【TCP/IP】检验和算法
在巨著《TCP/IP详解1》中有这样一句话:“ICMP,IGMP,UDP and TCP all use the same checksum algorithm”。的确,检验和算法在TCP/IP协议族中大同小异。接收方通过判断检验和是否一致,进一步判断该数据包头部传输过程中是否丢失或者被污染了。本文将以IP协议首部(见下图)为例简单介绍检验和算法:

简单地说,检验和是一个16位字段,即上图中16位首部检验和。通过设置该字段取值,将该IP首部是否完整的信息携带其中。还记得以前的信封吗,在信封背面,往往有一个红泥印,这样一来,收信人就能够通过红泥印判断信封是否曾被人打开。而检验和字段就是IP数据包首部的“红泥印”。

如何设置检验和呢?或许有许多方法,目前,最为流行的一种方法是这样的。首先在发送端计算检验和,将其与IP数据包一起发出,接收端对该数据包头部进行相应的处理,得到检验和大小,从而判断数据包头部是否完整。
检验和算法可以分成两步来实现。首先在发送端,有以下三步:
- 把即将发送的IP头部中的检验和设置为0,然后以16位为一个间隔,将IP头部分成许多个16位的字段;
- 将第1步获得的所有字段进行二进制相加求和;
- 把最终结果取反,就得到检验和,再将该值填充到IP头部。
其次在接收端,也有相应的三步:
- 把接收到的IP头部分成16位一个间隔的字段集合;
- 所有字段进行二进制相加求和;
- 将最终结果取反,判断该结果是否为0,若为0,则说明检验和正确,若不为0,则协议栈会丢掉这个包。(你没看错,这一步还是要取反)
上面的步骤,很抽象,也很无聊。一起来看一个例子。见下图:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 4 | 5 | 0 | 28 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 1 |0 | 0 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 4 | 17 | 0(checksum) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 10.12.14.5 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 12.6.7.9 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
这是一个典型的IP报头,其中各种值,已经设置好了。检验和也为0。
可以使用二进制或者十六进制来计算它的检验和。
4,5--> 0100 0101 0000 0000
28 --> 0000 0000 0001 1100
1 --> 0000 0000 0000 0001
0,0-->0000 0000 0000 0000
4,17-->0000 0100 0001 0001
0 -->0000 0000 0000 0000
10.12-->0000 1010 0000 1100
14.5-->0000 1110 0000 0101
12.6-->0000 1100 0000 0110
7.9-->0000 0111 0000 1001
和-->0111 0100 0100 1110(744E,十六进制)
对上面的求和取反,就得到检验和,为8BB1。
假设数据包是完整的,接收端相应地进行操作,8BB1+744E,就得到了FFFF,取反则为0,所以验证了数据包没有被污染。
这一切,似乎都是我在瞎捣弄,所以这么巧合。那么,一起来看看使用wireshake抓包软件随机抓包的结果,有图有真相,抓到的包是一个接收端的包,看官可以按照上面所说的方法进行计算,看看最后结果是否符合图中所示检验和,trick。
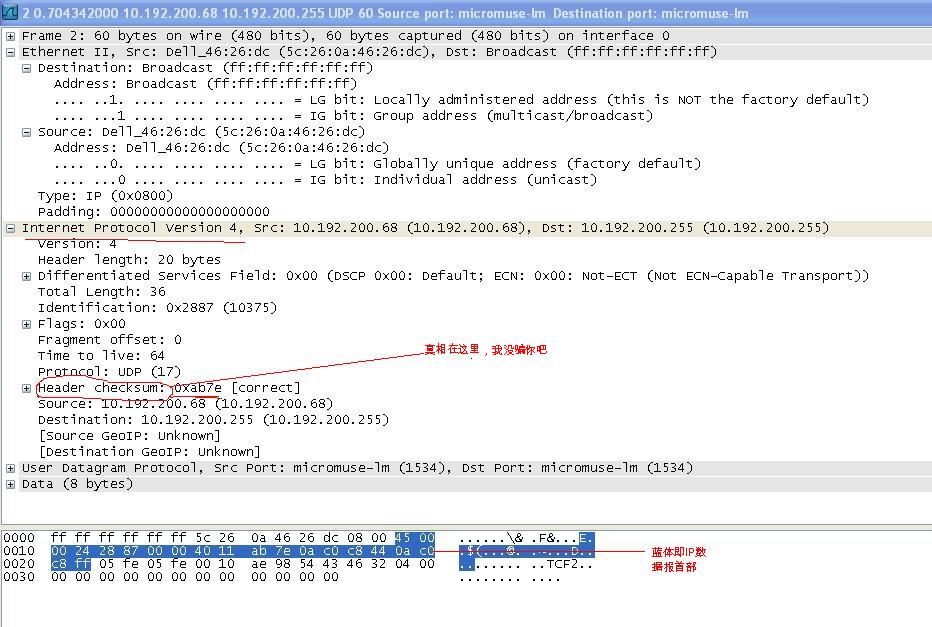
或许,最后知道真相的你眼泪掉下来。这个过程分明就是一次“左右互搏”。其原理可以形象地表示为下图,图中T为除了checksum之后,IP数据包首部其他的字段和,即检验和算法步骤2的结果:

再来看看代码,网上到处都有这份代码,我就随便copy了,汇编代码请参考附录链接1:

USHORT checksum (USHORT *buffer,int size) { Unsigned long cksum=0;/*32位长整数,检验和被置为0*/ While (size>1) { Cksum +=*buffer++; size -=sizeof(USHORT); } If (size) /*处理剩余下来的字段,这些字段皆小于16位*/ { Cksum +=*(UCHAR *) buffer; } /*将32位转换为16位,高16位与低16位相加*/ While (cksum>>16) Cksum = (cksum>>16) + (cksum & 0xffff); Return (USHORT) (~cksum); }
当你看完代码,肯定有一个疑惑,为什么要将cksum设置为32位而非16位呢?这要回到刚才wireshake那张图来解释,那张图里面有一个trick,尽管我标明了,但未必引起你的注意。按我前面所说的步骤仔细计算图中的检验和,肯定会发现一个奇怪的地方。该图中的所有16位字段相加,最后结果是2547F(16进制),已经超出了16位,如何处理这个超出的数’2’呢?难道上面计算检验和的方法是错误的?好吧,对不起,为了简单起见,我没有在前面指出这一点。这个漏洞涉及到了一个知识点,二进制反码计算。细节不再赘述,请参考附录链接2。在此处,我们这样处理,将溢出的“2”与最末端“F”相加,得到5481,将5481与ab7e相加,就是FFFF,取反,正好为0,说明这个数据包没有“被人动过手脚”,这样它才能被wireshake抓到,否则,早就被协议栈丢弃了。
除了检验和之外,差错检验还有许多其他方法,比如奇偶检验,循环冗余检验(CRC)。感兴趣的话,可以阅读RFC1071,请参考附录链接3。
附录:
链接3:http://www.faqs.org/rfcs/rfc1071.html
链接2:http://blog.chinaunix.net/uid-26758209-id-3146230.html
链接1:http://blog.csdn.net/chenlong12580/article/details/7354037
参考书1:《TCP/IP协议族》 BehrouzA.Forouzan著,谢希仁审校
参考书2:《TCP/IP详解1》Richard Stevens