在.net中读写XML方法的总结
XML是一种很常见的数据保存方式,我经常用它来保存一些数据,或者是一些配置参数。 使用C#,我们可以借助.net framework提供的很多API来读取或者创建修改这些XML, 然而,不同人使用XML的方法很有可能并不相同。 今天我打算谈谈我使用XML的一些方法,供大家参考。
最简单的使用XML的方法
由于.net framework针对XML提供了很多API,这些API根据不同的使用场景实现了不同层次的封装, 比如,我们可以直接使用XmlTextReader、XmlDocument、XPath来取数XML中的数据, 也可以使用LINQ TO XML或者反序列化的方法从XML中读取数据。 那么,使用哪种方法最简单呢?
我个人倾向于使用序列化,反序列化的方法来使用XML。 采用这种方法,我只要考虑如何定义数据类型就可以了,读写XML各只需要一行调用即可完成。 例如:
// 1. 首先要创建或者得到一个数据对象 Order order = GetOrderById(123); // 2. 用序列化的方法生成XML string xml = XmlHelper.XmlSerialize(order, Encoding.UTF8); // 3. 从XML读取数据并生成对象 Order order2 = XmlHelper.XmlDeserialize<Order>(xml, Encoding.UTF8);
就是这么简单的事情,XML结构是什么样的,我根本不用关心, 我只关心数据是否能保存以及下次是否能将它们读取出来。
说明:XmlHelper是一个工具类,全部源代码如下: 
或许有人会说:我使用XPath从XML读取数据也很简单啊。
我认为这种说法有一个限制条件:只需要从XML中读取少量的数据。
如果要全部读取,用这种方法会写出一大堆的机械代码出来! 所以,我非常反感用这种方法从XML中读取全部数据。
类型定义与XML结构的映射
如果是一个新项目,我肯定会毫不犹豫的使用序列化和反序列化的方法来使用XML, 然而,有时在维护一个老项目时,面对一堆只有XML却没有与之对应的C#类型时, 我们就需要根据XML结构来逆向推导C#类型,然后才能使用序列化和反序列化的方法。 逆向推导的过程是麻烦的,不过,类型推导出来之后,后面的事情就简单多了。
为了学会根据XML结构逆向推导类型,我们需要关注一下类型定义与XML结构的映射关系。
注意:有时候我们也会考虑XML结构对于传输量及可阅读性的影响,所以关注一下XML也是有必要的。
这里有一个XML文件,是我从Visual Sutdio的安装目录中找到的:
怎样用反序列化的方式来读取它的数据呢,我在博客的最后将给出完整的实现代码。
现在,我们还是看一下这个XML有哪些特点吧。
<LinkGroup ID="sites" Title="Venus Sites" Priority="1500">
对于这个节点来说,它包含了三个数据项(属性):ID,Title,Priority。 这样的LinkGroup节点有三个。
类似的还有Glyph节点。
<LItem URL="http://www.asp.net" LinkGroup="sites">ASP.NET Home Page</LItem>
LItem节点除了与LinkGroup有着类似的数据(属性)之外,还包含着一个字符串:ASP.NET Home Page , 这是另外一种数据的存放方式。
另外,LinkGroup和LItem都允许重复出现,我们可以用数组或者列表(Array,List)来理解它们。
我还发现一些嵌套关系:LinkGroup可以包含Glyph,Context包含着Links,Links又包含了多个LItem。
不管如何嵌套,我发现数据都是包含在一个一个的XML节点中。
如果用专业的单词来描述它们,我们可以将ID,Title,Priority这三个数据项称为 XmlAttribute, LItem,LinkGroup节点称为 XmlElement,”ASP.NET Home Page“出现的位置可以称为 InnerText。 基本上,XML就是由这三类数据组成。
下面我来演示如何使用这三种数据项。
使用 XmlElement
首先,我来定义一个类型:
public class Class1 { public int IntValue { get; set; } public string StrValue { get; set; } }
下面是序列化与反序列的调用代码:
Class1 c1 = new Class1 { IntValue = 3, StrValue = "Fish Li" }; string xml = XmlHelper.XmlSerialize(c1, Encoding.UTF8); Console.WriteLine(xml); Console.WriteLine("---------------------------------------"); Class1 c2 = XmlHelper.XmlDeserialize<Class1>(xml, Encoding.UTF8); Console.WriteLine("IntValue: " + c2.IntValue.ToString()); Console.WriteLine("StrValue: " + c2.StrValue);
运行结果如下:
<?xml version="1.0" encoding="utf-8"?>
<Class1 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<IntValue>3</IntValue>
<StrValue>Fish Li</StrValue>
</Class1>
---------------------------------------
IntValue: 3
StrValue: Fish Li
结果显示,IntValue和StrValue这二个属性生成了XmlElement。
小结:默认情况下(不加任何Attribute),类型中的属性或者字段,都会生成XmlElement。
使用 XmlAttribute
再来定义一个类型:
public class Class2 { [XmlAttribute] public int IntValue { get; set; } [XmlElement] public string StrValue { get; set; } }
注意,我在二个属性上增加的不同的Attribute.
下面是序列化与反序列的调用代码:
运行结果如下(我将结果做了换行处理):
<?xml version="1.0" encoding="utf-8"?>
<Class2 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema"
IntValue="3">
<StrValue>Fish Li</StrValue>
</Class2>
---------------------------------------
IntValue: 3
StrValue: Fish Li
结果显示:
1. IntValue 生成了XmlAttribute
2. StrValue 生成了XmlElement(和不加[XmlElement]的效果一样,表示就是默认行为)。
小结:如果希望类型中的属性或者字段生成XmlAttribute,需要在类型的成员上用[XmlAttribute]来指出。
使用 InnerText
还是来定义一个类型:
public class Class3 { [XmlAttribute] public int IntValue { get; set; } [XmlText] public string StrValue { get; set; } }
注意,我在StrValue上增加的不同的Attribute.
下面是序列化与反序列的调用代码:
运行结果如下(我将结果做了换行处理):
<?xml version="1.0" encoding="utf-8"?>
<Class3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema"
IntValue="3">Fish Li</Class3>
---------------------------------------
IntValue: 3
StrValue: Fish Li
结果符合预期:StrValue属性在增加了[XmlText]之后,生成了一个文本节点(InnerText)
小结:如果希望类型中的属性或者字段生成InnerText,需要在类型的成员上用[XmlText]来指出。
重命名节点名称
看过前面几个示例,大家应该能发现:通过序列化得到的XmlElement和XmlAttribute都与类型的数据成员或者类型同名。 然而有时候我们可以希望让属性名与XML的节点名称不一样,那么就要使用【重命名】的功能了,请看以下示例:
[XmlType("c4")] public class Class4 { [XmlAttribute("id")] public int IntValue { get; set; } [XmlElement("name")] public string StrValue { get; set; } }
序列化与反序列的调用代码前面已经多次看到,这里就省略它们了。
运行结果如下(我将结果做了换行处理):
<?xml version="1.0" encoding="utf-8"?>
<c4 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema"
id="3">
<name>Fish Li</name>
</c4>
---------------------------------------
IntValue: 3
StrValue: Fish Li
看看输出结果中的红字粗体字,再看看类型定义中的三个Attribute的三个字符串参数,我想你能发现规律的。
小结:XmlAttribute,XmlElement允许接受一个别名用来控制生成节点的名称,类型的重命名用XmlType来实现。
列表和数组的序列化
继续看示例代码:
Class4 c1 = new Class4 { IntValue = 3, StrValue = "Fish Li" }; Class4 c2 = new Class4 { IntValue = 4, StrValue = "http://www.cnblogs.com/fish-li/" }; // 说明:下面二行代码的输出结果是一样的。 List<Class4> list = new List<Class4> { c1, c2 }; //Class4[] list = new Class4[] { c1, c2 }; string xml = XmlHelper.XmlSerialize(list, Encoding.UTF8); Console.WriteLine(xml); // 序列化的结果,反序列化一定能读取,所以就不再测试反序列化了。
运行结果如下:
<?xml version="1.0" encoding="utf-8"?>
<ArrayOfC4 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<c4 id="3">
<name>Fish Li</name>
</c4>
<c4 id="4">
<name>http://www.cnblogs.com/fish-li/</name>
</c4>
</ArrayOfC4>
现在c4节点已经重复出现了,显然,是我们期待的结果。
不过,ArrayOfC4,这个节点名看起来太奇怪了,能不能给它也重命名呢?
继续看代码,我可以定义一个新的类型:
// 二种Attribute都可以完成同样的功能。 //[XmlType("c4List")] [XmlRoot("c4List")] public class Class4List : List<Class4> { }
然后,改一下调用代码:
Class4List list = new Class4List { c1, c2 };
运行结果如下:
<?xml version="1.0" encoding="utf-8"?>
<c4List xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<c4 id="3">
<name>Fish Li</name>
</c4>
<c4 id="4">
<name>http://www.cnblogs.com/fish-li/</name>
</c4>
</c4List>
小结:数组和列表都能直接序列化,如果要重命名根节点名称,需要创建一个新类型来实现。
列表和数组的做为数据成员的序列化
首先,还是定义一个类型:
public class Root { public Class3 Class3 { get; set; } public List<Class2> List { get; set; } }
序列化的调用代码:
Class2 c1 = new Class2 { IntValue = 3, StrValue = "Fish Li" }; Class2 c2 = new Class2 { IntValue = 4, StrValue = "http://www.cnblogs.com/fish-li/" }; Class3 c3 = new Class3 { IntValue = 5, StrValue = "Test List" }; Root root = new Root { Class3 = c3, List = new List<Class2> { c1, c2 } }; string xml = XmlHelper.XmlSerialize(root, Encoding.UTF8); Console.WriteLine(xml);
运行结果如下:
<?xml version="1.0" encoding="utf-8"?>
<Root xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<Class3 IntValue="5">Test List</Class3>
<List>
<Class2 IntValue="3">
<StrValue>Fish Li</StrValue>
</Class2>
<Class2 IntValue="4">
<StrValue>http://www.cnblogs.com/fish-li/</StrValue>
</Class2>
</List>
</Root>
假设这里需要为List和Class2的节点重命名,该怎么办呢?
如果继续使用前面介绍的方法,是行不通的。
下面的代码演示了如何重命名列表节点的名称:
public class Root { public Class3 Class3 { get; set; } [XmlArrayItem("c2")] [XmlArray("cccccccccccc")] public List<Class2> List { get; set; } }
序列化的调用代码与前面完全一样,得到的输出结果如下:
<?xml version="1.0" encoding="utf-8"?>
<Root xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<Class3 IntValue="5">Test List</Class3>
<cccccccccccc>
<c2 IntValue="3">
<StrValue>Fish Li</StrValue>
</c2>
<c2 IntValue="4">
<StrValue>http://www.cnblogs.com/fish-li/</StrValue>
</c2>
</cccccccccccc>
</Root>
想不想把cccccccccccc节点去掉呢(直接出现c2节点)?
下面的类型定义方式实现了这个想法:
public class Root { public Class3 Class3 { get; set; } [XmlElement("c2")] public List<Class2> List { get; set; } }
输出结果如下:
<?xml version="1.0" encoding="utf-8"?>
<Root xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<Class3 IntValue="5">Test List</Class3>
<c2 IntValue="3">
<StrValue>Fish Li</StrValue>
</c2>
<c2 IntValue="4">
<StrValue>http://www.cnblogs.com/fish-li/</StrValue>
</c2>
</Root>
小结:数组和列表都在序列化时,默认情况下会根据类型中的数据成员名称生成一个节点, 列表项会生成子节点,如果要重命名,可以使用[XmlArrayItem]和[XmlArray]来实现。 还可以直接用[XmlElement]控制不生成列表的父节点。
类型继承与反序列化
列表元素可以是同一种类型,也可以不是同一种类型(某个类型的派生类)。
例如下面的XML:
<?xml version="1.0" encoding="utf-8"?>
<XRoot xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<List>
<x1 aa="1" bb="2" />
<x1 aa="3" bb="4" />
<x2>
<cc>ccccccccccc</cc>
<dd>dddddddddddd</dd>
</x2>
</List>
</XRoot>
想像一下,上面这段XML是通过什么类型得到的呢?
答案如下(注意红色粗体部分):
public class XBase { } [XmlType("x1")] public class X1 : XBase { [XmlAttribute("aa")] public int AA { get; set; } [XmlAttribute("bb")] public int BB { get; set; } } [XmlType("x2")] public class X2 : XBase { [XmlElement("cc")] public string CC { get; set; } [XmlElement("dd")] public string DD { get; set; } } public class XRoot { [XmlArrayItem(typeof(X1)), XmlArrayItem(typeof(X2))] public List<XBase> List { get; set; } }
序列化代码:
X1 x1a = new X1 { AA = 1, BB = 2 }; X1 x1b = new X1 { AA = 3, BB = 4 }; X2 x2 = new X2 { CC = "ccccccccccc", DD = "dddddddddddd" }; XRoot root = new XRoot { List = new List<XBase> { x1a, x1b, x2 } }; string xml = XmlHelper.XmlSerialize(root, Encoding.UTF8); Console.WriteLine(xml);
小结:同时为列表成员指定多个[XmlArrayItem(typeof(XXX))]可实现多种派生类型混在一起输出。
反序列化的实战演练
接下来,我们将根据前面介绍的知识点,用反序列化的方法来解析本文开头处贴出的那段XML:
那段XML的根元素是DynamicHelp,因此,我们需要定义一个类型,类名为DynamicHelp。
再观察那段XML,它应该包含一个LinkGroup列表,和一个Context属性,所以可以这样定义这三个类型:
public class DynamicHelp { [XmlElement] public List<LinkGroup> Groups { get; set; } public Context Context { get; set; } } public class LinkGroup { } public class Context { }
再来看LinkGroup,它包含三个数据成员,以及一个子节点:Glyph,因此可以这样定义它们:
public class LinkGroup { [XmlAttribute] public string ID { get; set; } [XmlAttribute] public string Title { get; set; } [XmlAttribute] public int Priority { get; set; } public Glyph Glyph { get; set; } } public class Glyph { [XmlAttribute] public int Collapsed { get; set; } [XmlAttribute] public int Expanded { get; set; } }
LItem节点也简单,它就包含了URL,LinkGroup和一个文本节点,因此可以这样定义它:
public class LItem { [XmlAttribute] public string URL { get; set; } [XmlAttribute] public string URL { get; set; } [XmlText] public string Title { get; set; } }
Context节点也不复杂,就只包含了一个LItem列表,因此可以这样定义它:
public class Context { public List<LItem> Links { get; set; } }
好了,类型都定义好了,再来试试反序列化:
DynamicHelp help = XmlHelper.XmlDeserializeFromFile<DynamicHelp>("Links.xml", Encoding.UTF8); foreach( LinkGroup group in help.Groups ) Console.WriteLine("ID: {0}, Title: {1}, Priority: {2}, Collapsed: {3}, Expanded: {4}", group.ID, group.Title, group.Priority, group.Glyph.Collapsed, group.Glyph.Expanded); foreach( LItem item in help.Context.Links ) Console.WriteLine("URL: {0}, LinkGroup: {1}, Title: {2}", item.URL.Substring(0, 15), item.LinkGroup, item.Title);
屏幕显示:
未处理的异常: System.InvalidOperationException: XML 文档(4, 2)中有错误。 ---> System.InvalidOperationException: 不应有 <DynamicHelp xmlns='http://msdn.microsoft.com/vsdata/xsd/vsdh.xsd'>。
哦,抛异常了。
别急,看看异常说什么。
好像是在说命名空间不能识别。
根据异常的描述,我还要修改一下DynamicHelp的定义,改成这样:
[XmlRoot(Namespace = "http://msdn.microsoft.com/vsdata/xsd/vsdh.xsd")] public class DynamicHelp
再次运行,结果如下:
ID: sites, Title: Venus Sites, Priority: 1500, Collapsed: 3, Expanded: 4 ID: Venus Private Forums, Title: Venus Private Forums, Priority: 1400, Collapsed: 3, Expanded: 4 ID: ASP.NET Forums, Title: ASP.NET 1.0 Public Forums, Priority: 1200, Collapsed: 3, Expanded: 4 URL: http://www.asp., LinkGroup: sites, Title: Venus Home Page URL: http://www.asp., LinkGroup: sites, Title: ASP.NET Home Page URL: http://www.asp., LinkGroup: Venus Private Forums, Title: General Discussions URL: http://www.asp., LinkGroup: Venus Private Forums, Title: Feature Requests URL: http://www.asp., LinkGroup: Venus Private Forums, Title: Bug Reports URL: http://www.asp., LinkGroup: Venus Private Forums, Title: ASP.NET 2.0 Related issues URL: http://www.asp., LinkGroup: ASP.NET Forums, Title: Announcements URL: http://www.asp., LinkGroup: ASP.NET Forums, Title: Getting Started URL: http://www.asp., LinkGroup: ASP.NET Forums, Title: Web Forms
小结:根据XML结构推导类型时,要保证类型的层次结构与XML匹配, 数据的存放方式可以通过[XmlElement],[XmlAttribute],[XmlText]方式来指出。
反序列化的使用总结
如果XML是由类型序列化得到那的,那么反序列化的调用代码是很简单的,
反之,如果要面对一个没有类型的XML,就需要我们先设计一个(或者一些)类型出来,
这是一个逆向推导的过程,请参考以下步骤:
1. 首先要分析整个XML结构,定义与之匹配的类型,
2. 如果XML结构有嵌套层次,则需要定义多个类型与之匹配,
3. 定义具体类型(一个层级下的XML结构)时,请参考以下表格。
| XML形式 | 处理方法 | 补充说明 |
| XmlElement | 定义一个属性 | 属性名与节点名字匹配 |
| XmlAttribute | [XmlAttribute] 加到属性上 | |
| InnerText | [XmlText] 加到属性上 | 一个类型只能使用一次 |
| 节点重命名 | 根节点:[XmlType("testClass")] 元素节点:[XmlElement("name")] 属性节点:[XmlAttribute("id")] 列表子元素节点:[XmlArrayItem("Detail")] 列表元素自身:[XmlArray("Items")] |
排除不需要序列化的成员
默认情况下,类型的所有公开的数据成员(属性,字段)在序列化时都会被输出, 如果希望排除某些成员,可以用[XmlIgnore]来指出,例如:
public class TestIgnore { [XmlIgnore] // 这个属性将不会参与序列化 public int IntValue { get; set; } public string StrValue { get; set; } public string Url; }
序列化调用代码:
TestIgnore c1 = new TestIgnore { IntValue = 3, StrValue = "Fish Li" }; c1.Url = "http://www.cnblogs.com/fish-li/"; string xml = XmlHelper.XmlSerialize(c1, Encoding.UTF8); Console.WriteLine(xml);
输出结果如下:
<?xml version="1.0" encoding="utf-8"?>
<TestIgnore xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<Url>http://www.cnblogs.com/fish-li/</Url>
<StrValue>Fish Li</StrValue>
</TestIgnore>
强制指定成员的序列化顺序
前面的示例很奇怪,我明明先定义的StrValue,后定义的Url,可是在输出时的顺序并是我期望的。
如果你希望控制序列化的输出顺序,可以参考下面的示例代码(注意红色粗体文字):
public class TestIgnore { [XmlIgnore] // 这个属性将不会参与序列化 public int IntValue { get; set; } [XmlElement(Order = 1)] public string StrValue { get; set; } [XmlElement(Order = 2)] public string Url; }
最终的输出结果如下:
<?xml version="1.0" encoding="utf-8"?>
<TestIgnore xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<StrValue>Fish Li</StrValue>
<Url>http://www.cnblogs.com/fish-li/</Url>
</TestIgnore>
自定义序列化行为
由于种种原因,可能需要我们自己控制序列化和反序列化的过程, 对于这种需求, .net framework也是支持的,下面我来演示如何这个过程。
假如我现在有这样的类型定义:
public class TestClass { public string StrValue { get; set; } public List<int> List { get; set; } } public class ClassB1 { public TestClass Test { get; set; } }
测试代码:
TestClass test = new TestClass { StrValue = "Fish Li", List = new List<int> { 1, 2, 3, 4, 5 } }; ClassB1 b1 = new ClassB1 { Test = test }; string xml = XmlHelper.XmlSerialize(b1, Encoding.UTF8); Console.WriteLine(xml); Console.WriteLine("-----------------------------------------------------"); ClassB1 b2 = XmlHelper.XmlDeserialize<ClassB1>(xml, Encoding.UTF8); Console.WriteLine("StrValue: " + b2.Test.StrValue); foreach( int n in b2.Test.List ) Console.WriteLine(n);
此时程序的输出结果如下:
<?xml version="1.0" encoding="utf-8"?>
<ClassB1 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<Test>
<StrValue>Fish Li</StrValue>
<List>
<int>1</int>
<int>2</int>
<int>3</int>
<int>4</int>
<int>5</int>
</List>
</Test>
</ClassB1>
-----------------------------------------------------
StrValue: Fish Li
1
2
3
4
5
现在我可能会想:TestClass这个类太简单了,但它输出的XML长度复杂了点,能不能再短小一点,让网络传输地更快呢?
在这里,我想到了自定义序列化行为来实现,请看下面对TestClass的重新定义。
public class TestClass : IXmlSerializable { public string StrValue { get; set; } public List<int> List { get; set; } public System.Xml.Schema.XmlSchema GetSchema() { return null; } public void ReadXml(XmlReader reader) { StrValue = reader.GetAttribute("s"); string numbers = reader.ReadString(); if( string.IsNullOrEmpty(numbers) == false ) List = (from s in numbers.Split(new char[] { ',' }, StringSplitOptions.RemoveEmptyEntries) let n = int.Parse(s) select n).ToList(); } public void WriteXml(XmlWriter writer) { writer.WriteAttributeString("s", StrValue); writer.WriteString(string.Join(",", List.ConvertAll<string>(x => x.ToString()).ToArray())); } }
继续使用前面的测试代码,现在的输出结果如下:
<?xml version="1.0" encoding="utf-8"?>
<ClassB1 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<Test s="Fish Li">1,2,3,4,5</Test>
</ClassB1>
-----------------------------------------------------
StrValue: Fish Li
1
2
3
4
5
很明显,现在的序列化结果要比以前的结果小很多。
而且,测试代码中的反序列化的显示也表明,我们仍然可以通过反序列化来读取它。
XML的使用建议
在服务端,C#代码中:
1. 建议不用使用低级别的XML API来使用XML,除非你是在设计框架或者通用类库。
2. 建议使用序列化、反序列化的方法来生成或者读取XML
3. 当需要考虑使用XML时,先不要想着XML结构,先应该定义好数据类型。
4. 列表节点不要使用[XmlElement],它会让所以子节点【升级】,显得结构混乱。
5. 如果希望序列化的XML长度小一点,可以采用[XmlAttribute],或者指定一个更短小的别名。
6. 不要在一个列表中输出不同的数据类型,这样的XML结构的可读性不好。
7. 尽量使用UTF-8编码,不要使用GB2312编码。
在客户端,JavaScript代码中,我不建议使用XML,而是建议使用JSON来代替XML,因为:
1. XML文本的长度比JSON要长,会占用更多的网络传输时间(毕竟数据保存在服务端,所以传输是免不了的)
2. 在JavaScritp中使用XML比较麻烦(还有浏览器的兼容问题),反而各种浏览器对JSON有非常好的支持。
线程间操作无效: 从不是创建控件“...”的线程访问它。
访问 Windows 窗体控件本质上不是线程安全的。如果有两个或多个线程操作某一控件的状态,则可能会迫使该控件进入一种不一致的状态。还可能出现其他与线程相关的 bug,包括争用情况和死锁。确保以线程安全方式访问控件非常重要。
.NET Framework 有助于在以非线程安全方式访问控件时检测到这一问题。在调试器中运行应用程序时,如果创建某控件的线程之外的其他线程试图调用该控件,则调试器会引发一个 InvalidOperationException,并提示消息:“从不是创建控件 control name 的线程访问它。”
此异常在调试期间和运行时的某些情况下可靠地发生。强烈建议您在显示此错误信息时修复此问题。在调试以 .NET Framework 2.0 版之前的 .NET Framework 编写的应用程序时,可能会出现此异常。
注意
可以通过将 CheckForIllegalCrossThreadCalls 属性的值设置为 false 来禁用此异常。这会使控件以与在 Visual Studio 2003 下相同的方式运行。
下面的代码示例演示如何从辅助线程以线程安全方式和非线程安全方式调用 Windows 窗体控件。它演示一种以非线程安全方式设置 TextBox 控件的 Text 属性的方法,还演示两种以线程安全方式设置 Text 属性的方法。
using System;
using System.ComponentModel;
using System.Threading;
using System.Windows.Forms;
namespace CrossThreadDemo
{
public class Form1 : Form
{
// 代理实现异步调用以设置TextBox控件text属性
delegate void SetTextCallback(string text);
// 此线程用来演示线程安全和非安全两种方式来调用一个windows窗体控件
private Thread demoThread = null;
// 此后台工作者(BackgroundWorker)用来演示执行异步操作的首选方式
private BackgroundWorker backgroundWorker1;
private TextBox textBox1;
private Button setTextUnsafeBtn;
private Button setTextSafeBtn;
private Button setTextBackgroundWorkerBtn;
private System.ComponentModel.IContainer components = null;
public Form1()
{
InitializeComponent();
}
protected override void Dispose(bool disposing)
{
if (disposing && (components != null))
{
components.Dispose();
}
base.Dispose(disposing);
}
// 此事件句柄创建一个ie线程以非安全方式调用一个windows窗体控件
private void setTextUnsafeBtn_Click(
object sender,
EventArgs e)
{
this.demoThread =
new Thread(new ThreadStart(this.ThreadProcUnsafe));
this.demoThread.Start();
}
// 此方法在工作者线程执行并且对TextBox控件作非安全调用
private void ThreadProcUnsafe()
{
this.textBox1.Text = "This text was set unsafely.";
}
// 此事件句柄创建一个以线程安全方式调用windows窗体控件的线程
private void setTextSafeBtn_Click(
object sender,
EventArgs e)
{
this.demoThread =
new Thread(new ThreadStart(this.ThreadProcSafe));
this.demoThread.Start();
}
// 此方法在工作者线程执行并且对TextBox控件作线程安全调用
private void ThreadProcSafe()
{
this.SetText("This text was set safely.");
}
// 此方法演示一个对windows窗体控件作线程安全调用的模式
//
// 如果调用线程和创建TextBox控件的线程不同,这个方法创建
// 代理SetTextCallback并且自己通过Invoke方法异步调用它
// 如果相同则直接设置Text属性
private void SetText(string text)
{
// InvokeRequired需要比较调用线程ID和创建线程ID
// 如果它们不相同则返回true
if (this.textBox1.InvokeRequired)
{
SetTextCallback d = new SetTextCallback(SetText);
this.Invoke(d, new object[] { text });
}
else
{
this.textBox1.Text = text;
}
}
// 此事件句柄通过调用RunWorkerAsync开启窗体的BackgroundWorker
//
// 当BackgroundWorker引发RunworkerCompleted事件的时候TextBox
// 控件的Text属性被设置
private void setTextBackgroundWorkerBtn_Click(
object sender,
EventArgs e)
{
this.backgroundWorker1.RunWorkerAsync();
}
// 此事件句柄设置TextBox控件的Text属性,它在创建TextBox控件的线程
// 中被调用,所以它的调用是线程安全的
//
// BackgroundWorker是执行异步操作的首选方式
private void backgroundWorker1_RunWorkerCompleted(
object sender,
RunWorkerCompletedEventArgs e)
{
this.textBox1.Text =
"This text was set safely by BackgroundWorker.";
}
#region Windows Form Designer generated code
private void InitializeComponent()
{
this.textBox1 = new System.Windows.Forms.TextBox();
this.setTextUnsafeBtn = new System.Windows.Forms.Button();
this.setTextSafeBtn = new System.Windows.Forms.Button();
this.setTextBackgroundWorkerBtn = new System.Windows.Forms.Button();
this.backgroundWorker1 = new System.ComponentModel.BackgroundWorker();
this.SuspendLayout();
//
// textBox1
//
this.textBox1.Location = new System.Drawing.Point(12, 12);
this.textBox1.Name = "textBox1";
this.textBox1.Size = new System.Drawing.Size(240, 20);
this.textBox1.TabIndex = 0;
//
// setTextUnsafeBtn
//
this.setTextUnsafeBtn.Location = new System.Drawing.Point(15, 55);
this.setTextUnsafeBtn.Name = "setTextUnsafeBtn";
this.setTextUnsafeBtn.TabIndex = 1;
this.setTextUnsafeBtn.Text = "Unsafe Call";
this.setTextUnsafeBtn.Click += new System.EventHandler(this.setTextUnsafeBtn_Click);
//
// setTextSafeBtn
//
this.setTextSafeBtn.Location = new System.Drawing.Point(96, 55);
this.setTextSafeBtn.Name = "setTextSafeBtn";
this.setTextSafeBtn.TabIndex = 2;
this.setTextSafeBtn.Text = "Safe Call";
this.setTextSafeBtn.Click += new System.EventHandler(this.setTextSafeBtn_Click);
//
// setTextBackgroundWorkerBtn
//
this.setTextBackgroundWorkerBtn.Location = new System.Drawing.Point(177, 55);
this.setTextBackgroundWorkerBtn.Name = "setTextBackgroundWorkerBtn";
this.setTextBackgroundWorkerBtn.TabIndex = 3;
this.setTextBackgroundWorkerBtn.Text = "Safe BW Call";
this.setTextBackgroundWorkerBtn.Click +=
new System.EventHandler(this.setTextBackgroundWorkerBtn_Click);
// backgroundWorker1
//
this.backgroundWorker1.RunWorkerCompleted +=
new System.ComponentModel.RunWorkerCompletedEventHandler(
this.backgroundWorker1_RunWorkerCompleted);
//Form1
this.ClientSize = new System.Drawing.Size(268, 96);
this.Controls.Add(this.setTextBackgroundWorkerBtn);
this.Controls.Add(this.setTextSafeBtn);
this.Controls.Add(this.setTextUnsafeBtn);
this.Controls.Add(this.textBox1);
this.Name = "Form1";
this.Text = "Form1";
this.ResumeLayout(false);
this.PerformLayout();
}
#endregion
[STAThread]
static void Main()
{
Application.EnableVisualStyles();
Application.Run(new Form1());
}
}
}
浏览器详谈及其内部工作机制 —— web开发必读
2013-05-05 23:08 by MoltBoy, 109 阅读, 0 评论, 收藏, 编辑浏览器介绍
如今,浏览器格局基本上是五分天下,分别是:IE、Firefox、Safari、Chrome、Opera,而浏览器引擎就更加集中了,主要是四大巨头:IE的浏览器排版引擎Trident,目前随IE10发布了Trident6.0;Mozilla的排版引擎Gecko,今天4月2号发布了Gecko21预览版,稳定版本为Gecko20;Google Chrome和Apple Safari使用的是WebKit引擎,它已经成为市场占用率最高的排版引擎;另外还有Opera的Presto引擎,不过在今天的2月13号,Opera Software宣布未来产品将以Webkti和V8为主,逐步放弃基于Presto引擎产品。也就是说,如今的浏览器排版引擎基本上是三分天下。
据国外媒体报道,Google当地时间周三宣布将放弃渲染引擎WebKit,开发名为Blink的渲染引擎。Opera也宣布将采用Blink。主要的原因是,与其他WebKit 浏览器相比,Chromium 使用的是一个不同的多过程架构体系。在过去多年为了支持多个架构体系,WebKit 和 Chromium 社区面临的问题越来越复杂,延缓了创新的整体速度。

浏览器的功能
浏览器的主要功能是将用户选择的web资源用网页的形式显示出来,这些资源包括:文字、图像、等其他信息,而web资源都是通过URI(uniform resource identifier)来定位。大部分网页都是HTML格式,网页的样式都是使用CSS来定义,相关的规范由W3C组织来进行制定和维护。但是,这些年来,浏览器开发商纷纷为了抢占市场及其扩展强化自己的产品,对相关的规范并不完全遵守,这也导致了如今web领域严重的兼容性问题。
浏览器内部结构
①、用户界面(UI) - 包括菜单栏、工具栏、地址栏、后退/前进按钮、书签目录等,也就是能看到的除了显示页面的主窗口之外的部分;
②、浏览器引擎(Rendering engine) - 也被称为浏览器内核、渲染引起,主要负责取得页面内容、整理信息(应用CSS)、计算页面的显示方式,然后会输出到显示器或者打印机;
③、JS解释器 - 也可以称为JS内核,主要负责处理javascript脚本程序,一般都会附带在浏览器之中,例如chrome的V8引擎;
④、网络部分 - 主要用于网络调用,例如:HTTP请求,其接口与平台无关,并为所有的平台提供底层实现;
⑤、UI后端 - 用于绘制基本的窗口部件,比如组合框和窗口等。
⑥、数据存储 - 保存类似于cookie、storage等数据部分,HTML5新增了web database技术,一种完整的轻量级客户端存储技术。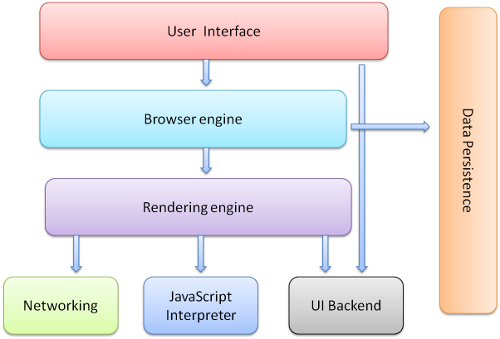
值得注意的是,IE只为每个浏览器窗口启用单独的进程,而chrome浏览器却为每个tab页面单独启用进程,也就是每个tab都有独立的渲染引擎实例。
渲染引擎
渲染并不是计算机领域的术语,而是来自于绘画领域,绘画时经常使用水墨或者淡色涂抹画布,以烘托物象,分出阴阳向背,主要用来加强艺术效果,明代 - 杨慎《艺林伐山·浮渲梳头》:“画家以墨饰美人鬢髮谓之渲染。”在这里就不扯远了,在电脑绘图中, 是指软件从模型生成图像的过程,包括几何、视点、纹理、和照明信息等。
浏览器的渲染引擎也主要是干这勾当的,负责显示HTML文档、XML文档以及图片、动画等信息,还可以借组浏览器的一些差距显示其他数据类型,例如:flash、pdf等。
渲染的主要步骤
渲染引擎首先通过网络部分获取request响应的文档内容,一般以8K为单位分块进行。解析HTML用以构建DOM树结构 -> 构建Render树 -> Render树的布局 -> 绘制Render树。
渲染引擎解释HTML文档,首先将标签转换成DOM树中的DOM node;接着,解释对应的CSS样式文件信息,而这些样式信息以及HTML中可见的指令(<b></b>etc)将被用来构建另外的Render树。这棵树主要由一些包含颜色和宽高等属性组成的矩形组成,它们将依次按顺序显示在屏幕上。
待Renter树构建完成,将执行布局过程,确定每个节点在屏幕上对应的坐标,及其覆盖和回流情况等,然后浏览器会遍历Renter树,并使用UI后端层绘制每个节点。这整个过程都是逐步进行的,HTML内容显示一部分,将构建和布局一部分Renter树,就先显示出来。也就是解释完一部分内容就显示一部分出来,而不是等着HTML内容解释完成才进行构建Renter树,同时,还有可能通过网络层进行下载其余的内容。
解析与DOM树构建
解析就是将一个文档转换成指定的结构,解析的结构通常是表达文档结构的节点树。例如:num1 + num2 * num3,可以解析成如下的DOM树。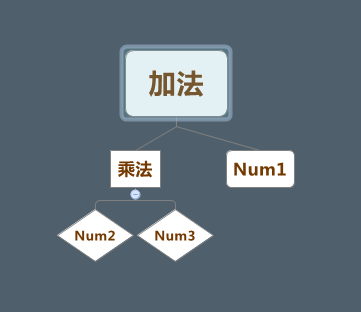
文法
解析基于文档依据的语法规则 —— 文档的语言和格式,每种可以被解析的格式必须是具有由词法及其语法规则组成的特定文法。
词法
解析可以分为两个过程:语法分析和词法分析。
词法分析就是将输入分解成符号,也可以理解为将字符序列转换为单词序列的过程,进行词法分析的程序或者函数叫做词法分析器(Lexical analyzer) - Lexer,一般以函数的形式存在,供语法分析器调用。这里说的单词序列也就是字符串序列,是构成源代码的最小单位。从输入字符流中生成单词的过程叫做单词话,在这个过程中,词法分析器会对单词进行分类,但通常不关心单词之间的关系,那属于语法分析的范畴,不会出现越俎代庖的情形。
语法分析(Syntactic analysis)是根据某种给定的形式文法对由单词序列构成的文本进行分析并确定其语法结构的一个过程。语法分析器主要作用就是进行语法检查、并且构建由单词组成的数据结构(一般是语法分析树、抽象语法树等层次化的结构)。
基本的流程:document -> Lexical analyzer -> Syntactic analysis -> Parse Tree。解析过程是迭代的,解析器从词法分析器处获得一个新的符号,并试着用这个符号匹配一条语法规则,若匹配则添加到解析树种,否则先暂时保存该符号,并继续匹配下一个符号;若最终都没有找到可以匹配的规则,解析器就会抛出一个异常,一般是语法错误。
转换
解析树并不是最终的结果,还需要进行格式转换。例如编译的流程:Source Code -> Parsing ->parse Tree -> Translation ->Machine Code。
CSS解析
CSS属于上下文无关文法,可以按照前面所述的解析器解析,CSS规范定义了CSS词法及语法文法。
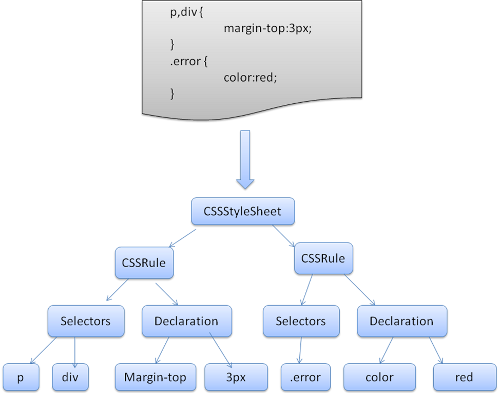
CSS解析生成器将每个CSS文件解析城样式表对象,每个对象包含CSS规则,CSS规则对象包含选择器和声明对象,以及其他一些符合CSS语法的对象。如上图案例所示。
脚本处理和CSS顺序
web的模式是同步的,解析到一个script标签立即解析执行脚本,并阻塞文档的解析直到脚本执行完成。如果脚本是外引的,则网络必须先请求到这个资源 —— 这个过程也是同步的,阻塞文档的解析直到资源被请求到。不过,开发者可以将脚本标示为defer,以使其不阻塞文档的正常解析,并在文档的解析完成后执行。Html5增加了标记脚本为异步的选项,以使脚本的解析执行可以使用另一个线程。
预解析
hrome和Firefox进行了解析的优化,当执行脚本时,另一个线程解析剩余的文档,并加载后面需要通过网络加载的资源。这种方式可以使用资源并行加载,从而使整体速度加快。但是,预解析并不改变DOM树,它只是解析外部资源的引用,例如:外部脚本、样式表、图片等。
理论上,样式表的解析并不改变DOM树,但是脚本可能在文档的解析过程中请求样式信息,假如样式信息还没有加载和解析,脚本将得到错误的信息,显然这会导致很多问题。Chrome只在当脚本试图访问可能被未加载的样式表所影响的特定样式属性时才会阻塞脚本。
渲染树的构建
当DOM树构建完成,又可是构建另一棵 —— 渲染树。渲染树由元素显示序列中的可见元素组成,是文档的可视化表示,构建这棵树是为了以正确的顺序绘制文档内容。
渲染树和DOM树的关系
渲染对象和DOM元素是相对应,但这种关系关系不是一对一的,不可见的DOM元素不会被插入渲染树之中。例如:display为none,但是visibility为hidden的元素却将出现在渲染树种,因为它需要渲染,只是不显示在屏幕上而已。
另外还有一些DOM元素对应几个可见的对象,例如:select元素,它是个相对复杂结构的元素,由三个渲染对象组成:显示区域、下拉列表、按钮。同样,当文本输入因为宽度不够而折行时,新增的行将作为额外的渲染元素被添加。
还有一些渲染对象和应当对应的DOM节点不在两棵树相同的位置,例如:浮动和绝对定位的元素在正常流之外,渲染树上标识出真实的结构,并用一个占位结构标识出它们原来
的位置。
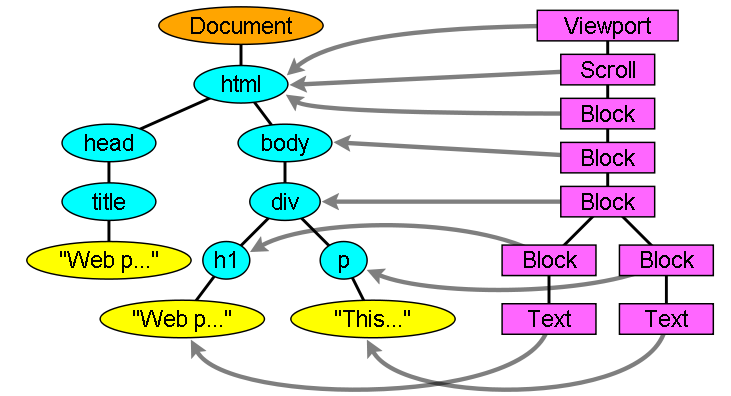
处理html和body标签将构建渲染树的根,这个根渲染对象对应被css规范为containing block的元素,包含着其他所有块元素的顶级块元素。它的大小就是viewport,Firefox称之为viewPortFrame,WebKit称之为RenderView,也就是文档对应的渲染对象。
样式计算
创建渲染树需要计算出每个渲染对象的可视属性,这可以通过计算每个元素的样式属性而得到。样式包括各种来源的样式表,包括行内样式表、外部样式表等。计算样式数据量比较大,不进行优化的话,寻找每个元素匹配的规则会导致性能问题,为每个元素查找匹配的规则都需要遍历整个规则表,这个过程有很大的工作量。
我们来看一下浏览器如何处理这些问题:
共享样式数据(Sharing style data)
WebkKit节点引用样式对象(渲染样式),某些情况下,这些对象可以被节点间共享,这些节点需要是兄弟或是表兄弟节点,并且:
1. 这些元素必须处于相同的鼠标状态(比如不能一个处于hover,而另一个不是)
2. 不能有元素具有id
3. 标签名必须匹配
4. class属性必须匹配
5. 对应的属性必须相同
6. 链接状态必须匹配
7. 焦点状态必须匹配
8. 不能有元素被属性选择器影响
9. 元素不能有行内样式属性
10. 不能有生效的兄弟选择器,webcore在任何兄弟选择器相遇时只是简单的抛出一个全局转换,并且在它们显示时使整个文档的样式共享失效,这些包括+选择器和类似:first-child和:last-child这样的选择器。
Firefox规则树(Firefox rule tree)
Firefox用两个树用来简化样式计算-规则树和样式上下文树,WebKit也有样式对象,但它们并没有存储在类似样式上下文树这样的树中,只是由Dom节点指向其相关的样式。

样式上下文包含最终值,这些值是通过以正确顺序应用所有匹配的规则,并将它们由逻辑值转换为具体的值,例如,如果逻辑值为屏幕的百分比,则通过计算将其转化为绝对单位。样式树的使用确实很巧妙,它使得在节点中共享的这些值不需要被多次计算,同时也节省了存储空间。
所有匹配的规则都存储在规则树中,一条路径中的底层节点拥有最高的优先级,这棵树包含了所找到的所有规则匹配的路径(译注:可以取巧理解为每条路径对 应一个节点,路径上包含了该节点所匹配的所有规则)。规则树并不是一开始就为所有节点进行计算,而是在某个节点需要计算样式时,才进行相应的计算并将计算 后的路径添加到树中。
我们将树上的路径看成辞典中的单词,假如已经计算出了如下的规则树:

假如需要为内容树中的另一个节点匹配规则,现在知道匹配的规则(以正确的顺序)为B-E-I,因为我们已经计算出了路径A-B-E-I-L,所以树上已经存在了这条路径,剩下的工作就很少了。
绘制(Painting)
绘制阶段,遍历渲染树并调用渲染对象的paint方法将它们的内容显示在屏幕上,绘制使用UI基础组件,这在UI的章节有更多的介绍。
全局和增量
和布局一样,绘制也可以是全局的——绘制完整的树——或增量的。在增量的绘制过程中,一些渲染对象以不影响整棵树的方式改变,改变的渲染对象使其在屏 幕上的矩形区域失效,这将导致操作系统将其看作dirty区域,并产生一个paint事件,操作系统很巧妙的处理这个过程,并将多个区域合并为一个。 Chrome中,这个过程更复杂些,因为渲染对象在不同的进程中,而不是在主进程中。Chrome在一定程度上模拟操作系统的行为,表现为监听事件并派发 消息给渲染根,在树中查找到相关的渲染对象,重绘这个对象(往往还包括它的children)。
绘制顺序
css2定义了绘制过程的顺序——http://www.w3.org/TR/CSS21/zindex.html。这个就是元素压入堆栈的顺序,这个顺序影响着绘制,堆栈从后向前进行绘制。
一个块渲染对象的堆栈顺序是:
1. 背景色
2. 背景图
3. border
4. children
5. outline
动态变化
浏览器总是试着以最小的动作响应一个变化,所以一个元素颜色的变化将只导致该元素的重绘,元素位置的变化将大致元素的布局和重绘,添加一个Dom节 点,也会大致这个元素的布局和重绘。一些主要的变化,比如增加html元素的字号,将会导致缓存失效,从而引起整数的布局和重
渲染引擎的线程
渲染引擎是单线程的,除了网络操作以外,几乎所有的事情都在单一的线程中处理,在Firefox和Safari中,这是浏览器的主线程,Chrome中这是tab的主线程。
网络操作由几个并行线程执行,并行连接的个数是受限的(通常是2-6个)。
事件循环
浏览器主线程是一个事件循环,它被设计为无限循环以保持执行过程的可用,等待事件(例如layout和paint事件)并执行它们。