2017-2018-1 20155216 《信息安全系统设计基础》第十四周学习总结
第三章:程序的机器级表示
教材学习内容总结
历史观点
Intel处理器系列俗称x86,开始时是第一代单芯片、16位微处理器之一。
每个后继处理器的设计都是后向兼容的——较早版本上编译的代码可以在较新的处理器上运行。
X86 寻址方式经历三代:
1 DOS时代的平坦模式,不区分用户空间和内核空间,很不安全
2 8086的分段模式
3 IA32的带保护模式的平坦模式
c语言代码、汇编代码、机器代码之间的关系
1、C预处理器扩展源代码,展开所以的#include命名的指定文件;
2、编译器产生汇编代码(.s);
3、汇编器将汇编代码转化成二进制目标文件(.o)
机器级代码:x86主要寄存器
程序计数器(32位,%eip):PC
整数寄存器/通用寄存器(32位,8个,%eax,%ebx,%ecx,%edx,%esi,%edi,%ebp,%esp):存储地址(C指针)或整数数据。有的存储程序重要状态,%esp栈指针(栈顶),%ebp帧指针(当前帧底)。
条件码寄存器(32位, EFLAGS):状态标志,控制标志和系统标志。
段寄存器(16位, 6个)
浮点寄存器(8个,%st(0-7)):存储浮点数据
其它寄存器包括:控制寄存器(CR0-CR4),GDTR,IDTR,TR,LDTR,调试寄存器(DR0-DR7),内存类型范围寄存器MTRR,MSR,MCR,PMC等等。
通用寄存器
%eax 操作数运算
%ebx 指向DS段中数据的指针
%ecx 字符串操作和循环计数器
%edx 输入输出指针
%esi 指向DS段中数据的指针或字符串操作中字符串的复制源
%edi 指向ES段中数据的指针或字符串操作中字符串的复制地
%esp 栈指针(SS段)
%ebp 指向SS段上数据的指针
段寄存器
CS 代码段
DS 数据段
SS 堆栈段
ES 数据段
FS 数据段
GS 数据段
数据表示
对于C语言来说,它支持整型数据、浮点数据等多种采取不同编码方式的数据类型。从机器角度看,他们又是一样的,均表示为一个连续的字节序列。
根据机器的不同,数据使用的字节顺序也有所不同:
小端法:最低有效字节存储在所用字节中的最低地址。随着地址的增大,它在存储器中按照最低字节到最高字节的顺序进行存储。绝大部分Intel兼容机都是采用小端法,如Linux的IA32和x86-64机器,Windows的IA32机器
大端法:最高有效字节存储在所用字节中的最低地址。随着地址的增大,它在存储器中按照最高字节到最低字节的顺序进行存储。大多数IBM和Sun机器采用大端法,如运行Solaris的Sun Sparc处理器
可用程序来测试你的机器中类型为int、float、void *的对象字节表示和字节顺序
#include <stdio.h>
typedef unsigned char *byte_p;
void show_bytes(byte_p start,int len){
for(int i=0;i < len;i++)
printf(" %.2x",start[i]);
printf("
");
}
void show_int(int x){
show_bytes((byte_p) &x,sizeof(int));
}
void show_float(float x){
show_bytes((byte_p) &x,sizeof(float));
}
void show_pointer(void *x){
show_bytes((byte_p) &x,sizeof(void *));
}
void test3(){
int val=0x87654321;
byte_p valp=(byte_p)&val;
show_bytes(valp,4);
show_int(val);
float val1=0x4A564504; //3510593
show_float(val);
printf(" %p
",&val);
show_pointer(&val);
/**
* 21 43 65 87
* 21 43 65 87
* 7a 35 f1 ce
* 0x7fffb73c3d58
* 58 3d 3c b7 ff 7f 00 00
*/
}
int main(){
test3();
//小端法:21 43 65 87(低地址低字节序列)
//大端法:87 65 43 21(低地址高字节序列)
return 0;
}
数据访问、传送和算术运算
C声明 汇编代码后缀 大小(字节)
char b- 字节 1
short w- 字 2
int l- 双字 4
long l- 双字 4
long long - 8
void * l- 双字 4
float s- 单精度 4
double l- 双精度 8
long double t- 扩展精度 10/12
寻址模式与数据访问

这组IA32整数寄存器,有些可以存储C语言中的指针和整数数据,有些用来记录某些重要的程序状态,而有些用来保存临时数据如局部变量和函数的返回值
所有的8个寄存器都可以作为一个字(16位)或32个字(双字)来访问。并且可以独立访问前4个寄存器的两个低位字节
过程处理中%eax %ecx %edx的保存和恢复不同于接下来的三个寄存器%ebx %esi %edi
堆栈管理中%ebp表示帧指针,%esp表示栈指针。 运行时,栈指针可以移动,因而信息的访问都是相对于帧指针的
在机器指令中这些存储的数据通常称为操作数,它指出执行一个操作中要引用的源数据值,以及放置结果的目标位置。源数据值可以以立即数或从寄存器或存储器中读出,结果可以存放在寄存器或存储器中。
操作数有三种类型:
立即数: 书写方式为$0xFF
寄存器: 用来表示寄存器的内容。用Ea表示任意寄存器a,用引用R[Ea]表示其内容。
存储器引用:根据计算出来的有效存储器地址,访问某存储器位置。用M[Addr]表示对存储在存储器地址Addr开始的b个字节值的引用
下面是不同的数据寻址模式,它允许不同形式的存储器引用。

数据传送命令
数据传送指令主要是由MOV类指定完成,根据操作数的大小不同,把它分成: movb、movw、movl 。

MOV类的指令是将源操作数的值复制到目的操作数中。其中源操作数指定的值要么是一个立即数,要么是存储在寄存器或存储器中,目的操作数指定一个位置,要么是一个寄存器,要么是一个存储器地址。
注意传送指令的两个操作数不能都指向存储器位置,将一个值从一个存储器位置复制到另一个存储器位置需要两条指令-第一条指令由源值加载到寄存器中,第二条将该寄存器写入目的存储器位置中。
如下几个实例(第一个是源操作数,第二个是目的操作数):
movl $0x4050 %eax // 立即数的内容存储到寄存器%eax中,4个字节
movl $-17,(%esp) // 立即数的内容到存储器中,4个字节
movw %bp,%sp // 寄存器的内容复制到另一个寄存器中,2个字节
movl %eax,-12(%ebp) // 寄存器的内容到存储器中,4个字节
movb (%edi,%ecx),%ah // 存储器的内容到寄存器中,1个字节
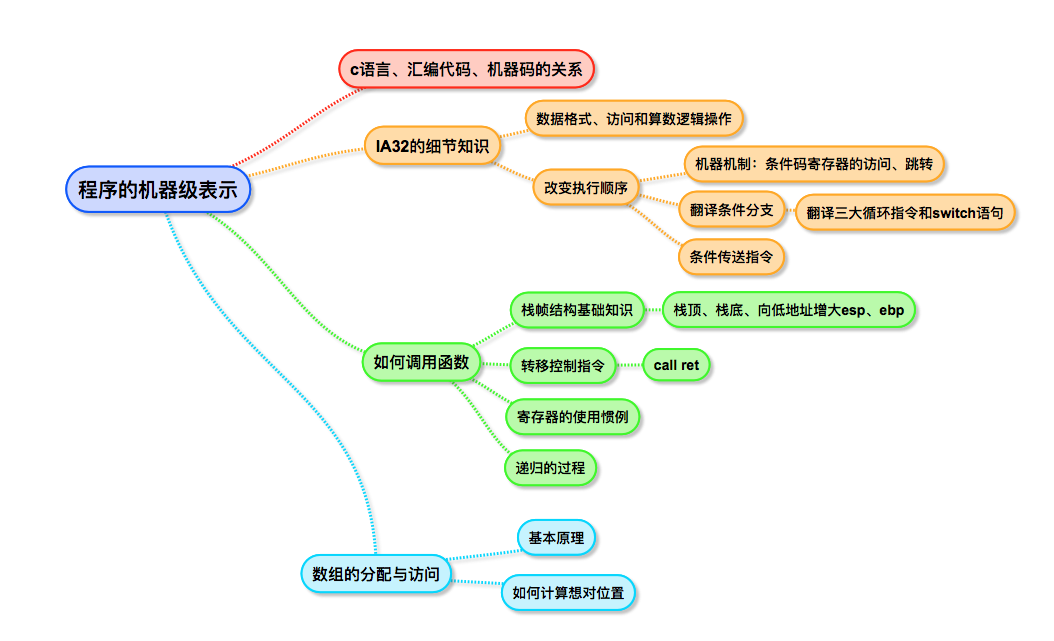
算术和逻辑操作
A. 加载有效地址
leal 7(%edx,%edx,4),%eax //设置存储器%eax的值为5x+7,%edx的值为x
leal 6(%edx),%eax //设置存储器%eax的值为x+6
B. 一元和二元操作
subl %eax,%edx //从寄存器%edx中减去%eax中
addl %ecx,4(%eax) //从寄存器%eax+4中加上%ecx中
C. 移位操作
sall $2,%eax // x << =n
sarl %c1,%eax // x >> =n
xorl %edx,%edx //等价于movl $0,%edx,但它只需要2个字节,movl需要5个字节编码
条件码和跳转指令
CPU除了提供上面的几个整数寄存器外,还维护着一组单个比特位的条件码,描述最近的算术或逻辑操作特性,用于执行条件分支指令。
CF: 进位标志,表示最近的操作使最高位产生了进位。用于检查无符号操作数的溢出
ZF: 零标志,表示最近的操作得出的结果为0
SF: 符号标志,表示最近的操作得出的结果为负数
OF: 溢出标志,表示最近的操作使补码溢出-正溢出或负溢出
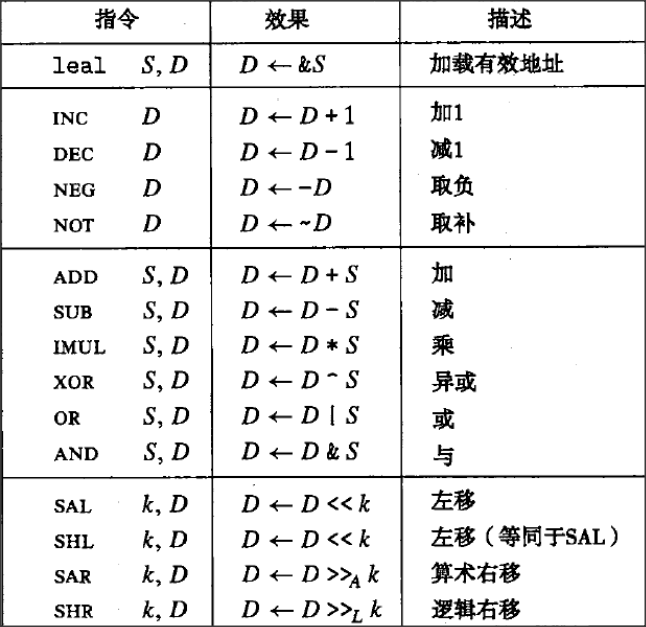
设置条件码
A. 比较和测试指令:它们只设置条件码而不改变任何其他寄存器
cmp S2,S1 通过S1-S2的结果,比较两者的大小
test S2,S1 通过S1&S2的结果(按位与),比如testl %eax,%eax用来检查%eax是正数,负数还是0或者其中一个操作数是掩码,用来指示哪些位应该被测试
B. 根据条件码的组合,使用set指令,不同后缀名表示不同条件
set指令的目的操作数是8个单字节寄存器或者存储一个字节的存储器位置,把该字节位置设置成0或1。它的基本思路是执行比较或测试指令,根据set指令的类型决定计算结果t=a-b:操作数的大小,是有符号的还是无符号的,程序值的数据类型。
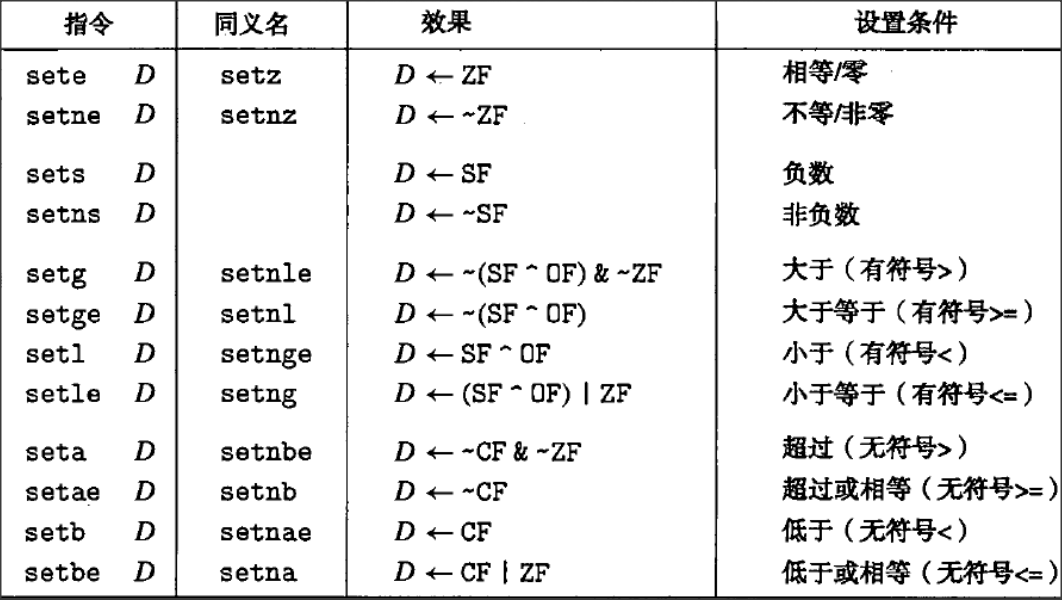
C. 跳转指令:无条件的和有条件的
所谓跳转指令是指程序执行时切换到程序中的一个带有标号的地址。跳转指令又分无条件跳转(直接跳转、间接跳转)、有条件跳转
直接跳转中,直接选择一个跳转目标,写法为".L1";间接跳转中,跳转目标是从寄存器或者存储器位置中读出的,写法为"\*+操作数指示符",如jmp *eax,用寄存器%eax的值作为跳转目标。有条件的跳转指令通常是根据条件码的某个组合,或者跳转或者继续执行代码中的下一条指令,与set指令向匹配。注意:条件跳转只能是直接跳转!
条件语句的翻译-if-else

循环语句的翻译-do-while、while、for
do-while

while

for


switch语句

栈帧结构基础

普通函数、递归函数的调用过程
考虑如下图定义的普通C函数调用,函数caller包括一个对函数swap_add的调用,并且给出了调用swap_add函数前和正在运行时的栈帧结构。注:访问的栈位置有些是相对于栈指针%esp的,有些是相对于基地址指针%ebp的,偏移量都是由相对于这两个指针的栈表示!
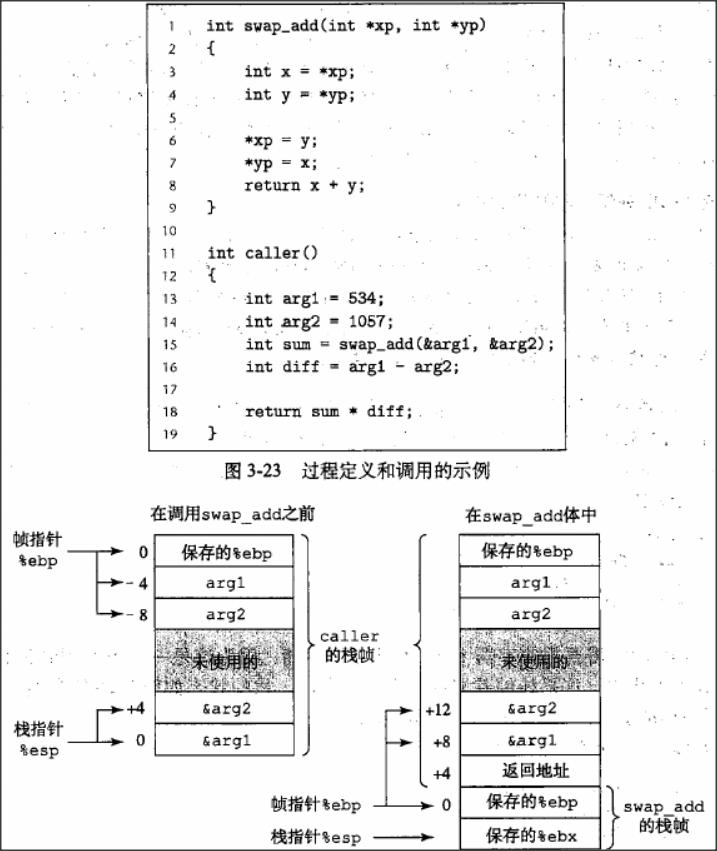
栈规则提供了一种机制,每次函数调用都有存储它自己的私有状态信息(保存的返回位置、栈指针、被调用者保存寄存器-很重要,必须先保存)
过程调用中访问信息均是相对于帧指针%ebp而言,$0x4(%ebp)表示的是返回地址,往地址增大的方向$0x8(%ebp)表示的是函数第一个参数,函数如果有多个参数,依次以4递增。本地变量和临时变量则是往地址变小的方向存储
如果在调用过程中,使用了malloc函数,需要说明的是:
一、指针变量是分配在栈上的局部变量,调用结束,该变量自动释放。但由malloc分配在堆的内存-该指针指向的堆内存却并未释放,如果不作处理,就会造成内存泄露;
二、为了防止内存泄露,有两种处理情形:作为返回值,返回那段堆内存的指针,从而不会丢失对那段内存的控制;在栈调用结束前使用free操作手动释放那段内存;
三、指针变量的内存随调用结束自动释放,指针指向的那段内存必须使用free或delete操作释放。因而明确一点的是free之后再解引用那个指针是非法的,因为访问已释放的内存地址是无效的,一般建议释放操作后主动置指针为NULL指针就不会造成误解。
数组和指针
指针,实际上是地址的一种表示方式,它指向某一个类型的对象。指针类型不是机器代码中的一部分,而是C语言提供的一种抽象。
产生指针可用&运算符,它适合于变量、结构、联合和数组的元素,我们常常用leal指令来生成存储器引用的地址。*用于指针的间接引用,它表示一个值,类型与指针的类型相关,它是通过存储器引用来实现的,要么写入数据,要么读取数据。
如下图为与整型数组E有关的表达式。它的起始地址和整数索引i分别存在寄存器%edx、%ecx中

leal指令用来创建地址,movl用来引用存储器(除了第一种和最后一种情况,前者表示复制地址,后者表示复制索引)
数组与指针是有紧密联系的。一个数组的名字既可以直接数组引用又可以像一个指针变量引用(但不能修改)。如a[3]与(a+3)有一样的效果,它均需要用对象类型的大小对偏移量进行伸缩。我们写表达式p+i,指针p的指针为p,则得到的地址计算为p+Li,L是与p相关联的数据类型大小!
指针能够从某种类型强制转换到另一种类型,只改变它的类型,而不改变它的值。所起的效果是改变指针运算的伸缩。如p是一个char类型的指针,那么表达式(int)p+7为p+28,(int*)(p+7)为p+7
对于二维数组,对应的元素的地址的汇编代码表示可以借助移位、加法和伸缩组合来避免直接的乘法工作
结构和联合、数据对齐
C语言提供两种结合不同类型的对象来创建数据类型的机制:
结构: 多个对象组合到一个单位中
联合: 允许用几种不同的类型来引用一个对象
A. 结构体
struct test {
int i;
short c;
int j;
char *p;
char s[0];
};
在结构体中,编译器记录了每个字段的字节偏移,汇编代码通过以结构体的地址加上适当的偏移放访问结构的字段。记test的起始地址为xp,,结合数据对齐的策略:
在64位机器要保证每个元素的K字节数据对齐,各元素的地址为xp、xp+4、xp+8、xp+16、xp+24
在32位机器要保证较大数据类型的4字节数据对齐,各元素的地址为xp、xp+4、xp+8、xp+12、xp+16
以32为例,记结构体类型的指针变量在寄存器%edx中,获取每个字段元素的汇编代码如下(每行代码独立):
movl (%edx),%eax 获得pt->i
movl 4(%edx),%eax 获得pt->c
movl 8(%edx),%eax 获得pt->j
leal 4(%edx),%eax + movl %eax,12(%edx) 获得&pt->c存储在pt->p
movl 16(%edx),%eax 获得pt->s
64位系统:
pt的地址: (nil)
i的地址: (nil)
c的地址: 0x4
j的地址: 0x8
p的地址: 0x10
s的地址: 0x18
32位系统:
pt的地址: (nil)
i的地址: (nil)
c的地址: 0x4
j的地址: 0x8
p的地址: 0xc
s的地址: 0x10
B. 联合类型
联合类型提供了一种方式,绕过了C语言类型系统,允许以多种类型来引用一个对象,并且它的总大小为它最大字段的大小。在某些情况下,联合十分有用
事先知道一个数据结构中的两个不同的字段是互斥的,可将这两个字段声明为联合的一部分,而不是结构的一部分,以减小分配空间的总量。
例如实现一个二叉树的数据结构,每个叶子节点都有一个double的数据,而每个内部节点都有指向两个孩子节点的指针但无数据。
C. 长度为0的数组
默认地零数组在标准C和C++是不允许的,如果使用的话编译时会产生错误。但在GNU C99中,这种用法是合法的,它最典型的用法是置于结构体中的最后一个字段,并且在前面至少有一个其他字段,因而GCC编译时不会产生任何警告或错误。我们称这个数组为柔性数组。
零长度数组定义在结构体内,但并不占用结构体的空间(可用sizeof(某结构体或者char[0])测试,可比较指针方式是否占用空间)。可理解为这是一个没有内容的占位符标识,分配了实质内容后变成了一个有长度的数组
它能够为结构体内的数据分配一段连续的内存,并可以一次性讲内存释放。对比指针,既需要释放指针指向的内存块,又需要释放结构体指针。
分配连续的内存是有利于提高访问速度,并减少了一定量的内存碎片,指针则不可。
对齐
对齐:为了提高存储性能,对象的地址必须是某个值(通常是2,4,8)的倍数。
Linux的对齐策略是2字节数据类型(short)的地址必须是2的倍数。而较大数据类型(如int,int*,float,double)的地址必须是4的倍数。
Windows要求更严格:任何k字节的基本对象的地址都必须是k的倍数。
注意编译器可能在结构末尾添加一些填充使整个结构对齐。这利于定义结构类型数组。
比如:
struct s { /* 地址示例:x为间隙 */
char c; /* bf9483e0: cx-------------- */
short s[2]; /* bf9483e2: --s0s1xx-------- */
int i; /* bf9483e8: --------iiii---- */
char d; /* bf9483ec: ------------dxxx */
};
缓冲区溢出
C对数组引用不做边界检查,同时局部变量和状态信息(寄存器值和返回指针等)都存放在栈中,这使得越界的数组写操作会破坏存储在栈中的状态信息,程序使用被破坏的状态时就会出现严重的错误。
常见的状态破坏称为缓冲区溢出,就是实际保存内容的大小超过了缓冲区大小,导致写越界。缓冲区溢出能被用来让程序执行非本意的函数,这是最常见的通过计算机网络攻击系统安全的方法。
GDB调试器
GDB支持对机器级程序的运行时评估和分析。一般先运行 objdump 来获得程序的反汇编版本,以帮助确定断点等。断点可以设置在函数入口后面,或某个地址。使用gdb 执行程序,遇到一个断点时,程序会停下来,将控制返回给用户。在断点处,可以查看各个寄存器和存储器。还可以单步跟踪程序,一次执行几条命令,或前进到下一个断点。
下面是一些常用的命令:
开始和停止
quit 退出gdb
run 运行程序(设置命令行参数)
kill 停止程序
断点
break func 设置断点在func函数入口
break *0x80483c7 设置断点在地址0x80483c7
delete 1 删除断点1
delete 删除全部断点
执行
stepi 执行一条指令
stepi n 执行n条指令
nexti 执行一条指令(可以通过子例程调用)
continue 恢复执行
finish 运行直到当前函数返回
检查代码
disas 反汇编当前函数
disas func 反汇编func函数
disas 0x80483b7 反汇编在地址0x80483b7附近的函数
disas 0x80483b7 0x80483c7 反汇编在指定地址范围的代码
print /x $eip 十六进制打印程序计数器
检查数据
print $eax 十进制打印%eax的内容
print /x $eax 十六进制打印%eax的内容
print /t $eax 二进制打印%eax的内容
print 0x100 打印0x100的二进制表示
print /x 100 打印100的十六进制表示
print /x ($ebp+8) 十六进制打印%ebp+8的内容
print *(int *) 0xbffff760 打印地址0xbffff760的整数
print *(int *) ($ebp+8) 打印地址%ebp+8的整数
x/2w 0xbffff760 检查地址0xbffff760开始的双字(4字节)
x/20xb func 检查func函数20字节的十六进制表示
有用的信息
info frame 当前栈帧的信息
info registers 全部寄存器的值
help gdb帮助
教材学习中的问题和解决过程
- 问题1:
对于条件码和跳转指令存在较多疑惑
- 问题1解决方案:
可以根据条件码的某种组合来设置整数寄存器或执行条件分支指令。
下面的指令根据条件码的组合将一个字节设置为0或1,可以用 movzbl 指令对高位字节清零来得到32位结果。
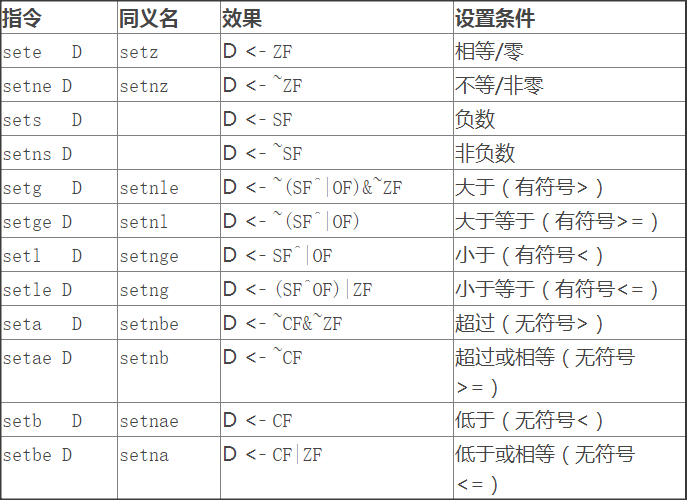
跳转指令使执行切换到程序中的一个新位置,跳转的目的地通常用标号指明。当跳转条件满足时,指令会跳转到一条带标号的目的地。
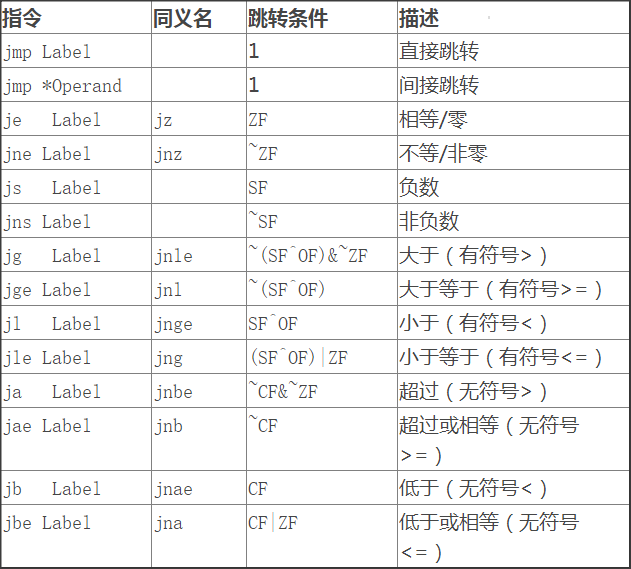
jmp 指令是无条件跳转。可以是直接跳转,以一个标号作为跳转目标,如 .L1 ;也可以是间接跳转,跳转目标从寄存器或存储器中读出,如 *(%eax) 。
条件跳转只能是直接跳转。
代码调试中的问题和解决过程
- 问题1:
无
- 问题1解决方案:
无
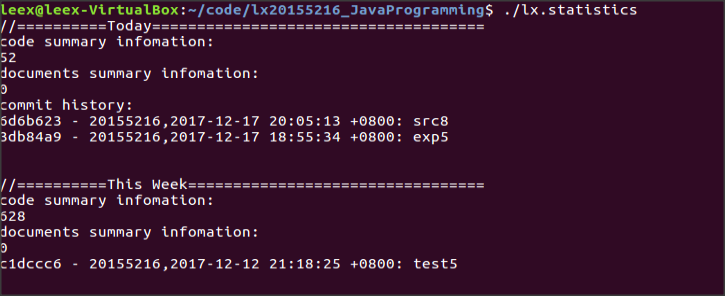
代码托管
结对及互评
本周结对学习情况
- [20155214](http://www.cnblogs.com/besti155214/p/8052476.html)
- 结对照片
- 结对学习内容
解答同伴问题:
其他(感悟、思考等,可选)
新的收获:
-
1、对于第三章的重新学习,重新梳理了一遍数据的表示、C代码和机器级代码的联系。
-
2、更加深入的学习了汇编语言中的指令。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第三周 | 114/114 | 3/3 | 20/20 | |
| 第四周 | 136/250 | 2/5 | 18/38 | |
| 第五周 | 87/337 | 2/7 | 22/60 | |
| 第六周 | 271/608 | 2/9 | 30/90 | |
| 第七周 | 185/716 | 2/11 | 30/90 | |
| 第八周 | 531/1247 | 3/14 | 30/90 | |
| 第九周 | 439/1686 | 3/17 | 30/90 | |
| 第十一周 | 153/1839 | 2/19 | 30/90 | |
| 第十三周 | 628/2467 | 2/21 | 30/90 | |
| 第十四周 | 0/2467 | 2/21 | 30/90 |
尝试一下记录「计划学习时间」和「实际学习时间」,到期末看看能不能改进自己的计划能力。这个工作学习中很重要,也很有用。
耗时估计的公式
:Y=X+X/N ,Y=X-X/N,训练次数多了,X、Y就接近了。
-
计划学习时间:25小时
-
实际学习时间:20小时
-
改进情况:
(有空多看看现代软件工程 课件
软件工程师能力自我评价表)