C++中的虚函数总结
一、什么是虚函数、纯虚函数、抽象基类
虚函数:在某基类中声明为 virtual 并在一个或多个派生类中被重新定 义的成员函数。
纯虚函数:是一种特殊的虚函数,使用virtual关键字,并且在其后面加上=0。
抽象基类:在基类中加入至少一个纯虚函数,使基类成为抽象类。
二、为什么要使用虚函数
在理解这个问题前,就必须要理解什么是晚捆绑。
晚捆绑是相对于早捆绑而言的,那么什么又是捆绑呢?把函数体与函数调用相联系称为捆绑,当捆绑在程序运行之前完成时,这称为早捆绑。那么当捆绑根据对象的类型,发生在运行时,就称为晚捆绑。
而使用晚捆绑,无需检查对象的类型,只需要检查对象是否支持特性和方法即可。
为了引发晚捆绑,C++要求在基类中声明这个函数时使用virture关键字。晚捆绑只对virtual函数起作用,而且只在使用含有virtual函数的基类的地址时发生。
三、关于重写
如果一个函数在基类中被声明为virtual,那么在所有的派生类中它都是virtual,在派生类中virtual函数的重定义通常称为重写。
四、在C++中如何实现晚捆绑
虚函数主要有两个步骤:
1、每一个类产生出一堆指向虚函数的指针,放在表格中。这个表格被称为virtual table(vtbl)
2、每一个类对象被安插一个指针,指向相关的virtual table,通常这个指针被称为vptr
结构图如下:

每当创建一个包含有虚函数的类或从包含有虚函数的类派生一个类时,编译器就为这个类创建一个唯一的vtbl。如果在这个派生类中没有对在基类中声明为virtual的函数进行重新定义,编译器就使用基类的这个虚函数地址。然后编译器在这个类中放置vptr。当使用简单继承时,对于每个对象都只有一个vtbl。vptr必须被初始化为指向相应的vtbl的起始地址。
五、虚函数的存放类型信息
假如没有虚函数,那么对象的长度就是所期望的长度:比如当个int的长度。而带有单个虚函数的One Virtual,对象的长度是No Virtual的长度加上一个void指针的长度。如果有一个或多个虚函数,编译器都只在这个结构中插入一个单个指针,这个指针指向虚函数表。在32为的机器上,一个指针占3字节的空间,因此求sizeof得到4;如果是64位的机器,一个指针占8字节的空间,因此求sizeof则得到8.
六、关于抽象类和纯虚函数
1、当继承一个抽象类时,必须实现所有的纯虚函数,否则继承出的类也将是一个抽象类
2、声明一个纯虚函数,就等于告诉编译器在vtbl中为函数保留一个位置,但在这个位置不放地址。只要有一个函数在类中被声明为纯虚函数,则vtbl就是不完全的。
3、纯虚函数禁止对抽象类的函数以传值方式调用,这是一种防止对象切片的方法。抽象类可以保证在向上类型转换期间总是使用指针或引用。
4、对于纯虚函数,如果要创建对象,必须要在派生类中定义。
七、什么是对象切片
在继承的过程中,通常派生类不仅具有基类的特征,也具有自身的一些特征。当派生类向上进行类型转换称为基类时,就会发生那些自身的特征被切除,只保留继承了基类的特征,这种现象就是对象切片。
例如:狗类继承了宠物类,具有宠物类的名称这个属性,同时又有啃骨头的特性,当狗类要被转换为宠物类时,就必须抛弃自己爱啃骨头的爱好,这样只保留了对应于宠物类的那部分。流程如下:
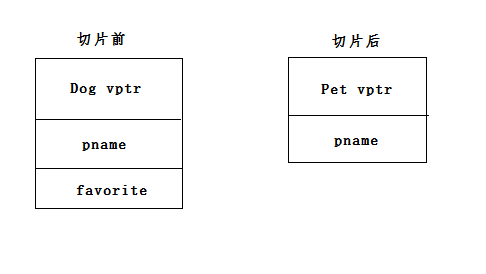
八、虚函数和构造函数
1、由于基类构造函数总是在继承类构造函数中被调用,这就确保了在派生类中,基类的所有成员都是有效的,即所有成员都已经建立。
2、虚机制在构造函数中不工作。有两种理由:
A、在任何构造函数中,我们只能知道基类已被初始化,但不能知道哪个类是从这个基类继承来的。但是,虚函数在继承层次上是向前和向后调用。它可以调用派生类中的函数。
B、构造函数的vptr的状态是由最后调用的构造函数确定的,这就意味着当最后调用的构造函数还没有完成之前,当前的构造函数完全不知道这个对象是否是基于其他类的。但是,当这一系列的构造函数调用正发生时,每个构造函数都已经设置vptr指向它自己的vtbl,如果函数调用使用虚机制,它将只产生通过它自己的vtbl的调用,而不是最后派生的vtbl。
九、虚析构函数和析构函数
1、析构函数自最晚派生的类开始,并向上到基类。这就意味着每个析构函数知道它所在类从哪一个类派生而来,但不知道从它派生出哪些类。
2、析构函数可以为虚函数,因为这个对象已经知道它是什么类型,但是在构造期间就不知道了。一旦对象已被构造,它的vptr就已经被初始化,所以能发生虚函数调用。
3、虚构函数的纯虚性的唯一效果是阻止基类的实例化
十、虚函数、纯虚函数、抽象类的作用
虚函数的作用:每个类必须提供一个可以被调用的虚函数,但每个类可以按它们认为合适的任何方式处理。如果某个类不想做什么特别的事,可以借助于基类中提供的缺省处理函数。也就是说,虚函数的声明是在告诉子类的设计者,"你必须支持虚函数,但如果你不想写自己的版本,可以借助基类中的缺省版本。
纯虚函数的作用:让所有的类对象(主要是派生类对象)都可以执行纯虚函数的动作,但类无法为纯虚函数提供一个合理的缺省实现。所以类纯虚函数的声明就是在告诉子类的设计者,“你必须提供一个纯虚函数的实现,但我不知道你会怎样实现它”。
抽象类的主要作用是将有关的操作作为结果接口组织在一个继承层次结构中,由它来为派生类提供一个公共的根,派生类将具体实现在其基类中作为接口的操作。所以派生类实际上刻画了一组子类的操作接口的通用语义,这些语义也传给子类,子类可以具体实现这些语义,也可以再将这些语义传给自己的子类。
判别式模型 vs. 生成式模型
1. 简介
生成式模型(generative model)会对x和y的联合分布p(x,y)进行建模,然后通过贝叶斯公式来求得p(y|x), 最后选取使得p(y|x)最大的yi. 具体地, y∗=argminyip(yi|x)=argminyip(x|yi)p(yi)p(x)=argminyip(x|yi)p(yi)=argminyip(x,yi).
判别式模型(discriminative model)则会直接对p(y|x)进行建模.
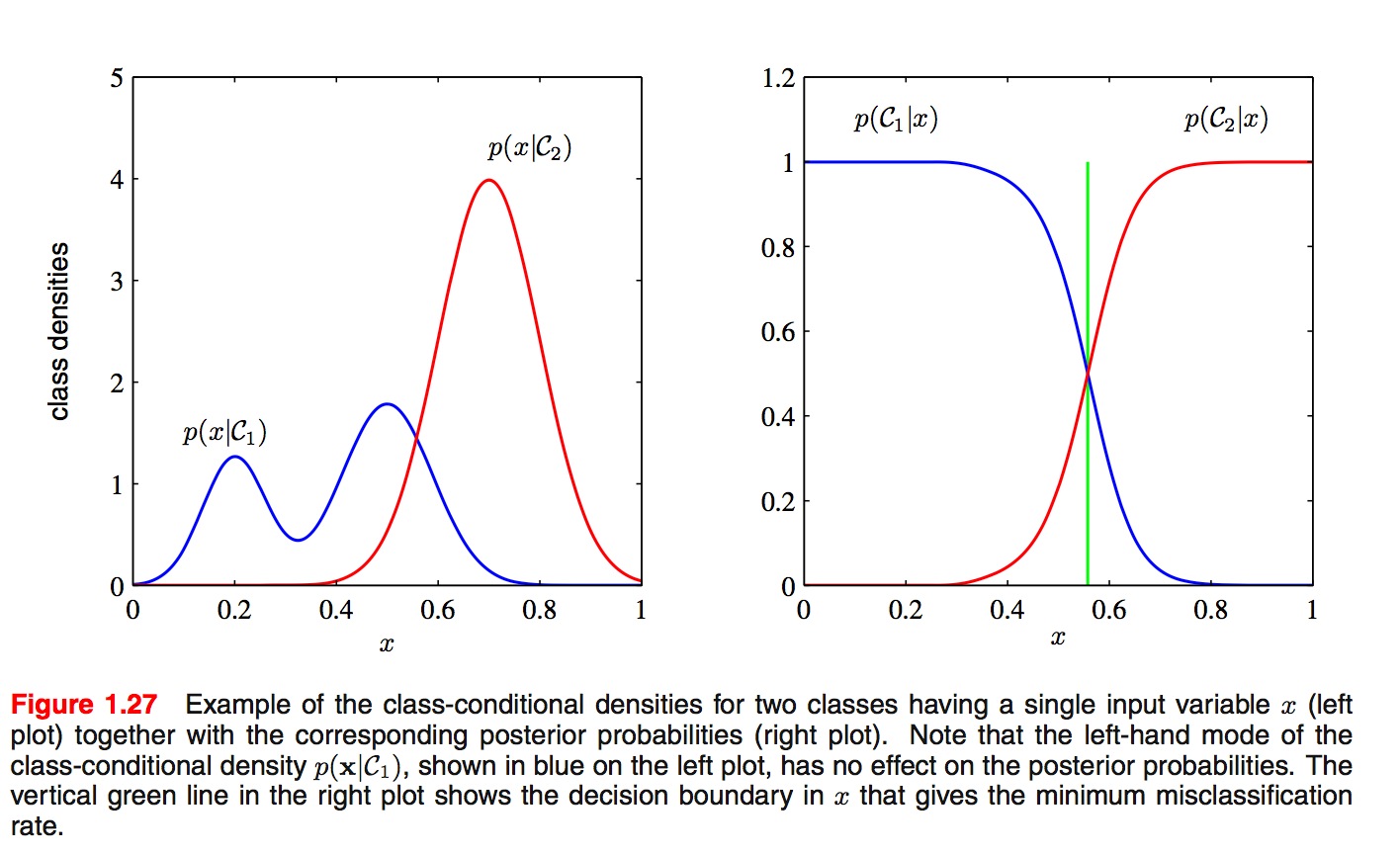
关于二者之间的优劣有大量的讨论. SVM的发明者Vapnik声称"one should solve the (classification) problem directly and never solve a more general problem as an intermediate step [such as modeling p(x|y)]", 但是, 最近Deep Learning大行其道, 其代表性算法DBN就是生成式模型. 通常来说, 因为生成式模型要对类条件密度(class conditional density)p(x|yi)进行建模, 而判别式模型只需要对类后验密度(class-posterior density)进行建模, 前者通常会比后者要复杂, 更难以建模, 如下图所示.
2. 对比
下面简单比较下生成式模型和判别式模型的优缺点.
1. 一般来说, 生成式模型都会对数据的分布做一定的假设, 比如朴素贝叶斯会假设在给定y的情况下各个特征之间是条件独立的:p(X|y)=∏Ni=1p(xi|y), GDA会假设
p(X|y=c,θ)=N(μc,Σc). 当数据满足这些假设时, 生成式模型通常需要较少的数据就能取得不错的效果, 但是当这些假设不成立时, 判别式模型会得到更好的效果.
2. 生成式模型最终得到的错误率会比判别式模型高, 但是其需要更少的训练样本就可以使错误率收敛[限于Genarative-Discriminative Pair, 详见[2]].
3. 生成式模型更容易拟合, 比如在朴素贝叶斯中只需要计下数就可以, 而判别式模型通常都需要解决凸优化问题.
4. 当添加新的类别时, 生成式模型不需要全部重新训练, 只需要计算新的类别ynew和x的联合分布p(ynew,x)即可, 而判别式模型则需要全部重新训练.
5. 生成式模型可以更好地利用无标签数据(比如DBN), 而判别式模型不可以.
6. 生成式模型可以生成x, 因为判别式模型是对p(x,y)进行建模, 这点在DBN的CD算法中中也有体现, 而判别式模型不可以生成x.
7. 判别式模型可以对输入数据x进行预处理, 使用ϕ(x)来代替x, 如下图所示, 而生成式模型不是很方便进行替换.

左图中直接使用x进行逻辑斯蒂回归, 而右图则使用径向基核对x进行变换后再使用逻辑斯蒂回归.
3. 二者所包含的算法
3.1 生成式模型
- 判别式分析
- 朴素贝叶斯
- K近邻(KNN)
- 混合高斯模型
- 隐马尔科夫模型(HMM)
- 贝叶斯网络
- Sigmoid Belief Networks
- 马尔科夫随机场(Markov Random Fields)
- 深度信念网络(DBN)
3.2 判别式模型
- 线性回归(Linear Regression)
- 逻辑斯蒂回归(Logistic Regression)
- 神经网络(NN)
- 支持向量机(SVM)
- 高斯过程(Gaussian Process)
- 条件随机场(CRF)
- CART(Classification and Regression Tree)
参考文献:
[1]. Kevin P. Murphy. Machine Learning: A Probabilistic Perspective, Chapter 8.6, Page267-271.
[2]. Andrew Y. Ng, Micheal I. Jordan. On Discrimintive vs. Generative Classifiers: A comparison of logistic regression and naive Bayes.
[3]. Stack Overflow: What is the difference between a Generative and Discriminative Algorithm?