摘自https://mp.weixin.qq.com/s?__biz=MzIwMTc4ODE0Mw==&mid=2247486960&idx=1&sn=1b4b9d7ec7a9f40fa8a9df6b6f53bbfb&chksm=96e9d270a19e5b668875392da1d1aaa28ffd0af17d44f7ee81c2754c78cc35edf2e35be2c6a1&scene=21#wechat_redirect
一、Attention最初定义:
Attention 也是一个编码序列的方案,因此我们也可以认为它跟 RNN、CNN 一样,都是一个序列编码的层。下图是attention一般化的框架形式的描述。
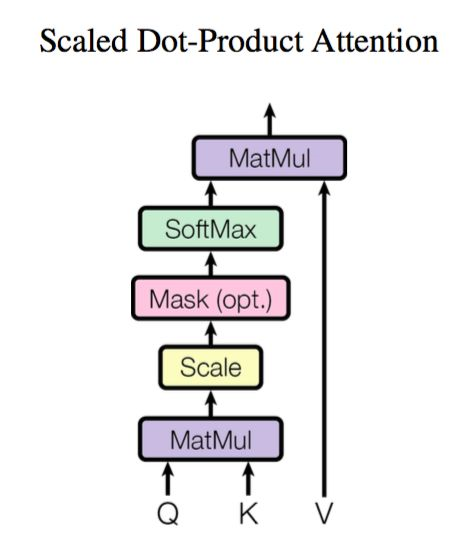
公式定义:

![]()
如果忽略激活函数 softmax 的话,那么事实上它就是三个 n×dk,dk×m,m×dv 的矩阵相乘,最后的结果就是一个 n×dv 的矩阵。softmax作用是归一化。
于是我们可以认为:这是一个 Attention 层,将 n×dk 的序列 Q 编码成了一个新的 n×dv 的序列。
更具体一点:(即展开上面式子,逐个向量来看)
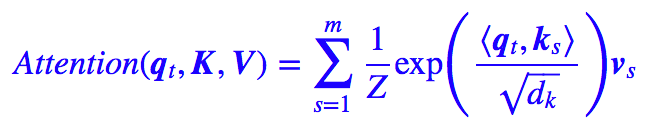
其中 Z 是归一化因子。事实上 q,k,v 分别是 query,key,value 的简写,K,V 是一一对应的,它们就像是 key-value 的关系,那么上式的意思就是通过 qt 这个 query,通过与各个 ks 内积的并 softmax 的方式,来得到 qt 与各个 vs 的相似度,然后加权求和,得到一个 dv 维的向量。
其中因子根号dk起到调节作用,使得内积不至于太大(太大的话 softmax 后就非 0 即 1 了,不够“soft”了)。
二、Attention另外定义:

二、自注意力:
所谓 Self Attention,其实就是 Attention(X,X,X),X 就是前面说的输入序列。也就是说,在序列内部做 Attention,寻找序列内部的联系。