最近这两天研究了一下SGI STL中的内存池, 网上对于这一块的讲解很多, 但是要么讲的不完整, 要么讲的不够简单(至少对于我这样的初学者来讲是这样的...), 所以接下来我将把我对于对于SGI STL的理解写下来, 方便以后查阅同时也希望能够对像我一样刚刚接触C++的初学者提供一些帮助吧.
首先我们需要明确, 内存池的目的到底是什么? 首先你要知道的是, 我们每次使用new T来初始化类型T的时候, 其实发生了两步操作, 一个叫内存分配, 这一步使用的其实不是new而是operator new(也可以认为就是C语言中的malloc), 这一步是直接和操作系统打交道的, 操作系统可能需要经过相对繁琐的过程才能将一块指向空闲内存的指针返回给用户, 所以这也是new比较耗时的一部分, 而第二步就是使用构造函数初始化该内存, 这是我们比较熟悉的. 既然内存分配耗时, 那我们很容易想到的就是一次性分配一大块内存, 然后在用户需要的时候再划分其中一部分给用户, 这样的话, 一次分配, 多次使用, 自然而然提高了效率, 而用来管理这所谓的一大块内存的数据结构, 也就是今天我们要说的内存池. 另外一个好处在于, 频繁地使用new将导致系统内存空间碎片化严重, 容易导致的后果就是很难找到一块连续的大块内存, 空间利用率低.
那么我们先来看看, 内存池的整体结构 :

该内存池可以认为由上面的一个指针数组和下面的自由链表两部分组成, 指针数组中第一个指针指向的是存放内存大小为8bytes的节点串接而成的自由链表, 之后依次是内存而16bytes, 24bytes直到128bytes, 当然在图中我只画出了一个自由链表. 所以内存池的基本思路在于 :
1. 如果用户分配的内存大于128bytes, 直接用malloc, 否则的话找出适合的自由链表, 从其上摘下一个节点将其头指针返回给用户.
2. 释放过程则正好与分配相对应, 如果用户分配的内存大于128bytes, 直接用free, 否则找出适当的自由链表, 将指针所指的该段内存重新连接到自由链表中(注意此时并不返回给操作系统, 因为之后还可以再重复利用).
这一部分的所对应的代码如下图 :

1 private:
2 static const int Align = 8;
3 static const int MaxBytes = 128;
4 static const int NumberOfFreeLists = MaxBytes / Align;
5 static const int NumberOfAddedNodesForEachTime = 20;
6
7 union node {
8 union node *next;
9 char client[1];
10 };
11
12 static obj *freeLists[NumberOfFreeLists];
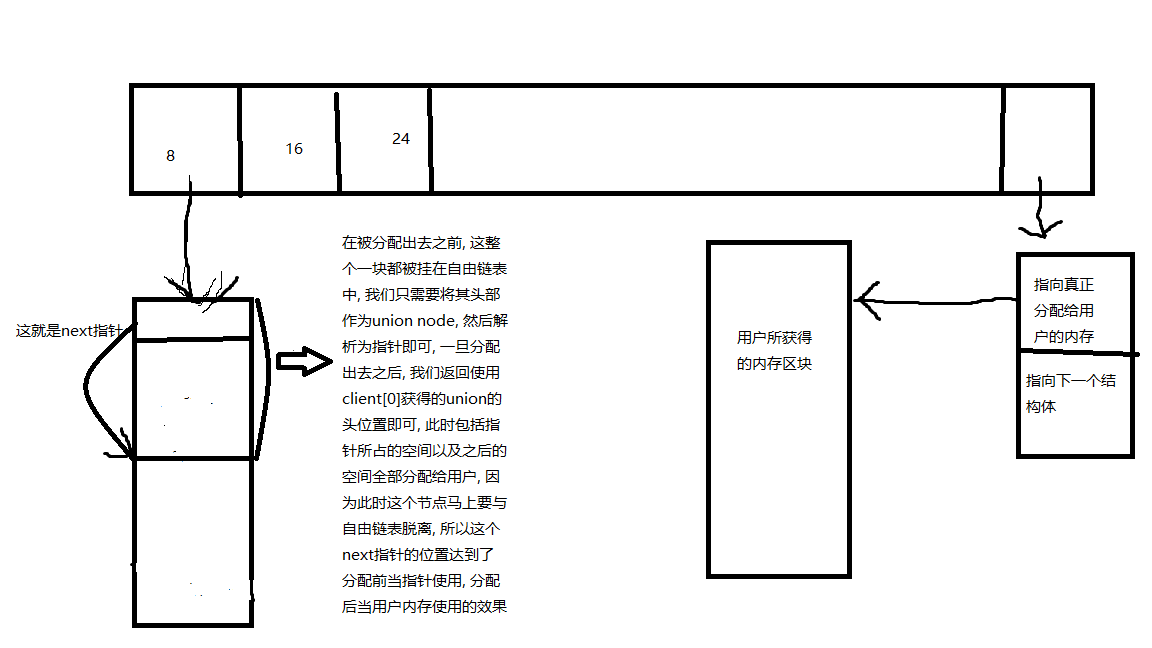
为了便于理解, 我对于源代码中的所以属性名都做了相应的改动, 唯一可能存在疑问的是这个node为什么可以用联合体? 这里我们需要搞清楚这么几点, 自由链表上保存的都是一个一个并未使用的节点, 此时我们为了将所有的node串接起来, 我们当然可以独立分配空间来实现这一功能, 如下图, 比较容易想到的做法可能是这样, 用一个结构体来维护指向真正要分配给用户的内存块以及下一个结构体. 但是这样做有两个缺点 :
1.首先它的每一个node都需要额外多出一个指针的空间来保存真正要分配给用户的内存块的地址
2. 其次在将该内存块分配出去之后, 还需要再处理掉该node对应的结构体.
在分析分配函数的代码之前, 我们先来看看几个辅助函数 :
1 private:
2 static size_t ROUND_UP(size_t size) {
3 return ((size + Align - 1) & ~(Align - 1));
4 }
5
6 static size_t FREELIST_INDEX(size_t size) {
7 return (size + Align - 1) / Align - 1;
8 }
这两个函数作用很简单, 第一个返回的是大于等于输入值的8的倍数, 第二个返回的是可以容纳输入值的最小的自由链表.
接下来就是内存池对外的接口, allocate函数的实现代码.
1 void* alloc::allocate(size_t size) {
2 if (size > MaxBytes) {
3 return malloc(size);
4 }
5
6 size_t index = FREELIST_INDEX(size);
7 node* theMostSuitableNode = freeLists[index];
8 if (theMostSuitableNode) {
9 freeLists[index] = theMostSuitableNode->next;
10 return theMostSuitableNode;
11 }
12 else {
13 return refill(ROUND_UP(size));
14 }
15 }
1. 正如我们前面所讲的, 当用户希望得到size大小的内存空间时候, 此时我们只需要找到能够容纳size的最小的自由链表, 因为自由链表中都是还未分配出去的空间, 如果自由链表中还存在节点的话, 直接将该节点分配出去即可, 也就是这里的theMostSuitableNode不为空的情况, 但此时我们要将数组中指向该自由链表的指针指向下一个Node, 因为这个Node已经分配出去了.
2. 另一方面, 如果自由链表中并没有可用的Node(这里有两种情况会导致没有可用的Node, 第一种是曾经分配过, 但是用光了, 第二种是这是该内存池初始化以来第一次使用这个大小的自由链表, 所以还未分配过空间), 我们直接使用refill函数来填充自由链表, 之所以要用ROUND_UP使得它成为8的倍数, 是因为处于效率原因我们可能会一次性分配不止1个Node(这里是20个), 所以这里的空间必须按照Node的大小来分配.
所以我们顺蔓摸瓜, 接着来看refill的实现代码.
1 void* alloc::refill(size_t size) {
2 size_t num = NumberOfAddedNodesForEachTime;
3 char* block = blockAlloc(size, num);
4 node** currentFreeList = 0;
5 node *curNode = 0, *nextNode = 0;
6
7 if (num == 1) {
8 return block;
9 }
10 else {
11 currentFreeList = freeLists + FREELIST_INDEX(size);
12 *currentFreeList = nextNode = reinterpret_cast<node*>(block + size);
13 for (int i = 1;; ++i) {
14 curNode = nextNode;
15 nextNode = reinterpret_cast<node*>(reinterpret_cast<char*>(curNode) + size);
16 if (num - 1 == i) {
17 curNode->next = 0;
18 break;
19 }
20 else {
21 curNode->next = nextNode;
22 }
23 }
24 return block;
25 }
26 }
先解释一下第二行的blockAlloc, 这个函数的作用是去内存池中寻找size * num大小的空间然后划分给当前的自由链表(也就是currentFreeList), 因为一旦调用了refill说明该自由链表已经没有了可分配的Node, 所以我们这里考虑再分配的时候就直接分配了NumberOfAddedNodesForEachTime个(也就是20个). 但是要注意的话其实这里num传进去的是引用, 为什么传引用呢? 因为还有可能会出现内存池空间不够的情况, 此时如果内存池够1个Node但是不够20个的话, 就会将num设置为1, 说明此时只分配了1个Node空间. 所以可以看到第26行的判断中, 当num为1的时候, 直接将block返回给用户即可. 如果不是1的话, 再返回之前要先将剩下个节点串接在自由链表上. 这也就是那个for循环的作用.
当然在接触到blockAlloc之前, 我们先来看内存池的另外另个熟悉.
1 static char *startOfPool, *endOfPool;
这两个变量分别指向内存池所分配的空间中的起点和终点, 之前说道自由链表里面如果没有node了就到内存池中取, 其实就是从startOfPool开始的位置划出所需要的空间.
最后直接和内存池接触的当然就是blockAlloc了, 所以我们也来看一下这个函数.
1 char* alloc::blockAlloc(size_t size, size_t& num) {
2 char* re = 0;
3 size_t bytesNeeded = size * num;
4 size_t bytesLeft = endOfPool - startOfPool;
5
6 if (bytesLeft >= bytesNeeded) {
7 re = startOfPool;
8 startOfPool = startOfPool + bytesNeeded;
9 return re;
10 }
11 else if (bytesLeft > size) {
12 num = bytesLeft / size;
13 re = startOfPool;
14 startOfPool += num * size;
15 return re;
16 }
17 else {
18 //TODO
19 }
20 }
这里本来有三种情况, 第一种是说如果空间足够(足够分配20个Node那么大), 就直接分配, 然后把指向内存池中空间起始位置的startOfPool移到新的位置, 第二种是虽然不够分配20个, 但是足够分配一个, 此时使用相同的方式, 只不过需要对num进行改动(因为这里num传的是引用, 所以也没什么大问题), 最后一种情况是说连一个Node的内存都拿不出来, 这种情况需要再向系统申请内存, 我将在下面详细说明. 这里我们先来理一理, 目前的情况...
1. 使用allocate向内存池请求size大小的内存空间.
2. allocate根据size找到最适合的自由链表.
a. 如果链表不为空, 返回第一个node, 链表头改为第二个node.
b. 如果链表为空, 使用blockAlloc请求分配node.
x. 如果内存池中有大于一个node的空间, 分配竟可能多的node(但是最多20个), 将一个node返回, 其他的node添加到链表中.
y. 如果内存池只有一个node的空间, 直接返回给用户.
z. 若果如果连一个node都没有, 再次向操作系统请求分配内存(这就是上面代码中的TODO部分).
然后我们还能发现内存池的几个特点 :
1. 刚开始初始化内存池的时候, 其实内存池中并没有内存, 同时所有的自由链表都为空链表.
2. 只有用户第一次向内存池请求内存时, 内存池会依次执行上述过程的 1->2->b->z来完成内存池以及链表的首次填充, 而此时, 其他未使用链表仍然是空的.
有了这个整体的了解之后, 我们现在就来看一下, 内存池是如何向操作系统申请内存的 :
1 char* alloc::blockAlloc(size_t size, size_t& num) {
2 char* re = 0;
3 size_t bytesNeeded = size * num;
4 size_t bytesLeft = endOfPool - startOfPool;
5
6 if (bytesLeft >= bytesNeeded) {
7 re = startOfPool;
8 startOfPool = startOfPool + bytesNeeded;
9 return re;
10 }
11 else if (bytesLeft > size) {
12 num = bytesLeft / size;
13 re = startOfPool;
14 startOfPool += num * size;
15 return re;
16 }
17 else {
18 // I am not sure why add ROUND_UP(poolSize >> 4)
19 size_t bytesToGet = 2 * bytesNeeded + ROUND_UP(poolSize >> 4);
20 if (bytesLeft > 0) {
21 node** theMostSuitableList = freeLists + FREELIST_INDEX(bytesLeft);
22 (reinterpret_cast<node*>(startOfPool))->next = *theMostSuitableList;
23 *theMostSuitableList = reinterpret_cast<node*>(startOfPool);
24 }
25
26 startOfPool = (char*)malloc(bytesToGet);
27 if (!startOfPool) {
28 node** currentFreeList = 0;
29 node* listHeadNode = 0;
30 for (int i = size + Align; i <= MaxBytes; i += Align) {
31 currentFreeList = freeLists + FREELIST_INDEX(i);
32 listHeadNode = *currentFreeList;
33 if (listHeadNode) {
34 *currentFreeList = listHeadNode->next;
35 startOfPool = reinterpret_cast<char*>(listHeadNode);
36 endOfPool = reinterpret_cast<char*>(listHeadNode + i);
37 return blockAlloc(size, num);
38 }
39 }
40 //if code can run into this place, it means we can no longer get any memeory, so the best way is to throw exception...
41 exit(3);
42 }
43 else {
44 poolSize += bytesToGet;
45 endOfPool = startOfPool + bytesToGet;
46 return blockAlloc(size, num);
47 }
48 }
49 }
你会发现空间不足的时候, 首先计算了所需要的内存就是这个bytesToGet, 我在代码中也提到了我也不太清楚后面为什么要加上一个round_up(...), 然后是把当前剩余的内存(如果有剩余的话)分配给合适的节点, 因为每次分配内存都是8的倍数, 所以只要有剩余, 也肯定是8把的倍数, 所以一定能找到合适的节点. 接着就开始分配内存, 如果分配内存失败的话, 那么从size + Align开始(其实源代码好像是从size开始, 但是我感觉此时存有size大小node的自由链表显然是空的, 不然也不会调用这个函数, 所以就直接size + align 开始了), 如果能从那些位置挪出一个node的话(显然挪出来的node要更大), 那么就可以完成分配了, 如果遍历了所有比size大的节点都寻找不到这样一块node的话, 正如我代码中所说的, 运行到那个位置就应该抛异常了. 另外如果分配成功, 更新相应的变量之后, 再次调用该函数进行分配, 此时内存池中有足够的内存分配给自由链表.
早这里关于内存的分配的全过程就讲完了, 下面是内存的释放 :
1 void alloc::deallocate(void* ptr, size_t size) {
2 if (size > MaxBytes) {
3 free(ptr);
4 }
5 else {
6 size_t index = FREELIST_INDEX(size);
7 static_cast<node*>(ptr)->next = freeLists[index];
8 freeLists[index] = static_cast<node*>(ptr);
9 }
10 }
内存的释放很简单, 如果大于128bytes的, 直接释放(因为也是直接分配过来的), 否则把它挂到相应的链表中, 留待之后使用.
到这里, 内存池的实现就算全部讲完了, 但是在真正将它投入到stl的实际使用中之前, 还要进行一层封装.
public:
typedef T value_type;
typedef T* pointer;
typedef const T* const_pointer;
typedef T& reference;
typedef const T& const_reference;
typedef size_t size_type;
typedef ptrdiff_t difference_type;
public:
static T *allocate();
static T *allocate(size_t n);
static void deallocate(T *ptr);
static void deallocate(T *ptr, size_t n);
static void construct(T *ptr);
static void construct(T *ptr, const T& value);
static void destroy(T *ptr);
static void destroy(T *first, T *last);
};
template<class T>
T *allocator<T>::allocate(){
return static_cast<T *>(alloc::allocate(sizeof(T)));
}
template<class T>
T *allocator<T>::allocate(size_t n){
if (n == 0) return 0;
return static_cast<T *>(alloc::allocate(sizeof(T) * n));
}
template<class T>
void allocator<T>::deallocate(T *ptr){
alloc::deallocate(static_cast<void *>(ptr), sizeof(T));
}
template<class T>
void allocator<T>::deallocate(T *ptr, size_t n){
if (n == 0) return;
alloc::deallocate(static_cast<void *>(ptr), sizeof(T)* n);
}
template<class T>
void allocator<T>::construct(T *ptr){
new(ptr)T();
}
template<class T>
void allocator<T>::construct(T *ptr, const T& value){
new(ptr)T(value);
}
template<class T>
void allocator<T>::destroy(T *ptr){
ptr->~T();
}
template<class T>
void allocator<T>::destroy(T *first, T *last){
for (; first != last; ++first){
first->~T();
}
}
}
这也就是我们熟悉的标准库中的allocator的接口...
所以最终内存池的思路其实是这样的:
1. 使用allocate向内存池请求size大小的内存空间, 如果需要请求的内存大小大于128bytes, 直接使用malloc.
2. 如果需要的内存大小小于128bytes, allocate根据size找到最适合的自由链表.
a. 如果链表不为空, 返回第一个node, 链表头改为第二个node.
b. 如果链表为空, 使用blockAlloc请求分配node.
x. 如果内存池中有大于一个node的空间, 分配竟可能多的node(但是最多20个), 将一个node返回, 其他的node添加到链表中.
y. 如果内存池只有一个node的空间, 直接返回给用户.
z. 若果如果连一个node都没有, 再次向操作系统请求分配内存.
①分配成功, 再次进行b过程
②分配失败, 循环各个自由链表, 寻找空间
I. 找到空间, 再次进行过程b
II. 找不到空间, 抛出异常(代码中并未给出, 只是给出了注释)
3. 用户调用deallocate释放内存空间, 如果要求释放的内存空间大于128bytes, 直接调用free.
4. 否则按照其大小找到合适的自由链表, 并将其插入.
特点其实是这样的 :
1. 刚开始初始化内存池的时候, 其实内存池中并没有内存, 同时所有的自由链表都为空链表.
2. 只有用户第一次向内存池请求内存时, 内存池会依次执行上述过程的 1->2->b->z来完成内存池以及链表的首次填充, 而此时, 其他未使用链表仍然是空的.
3. 所有已经分配的内存在内存池中没有任何记录, 释放与否完全靠程序员自觉.
4. 释放内存时, 如果大于128bytes, 则直接free, 否则加入相应的自由链表中而不是直接返还给操作系统.
以上是我对于sgi stl内存池的理解, 如果有任何不对的地方, 欢迎指出, 谢谢...