks
然后一点网络中的小小小details,贴在这里可以参考一下,帮助理解:
f_{i}(x) = activation(W_{i} * x + b), where activation is ReLU according to the paper
g^{k}(x) = activation(W_{gk} * x + b), where activation is softmax according to the paper
f^{k}(x) = sum_{i=1}^{n}(g^{k}(x)_{i} * f_{i}(x))
五、实验结果
1 人工合成数据集
下图是实验结果,OMoE是单门MoE。可以看到在相关性强的数据上,OMoE和MMoE差别不大,但是在相关性低的数据上,MMoE胜过其他两个方法很多。
2、UCI census-income dataset
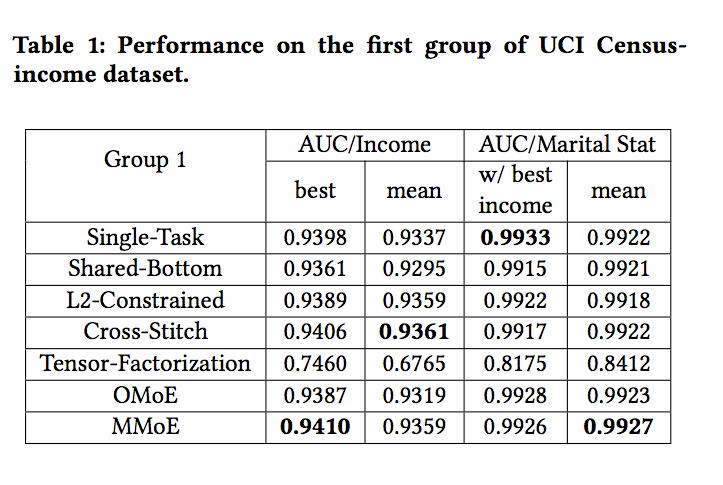
3、Large-scale Content Recommendation

六、主要代码
1、导包
import pandas as pd from keras.utils import to_categorical from keras import backend as K from keras.optimizers import Adam from keras.initializers import VarianceScaling from keras.layers import Input, Dense from keras.models import Model from keras.callbacks import Callback from sklearn.metrics import roc_auc_score import numpy as np import random import tensorflow as tf from mmoe import MMoE #模型代码 SEED = 1 # Fix numpy seed for reproducibility np.random.seed(SEED) # Fix random seed for reproducibility random.seed(SEED) # Fix TensorFlow graph-level seed for reproducibility tf.set_random_seed(SEED) #设置tensorflow的session
2、加载数据---1994年income数据
column_names = ['age', 'class_worker', 'det_ind_code', 'det_occ_code', 'education', 'wage_per_hour', 'hs_college', 'marital_stat', 'major_ind_code', 'major_occ_code', 'race', 'hisp_origin', 'sex', 'union_member', 'unemp_reason', 'full_or_part_emp', 'capital_gains', 'capital_losses', 'stock_dividends', 'tax_filer_stat', 'region_prev_res', 'state_prev_res', 'det_hh_fam_stat', 'det_hh_summ', 'instance_weight', 'mig_chg_msa', 'mig_chg_reg', 'mig_move_reg', 'mig_same', 'mig_prev_sunbelt', 'num_emp', 'fam_under_18', 'country_father', 'country_mother', 'country_self', 'citizenship', 'own_or_self', 'vet_question', 'vet_benefits', 'weeks_worked', 'year', 'income_50k'] # Load the dataset in Pandas train_df = pd.read_csv( 'data/census-income.data.gz', delimiter=',', header=None, index_col=None, names=column_names ) other_df = pd.read_csv( 'data/census-income.test.gz', delimiter=',', header=None, index_col=None, names=column_names )
切分feature和label
label_columns = ['income_50k', 'marital_stat'] # One-hot encoding categorical columns categorical_columns = ['class_worker', 'det_ind_code', 'det_occ_code', 'education', 'hs_college', 'major_ind_code', 'major_occ_code', 'race', 'hisp_origin', 'sex', 'union_member', 'unemp_reason', 'full_or_part_emp', 'tax_filer_stat', 'region_prev_res', 'state_prev_res', 'det_hh_fam_stat', 'det_hh_summ', 'mig_chg_msa', 'mig_chg_reg', 'mig_move_reg', 'mig_same', 'mig_prev_sunbelt', 'fam_under_18', 'country_father', 'country_mother', 'country_self', 'citizenship', 'vet_question'] train_raw_labels = train_df[label_columns] other_raw_labels = other_df[label_columns] transformed_train = pd.get_dummies(train_df.drop(label_columns, axis=1), columns=categorical_columns) transformed_other = pd.get_dummies(other_df.drop(label_columns, axis=1), columns=categorical_columns)
打标签
transformed_other['det_hh_fam_stat_ Grandchild <18 ever marr not in subfamily'] = 0 # One-hot encoding categorical labels train_income = to_categorical((train_raw_labels.income_50k == ' 50000+.').astype(int), num_classes=2) # > 5000的为1, < 5000为0 train_marital = to_categorical((train_raw_labels.marital_stat == ' Never married').astype(int), num_classes=2) ## Never married为1, married为0
other_income = to_categorical((other_raw_labels.income_50k == ' 50000+.').astype(int), num_classes=2)
other_marital = to_categorical((other_raw_labels.marital_stat == ' Never married').astype(int), num_classes=2)
dict_outputs = { 'income': train_income.shape[1], 'marital': train_marital.shape[1] } ## dict_outputs = {'income' : 2, 'marital' : 2}
dict_train_labels = { 'income': train_income, 'marital': train_marital }
dict_other_labels = { 'income': other_income, 'marital': other_marital }
output_info = [(dict_outputs[key], key) for key in sorted(dict_outputs.keys())] ## output_info = [(2, 'income'), (2, 'marital')]
切分验证集和测试集、训练集
# Split the other dataset into 1:1 validation to test according to the paper validation_indices = transformed_other.sample(frac=0.5, replace=False, random_state=SEED).index test_indices = list(set(transformed_other.index) - set(validation_indices)) validation_data = transformed_other.iloc[validation_indices] validation_label = [dict_other_labels[key][validation_indices] for key in sorted(dict_other_labels.keys())] test_data = transformed_other.iloc[test_indices] test_label = [dict_other_labels[key][test_indices] for key in sorted(dict_other_labels.keys())] train_data = transformed_train train_label = [dict_train_labels[key] for key in sorted(dict_train_labels.keys())] num_features = train_data.shape[1] print('Training data shape = {}'.format(train_data.shape)) print('Validation data shape = {}'.format(validation_data.shape)) print('Test data shape = {}'.format(test_data.shape)) ############ # Training data shape = (199523, 499) # Validation data shape = (49881, 499) # Test data shape = (49881, 499)
3、 模型构建
输入层
input_layer = Input(shape=(num_features,))
MMOE层
mmoe_layers = MMoE( units=4, num_experts=8, num_tasks=2 )(input_layer)
output_layers = []
MMOE代码类:
from keras import backend as K from keras import activations, initializers, regularizers, constraints from keras.engine.topology import Layer, InputSpec class MMoE(Layer): """ Multi-gate Mixture-of-Experts model. """ def __init__(self, units, num_experts, num_tasks, use_expert_bias=True, use_gate_bias=True, expert_activation='relu', gate_activation='softmax', expert_bias_initializer='zeros', gate_bias_initializer='zeros', expert_bias_regularizer=None, gate_bias_regularizer=None, expert_bias_constraint=None, gate_bias_constraint=None, expert_kernel_initializer='VarianceScaling', gate_kernel_initializer='VarianceScaling', expert_kernel_regularizer=None, gate_kernel_regularizer=None, expert_kernel_constraint=None, gate_kernel_constraint=None, activity_regularizer=None, **kwargs): """ Method for instantiating MMoE layer. :param units: Number of hidden units :param num_experts: Number of experts :param num_tasks: Number of tasks :param use_expert_bias: Boolean to indicate the usage of bias in the expert weights :param use_gate_bias: Boolean to indicate the usage of bias in the gate weights :param expert_activation: Activation function of the expert weights :param gate_activation: Activation function of the gate weights :param expert_bias_initializer: Initializer for the expert bias :param gate_bias_initializer: Initializer for the gate bias :param expert_bias_regularizer: Regularizer for the expert bias :param gate_bias_regularizer: Regularizer for the gate bias :param expert_bias_constraint: Constraint for the expert bias :param gate_bias_constraint: Constraint for the gate bias :param expert_kernel_initializer: Initializer for the expert weights :param gate_kernel_initializer: Initializer for the gate weights :param expert_kernel_regularizer: Regularizer for the expert weights :param gate_kernel_regularizer: Regularizer for the gate weights :param expert_kernel_constraint: Constraint for the expert weights :param gate_kernel_constraint: Constraint for the gate weights :param activity_regularizer: Regularizer for the activity :param kwargs: Additional keyword arguments for the Layer class """ # Hidden nodes parameter self.units = units self.num_experts = num_experts self.num_tasks = num_tasks # Weight parameter self.expert_kernels = None self.gate_kernels = None self.expert_kernel_initializer = initializers.get(expert_kernel_initializer) self.gate_kernel_initializer = initializers.get(gate_kernel_initializer) self.expert_kernel_regularizer = regularizers.get(expert_kernel_regularizer) self.gate_kernel_regularizer = regularizers.get(gate_kernel_regularizer) self.expert_kernel_constraint = constraints.get(expert_kernel_constraint) self.gate_kernel_constraint = constraints.get(gate_kernel_constraint) # Activation parameter self.expert_activation = activations.get(expert_activation) self.gate_activation = activations.get(gate_activation) # Bias parameter self.expert_bias = None self.gate_bias = None self.use_expert_bias = use_expert_bias self.use_gate_bias = use_gate_bias self.expert_bias_initializer = initializers.get(expert_bias_initializer) self.gate_bias_initializer = initializers.get(gate_bias_initializer) self.expert_bias_regularizer = regularizers.get(expert_bias_regularizer) self.gate_bias_regularizer = regularizers.get(gate_bias_regularizer) self.expert_bias_constraint = constraints.get(expert_bias_constraint) self.gate_bias_constraint = constraints.get(gate_bias_constraint) # Activity parameter self.activity_regularizer = regularizers.get(activity_regularizer) # Keras parameter self.input_spec = InputSpec(min_ndim=2) self.supports_masking = True super(MMoE, self).__init__(**kwargs) def build(self, input_shape): """ Method for creating the layer weights. :param input_shape: Keras tensor (future input to layer) or list/tuple of Keras tensors to reference for weight shape computations """ assert input_shape is not None and len(input_shape) >= 2 input_dimension = input_shape[-1] # Initialize expert weights (number of input features * number of units per expert * number of experts) self.expert_kernels = self.add_weight( name='expert_kernel', shape=(input_dimension, self.units, self.num_experts), initializer=self.expert_kernel_initializer, regularizer=self.expert_kernel_regularizer, constraint=self.expert_kernel_constraint, ) # Initialize expert bias (number of units per expert * number of experts) if self.use_expert_bias: self.expert_bias = self.add_weight( name='expert_bias', shape=(self.units, self.num_experts), initializer=self.expert_bias_initializer, regularizer=self.expert_bias_regularizer, constraint=self.expert_bias_constraint, ) # Initialize gate weights (number of input features * number of experts * number of tasks) self.gate_kernels = [self.add_weight( name='gate_kernel_task_{}'.format(i), shape=(input_dimension, self.num_experts), initializer=self.gate_kernel_initializer, regularizer=self.gate_kernel_regularizer, constraint=self.gate_kernel_constraint ) for i in range(self.num_tasks)] # Initialize gate bias (number of experts * number of tasks) if self.use_gate_bias: self.gate_bias = [self.add_weight( name='gate_bias_task_{}'.format(i), shape=(self.num_experts,), initializer=self.gate_bias_initializer, regularizer=self.gate_bias_regularizer, constraint=self.gate_bias_constraint ) for i in range(self.num_tasks)] self.input_spec = InputSpec(min_ndim=2, axes={-1: input_dimension}) super(MMoE, self).build(input_shape) def call(self, inputs, **kwargs): """ Method for the forward function of the layer. :param inputs: Input tensor :param kwargs: Additional keyword arguments for the base method :return: A tensor """ gate_outputs = [] final_outputs = [] # f_{i}(x) = activation(W_{i} * x + b), where activation is ReLU according to the paper, expert_outputs = {batch_size, units per experts, numbers of experts} expert_outputs = K.tf.tensordot(a=inputs, b=self.expert_kernels, axes=1) # Add the bias term to the expert weights if necessary if self.use_expert_bias: expert_outputs = K.bias_add(x=expert_outputs, bias=self.expert_bias) expert_outputs = self.expert_activation(expert_outputs) # g^{k}(x) = activation(W_{gk} * x + b), where activation is softmax according to the paper, gate_output = { batch_size , 1} for index, gate_kernel in enumerate(self.gate_kernels): gate_output = K.dot(x=inputs, y=gate_kernel) # Add the bias term to the gate weights if necessary if self.use_gate_bias: gate_output = K.bias_add(x=gate_output, bias=self.gate_bias[index]) gate_output = self.gate_activation(gate_output) gate_outputs.append(gate_output) # f^{k}(x) = sum_{i=1}^{n}(g^{k}(x)_{i} * f_{i}(x)) for gate_output in gate_outputs: expanded_gate_output = K.expand_dims(gate_output, axis=1) weighted_expert_output = expert_outputs * K.repeat_elements(expanded_gate_output, self.units, axis=1) final_outputs.append(K.sum(weighted_expert_output, axis=2)) return final_outputs def compute_output_shape(self, input_shape): """ Method for computing the output shape of the MMoE layer. :param input_shape: Shape tuple (tuple of integers) :return: List of input shape tuple where the size of the list is equal to the number of tasks """ assert input_shape is not None and len(input_shape) >= 2 output_shape = list(input_shape) output_shape[-1] = self.units output_shape = tuple(output_shape) return [output_shape for _ in range(self.num_tasks)] def get_config(self): """ Method for returning the configuration of the MMoE layer. :return: Config dictionary """ config = { 'units': self.units, 'num_experts': self.num_experts, 'num_tasks': self.num_tasks, 'use_expert_bias': self.use_expert_bias, 'use_gate_bias': self.use_gate_bias, 'expert_activation': activations.serialize(self.expert_activation), 'gate_activation': activations.serialize(self.gate_activation), 'expert_bias_initializer': initializers.serialize(self.expert_bias_initializer), 'gate_bias_initializer': initializers.serialize(self.gate_bias_initializer), 'expert_bias_regularizer': regularizers.serialize(self.expert_bias_regularizer), 'gate_bias_regularizer': regularizers.serialize(self.gate_bias_regularizer), 'expert_bias_constraint': constraints.serialize(self.expert_bias_constraint), 'gate_bias_constraint': constraints.serialize(self.gate_bias_constraint), 'expert_kernel_initializer': initializers.serialize(self.expert_kernel_initializer), 'gate_kernel_initializer': initializers.serialize(self.gate_kernel_initializer), 'expert_kernel_regularizer': regularizers.serialize(self.expert_kernel_regularizer), 'gate_kernel_regularizer': regularizers.serialize(self.gate_kernel_regularizer), 'expert_kernel_constraint': constraints.serialize(self.expert_kernel_constraint), 'gate_kernel_constraint': constraints.serialize(self.gate_kernel_constraint), 'activity_regularizer': regularizers.serialize(self.activity_regularizer) } base_config = super(MMoE, self).get_config() return dict(list(base_config.items()) + list(config.items()))
输出层(tower layer)
# Build tower layer from MMoE layer for index, task_layer in enumerate(mmoe_layers): tower_layer = Dense( units=8, activation='relu', kernel_initializer=VarianceScaling())(task_layer) output_layer = Dense( units=output_info[index][0], name=output_info[index][1], activation='softmax', kernel_initializer=VarianceScaling())(tower_layer) output_layers.append(output_layer)
4、模型训练
model = Model(inputs=[input_layer], outputs=output_layers) adam_optimizer = Adam() model.compile( loss={'income':'binary_crossentropy'}, optimizer=adam_optimizer, metrics=['accuracy'] ) # Print out model architecture summary model.summary() # Train the model model.fit( x=train_data, y=train_label, validation_data=(validation_data, validation_label), callbacks=[ ROCCallback( training_data=(train_data, train_label), validation_data=(validation_data, validation_label), test_data=(test_data, test_label) ) ], epochs=100 )
参考文献:
https://zhuanlan.zhihu.com/p/55752344
https://zhuanlan.zhihu.com/p/96796043
多任务学习模型详解:Multi-gate Mixture-of-Experts(MMoE ,Google,KDD2018)
MMOE论文笔记(论文中有维度讲解)