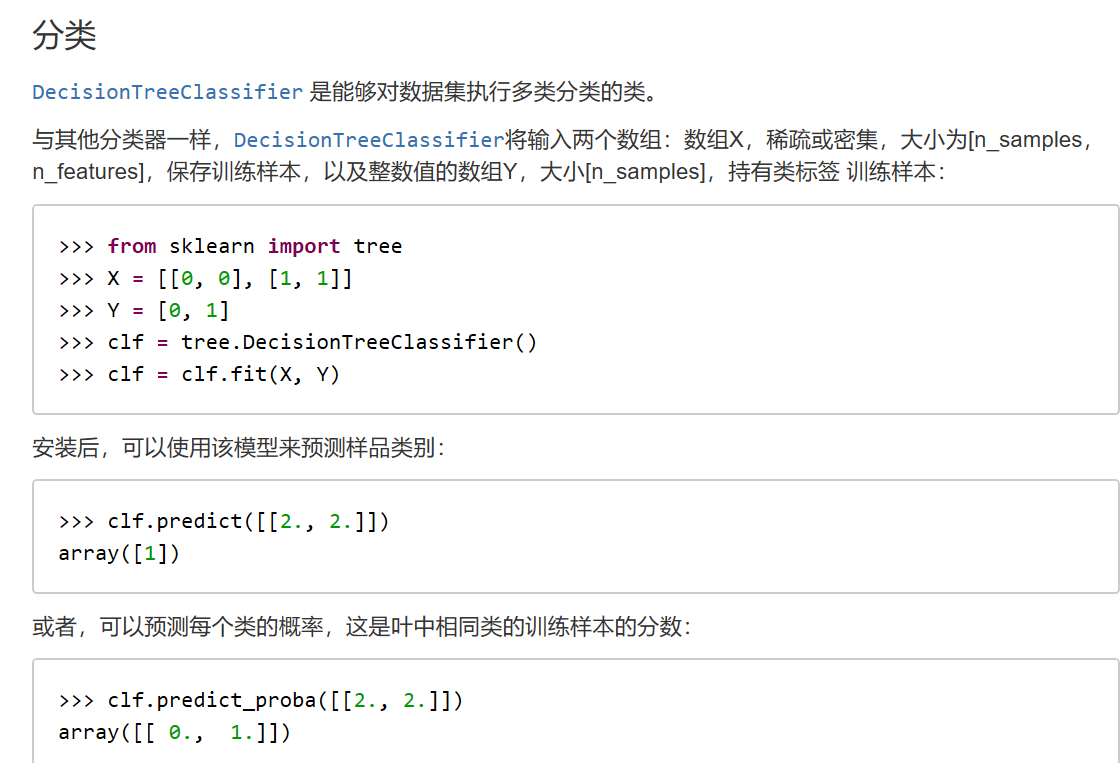
1、使用示例
2、树模型参数:【很多参数都是用来限制树过于庞大,即担心其过拟合】
# 1.criterion gini or entropy:用什么作为衡量标准 ( 熵值或者Gini系数 )。
# 2.splitter best or random 前者是在所有特征中找最好的切分点 后者是在部分特征中(数据量大的时候)【当特征过大时,从头开始遍历会过慢,一般选默认值best)】
# 3.max_features int or None(所有),optional(default=None) , log2,sqrt,N 特征小于50的时候一般使用所有的 【通常使用默认值None】
# 4.max_depth int or None:默认值为None。数据少或者特征少的时候可以不管这个值,如果模型样本量多,特征也多的情况下,可以尝试限制下树的深度
# 5.min_samples_split 如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分,如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。
# 6.min_samples_leaf 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝,如果样本量不大,不需要管这个值,大些如10W可是尝试下5
# 7.min_weight_fraction_leaf 这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝默认是0,就是不考虑权重问题。一般来说,如果我们有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们就要注意这个值了。
# 8.max_leaf_nodes 通过限制最大叶子节点数,可以防止过拟合,默认是"None”,即不限制最大的叶子节点数。 如果加了限制,算法会建立在最大叶子节点数内最优的决策树。如果特征不多,可以不考虑这个值,但是如果特征分成多的话,可以加以限制,具体的值可以通过交叉验证得到。
# 9.class_weight 指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多, 导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重。如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。
# 10.min_impurity_split 这个值限制了决策树的增长,如果某节点的不纯度,(基尼系数,信息增益,均方差,绝对差)小于这个阈值。则该节点不再生成子节点。即为叶子节点 。