神经网络+增强学习
马里奥AI实现方式探索 ——神经网络+增强学习
儿时我们都曾有过一个经典游戏的体验,就是马里奥(顶蘑菇^v^),这次里约奥运会闭幕式,日本作为2020年东京奥运会的东道主,安倍最后也已经典的马里奥形象出现。平时我们都是人来玩马里奥游戏,能否可以让马里奥智能的自己闯关个呢?OK,利用人工智能的相关算法来进行自动化通关一直是一个热门的话题,最近最火的相关东东就是传说中的alphaGo啦。而在游戏的自动化测试当中,这种算法也是非常实用的,可以大量的减少测试人力成本。
首先,对于实现马里奥AI当中涉及到的神经网络和增强学习的相关概念进行整理,之后对智能通关的两种方式进行阐述。(本人才疏学浅,在神经网络和增强学习方面基本门外汉,如有任何纰漏,还请大神指出,我会第一时间改正。)
神经网络
像飞机的灵感来源于鸟类,雷达的灵感来源于蝙蝠,红外线的灵盖来源于蛇,而本文要讨论的神经网络灵感来源于我们自己,人类大脑的神经元结构。从神经元结构被提出,到时下火热的无以复加的深度神经网络,发展过程也可为一波三折。我们按照时间的顺序,对一些经典的神经网络模型进行整理:
M-P模型
40年代初心理学家 W.W.Mcculloch 和梳理逻辑家 W.Pitts 提出 M-P 模型(为啥叫M-P模型,看看这两位大牛的名字,也不考虑下我们非英语系国家人民的感受。。。),神经网络被引入到计算机领域当中,其最初起源的灵感就是人类大脑中的神经元,如下图: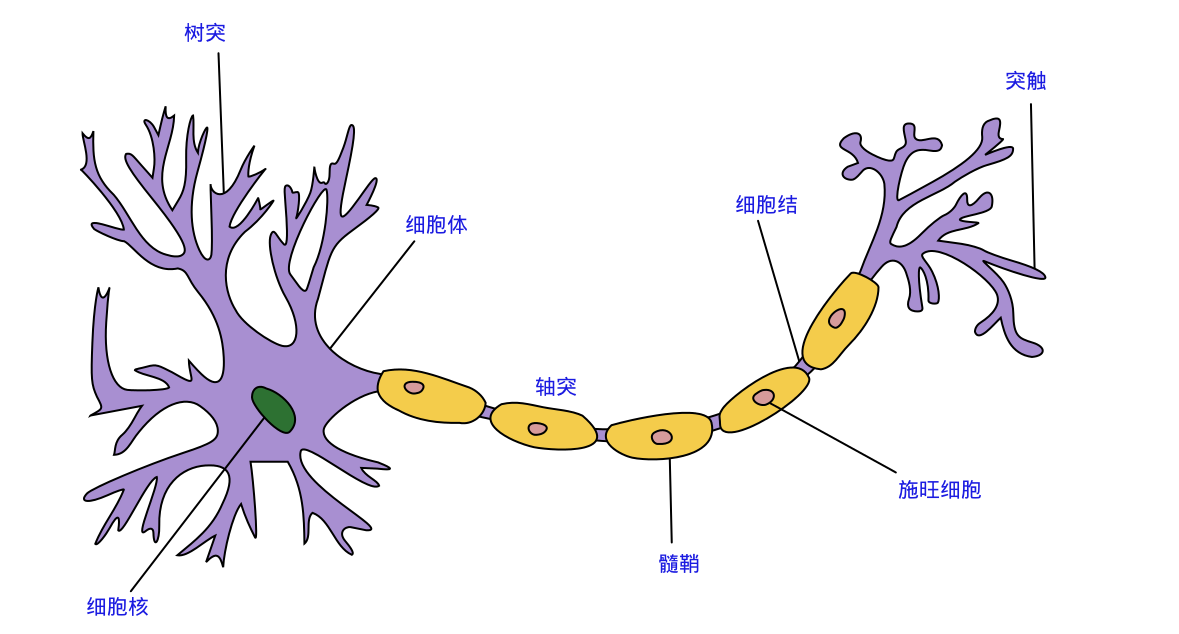
生物学上具体的专业术语我们这里不展开描述,我们总结一下神经元结构的特点:
- 每个神经元都是一个多输入单输出的信息处理单元;
- 神经元输入分兴奋性输入和抑制性输入两种类型;
- 神经元具有空间整合特性和阈值特性;
- 神经元输入与输出间有固定的时滞,主要取决于突触延搁。
由此两位大牛提出了神经网络的早期M-P模型,如下图: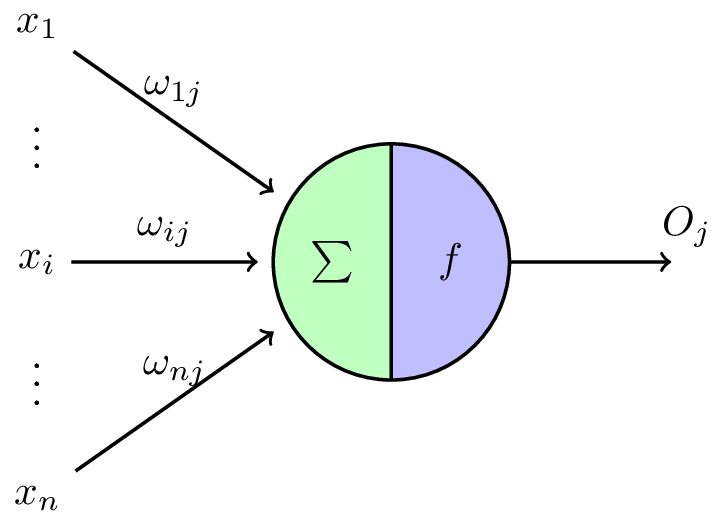
该模型的基本思想很简单,就是仿照神经元接受多个输入信号,由于突触的性质和突触强度不同,所以对神经元的影响程度不同,我们加上了权重的概念,其正负模拟了神经元中的兴奋和抑制作用,最后所有信号累加整合,其值为: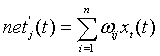
输入信号有了,神经元是否被激活,要看输入信号是否超过了某一阈值电位,如果被激活神经元输出脉冲,否则神经元不会输出信号,其过程如下函数: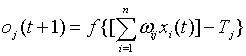
当然这里我们也可以写成矩阵的形式
类似神经元结构的特点,经典的M-P模型的特点可以总结如下:
- 每个神经元都是一个多输入单输出的信息处理单元;
- 神经元输入分兴奋性输入和抑制性输入两种类型;
- 神经元具有空间整合特性和阈值特性;
- 神经元输入与输出间有固定的时滞,主要取决于突触延搁;
- 忽略时间整合作用和不应期;
- 神经元本身是非时变的,即其突触时延和突触强度均为常数。(神经网络中权重在训练结束后是固定的)
结合两个公式来看这几个特点:对于特点1,我们的公式有多个x输入信号,但我们的输出信号只有一个o;权重的正负体现了特点2中输入分兴奋和抑制;对于第3个特点,我们第2个公式中只有当输入信号的累加和超出电位阈值才会有输出;另外我们的公式只考虑了所有输入信号的整合,并没有去考虑时间整合(就是不管你信号早到晚到,只要到了都是好信号),体现了特性4和5。
随着M-P模型的提出,神经网络的研究有三次兴起,最近的一次就是随着卷积神经网络提出的深度学习的火热。
早期神经网络
M-P模型很简单,仅仅是一种单个神经元上的建模,并没有形成网络,没法去完成一些特定的任务。由此人们提出了神经网络的概念,而早期的研究,由于当时硬件水平和计算条件的限制,神经网络结构一般比较简单。
两层神经网络
由此1958年,计算科学家Rosenblatt提出了由两层神经元组成的神经网络。他给它起了一个名字“感知器”(Perceptron)
其结构如下图: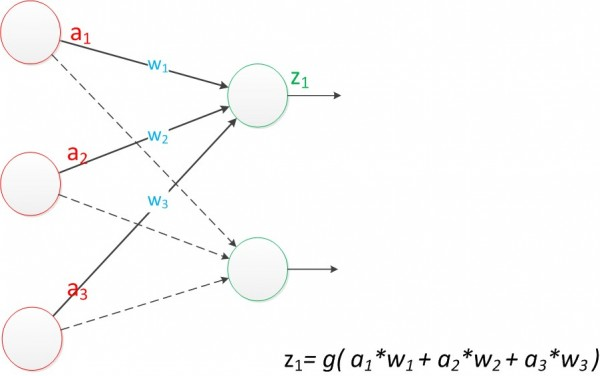
这种简单的单层神经网络有点类似于逻辑回归,通过简单的权重训练,能够处理简单的线性分类问题,类似下图: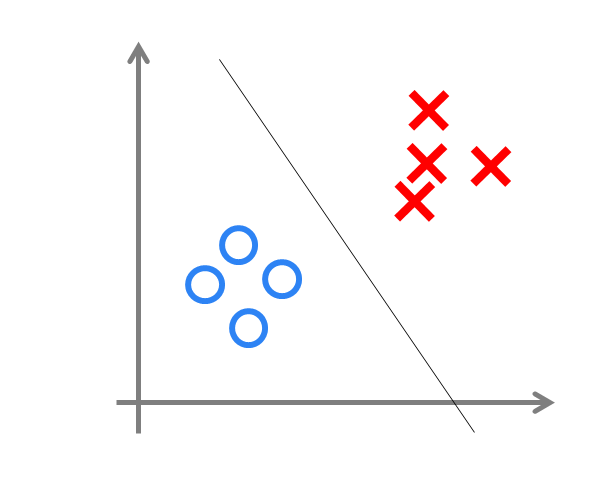
而对于非线性的分类问题(如经典的异或问题)却无能为力,后来研究人员也发现了这一点,神经网络研究遍进入了低谷期(好伤心TT)
三层神经网络(带有隐层)
问题总是用来解决的嘛,既然两层神经网络hold不住非线性分类问题,那么我们就加一层,称为隐含层,由此而来的三层神经网络如下图: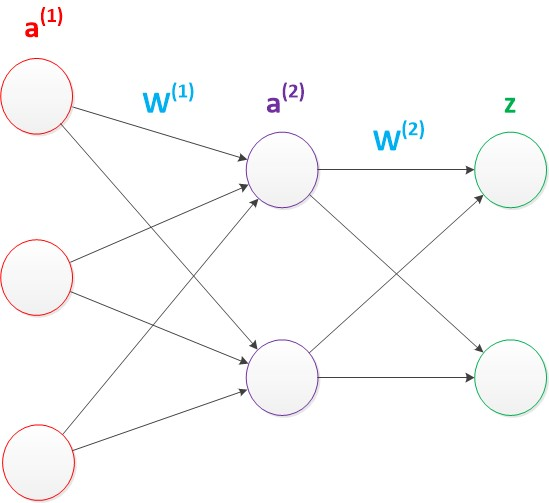
这种三层神经网络具有非常好的非线性分类效果,其计算公式如下: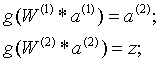
当然啦,就像我们平时的逻辑回归模型一样,bias在模型中是必不可少的,所以我们在原有结构上加入偏置节点,结构图如下: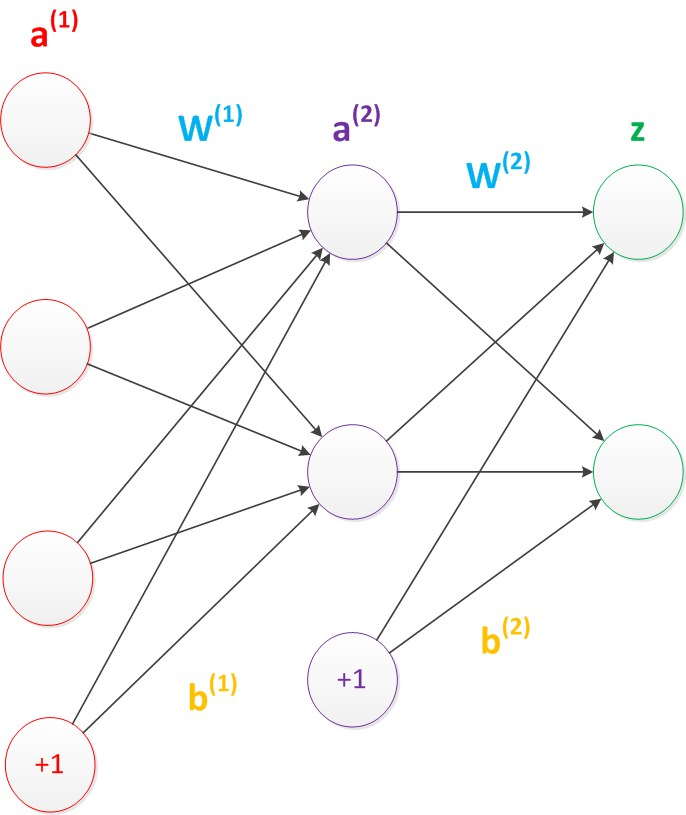
神经网络中偏置节点是默认存在的,而且它非常特殊,就是没有输入,并且会输出的后一层的所有节点。加入偏置节点后计算公式如下:(一般情况下,偏置节点不会被画出来)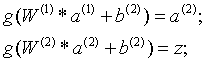
与两层神经网络不同,理论证明三层神经网络能够无限逼近任意连续函数。这里我们不禁会有疑问,我们知道两层神经网络是线性分类问题,那么两个线性问题拼在一起为什么就可以解决非线性分类问题了呢?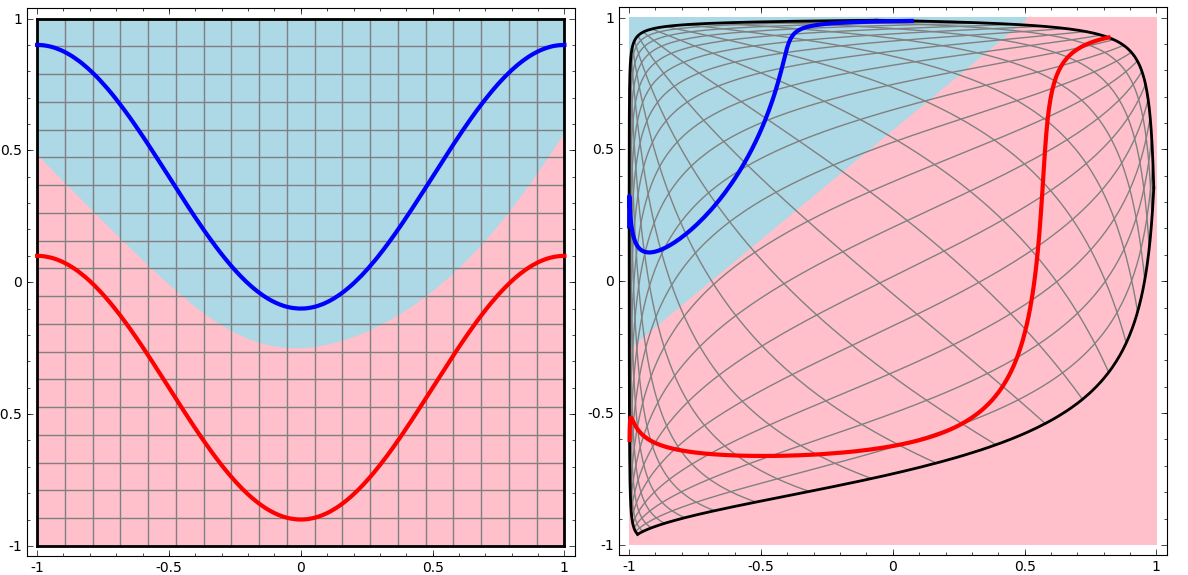
上图很好的解释了我们的疑问。首先上图左侧部分可以看出,三层神经网络的决策分界非常平滑,而且分类的很好。而上图右侧部分展示了该图经过空间变换后的结果,我们可以看到输出层的决策分界仍然是直线,关键是,从输入层到隐含层时,发生了空间变换。
也就是说三层神经网络可以做非线性分类的关键便是隐含层的加入,通过矩阵和向量相乘,本质做了一次线性变换,使得原先线性不可分的问题变得线性可分。所以多层神经网络本质就是复杂函数的拟合。
现在三层神经网络结构定了,如何来进行网络的训练,这就需要用到反向传播算法(本质就是梯度下降,还说的这儿玄乎<-T->)
BP算法
上面我们提到两层神经网络,其中隐层的权值是需要我们学习的,而这个权值我们不能直接获取,所以我们利用输出层得到输出结果和期望输出的误差来间接调整隐层的权值。BP算法的学习过程由信号的正向传播和误差的反向传播两个过程组成。
- 正向传播时,输入样本从输入层传入,经各隐层逐层处理后,传向输出层。若输出层的实际输出与期望的输出(教师信号)不符,则转入误差的反向传播阶段。
- 反向传播时,将输出以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号,此误差信号即作为修正各单元权值的依据。
下图展示了整个BP算法的信号流程图: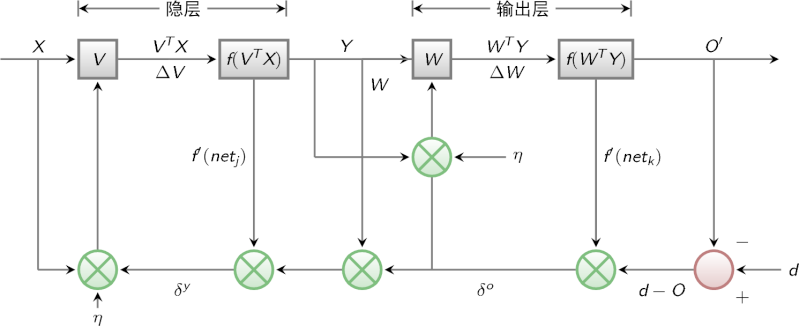
BP网络有三个要素:
- 网络拓扑结构
- 传递函数
- 学习算法
网络拓扑结构便是我们之前总结的两层神经网络结构,我们主要从传递函数和学习算法进行整理阐述下。
传递函数
首先什么是传递函数呢?请看下图: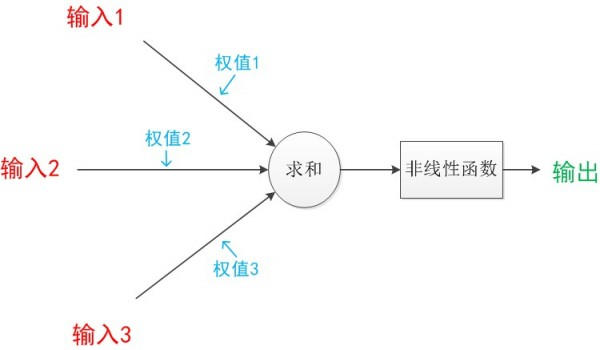
图中是最基本的单个神经元的模型,针对于多个输入,我们会进行整合并利用一个非线性函数进行输出,函数的要求必须是可微单调递增函数,通常采用非线性变换函数———sigmoid函数也称S函数(形状),有单极性S型函数和双极性S型函数两种(高中数学里的东东)。
-
单极性S型函数定义如下:
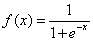
函数曲线图如下(似乎不够S。。)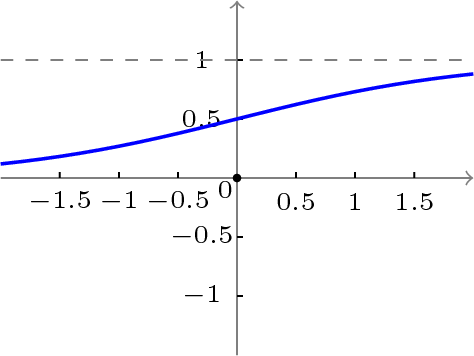
-
双极性S型函数定义如下:
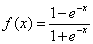
函数曲线图如下: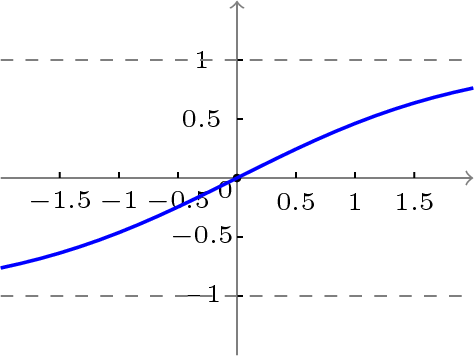
可以看出根据上面的S函数,我们会整合所有输入,输出一个新的值,从之前生物学的原理来看也就是说神经元是否被激活。
学习算法
学习算法是BP神经网络结构的核心,也是两层神经网络有一次兴起的重要原因,因为人们找到了如何去训练一个神经网络来达到我们预期的分类效果(拟合不同的非线性连续函数)。而BP算法(反向传播算法)的本质其实就是一种逐层梯度下降。
我们以三层感知器为例,当网络输出与期望输出不一致时,存在误差E,定义如下: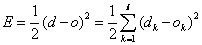
将以上误差反向逐层展开(体现了反向传播算法中的反向含义)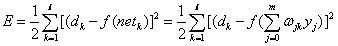
最终我们展开到输入层如下: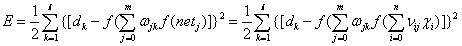
根据上式我们发现误差E是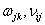 的函数,我们发现调整权值可以改变误差E的大小,而调整权值的原则是使得误差不断减小。因此我们应该使得权值与误差的梯度下降成正比,如下:
的函数,我们发现调整权值可以改变误差E的大小,而调整权值的原则是使得误差不断减小。因此我们应该使得权值与误差的梯度下降成正比,如下: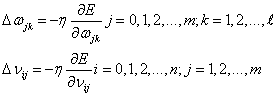
其中值得注意的是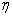 表示学习效率,即权重调整的幅度。
表示学习效率,即权重调整的幅度。
我们可以看出对于权重的调整是从输出层逐层反传过来的,而且我们也发现我们在梯度下降的过程中需要求导,这也就是我们在最初要求传递函数可微的原因
深度神经网络
有三层神经网络,我们自然而然就会想到将神经网络加入更多层,扩展到深度神经网络,但是一个非常显著的问题就是参数的个数,比如之前我们的三层神经网络每层有1000个节点,那么我们需要调整的权值参数就达到了10^9量级,这问题限制了很大程度上限制了深度神经网络的发展。这就要把大哥叫出来帮忙了,就是近期一直火热的deep learning,由于本人在这方面也是门外汉,只从经典的卷积神经网络(CNN)进行一些归纳整理。
CNN的解决之道
根据网上的资料总结,CNN的核心点有三个:
-
局部感知:形象地说,就是模仿你的眼睛,想想看,你在看东西的时候,目光是聚焦在一个相对很小的局部的吧?严格一些说,普通的多层神经网络,隐层节点会全连接到一个图像的每个像素点上,而在卷积神经网络中,每个隐层节点只连接到图像某个足够小局部的像素点上,从而大大减少需要训练的权值参数。我们用两张对比图来说明下:
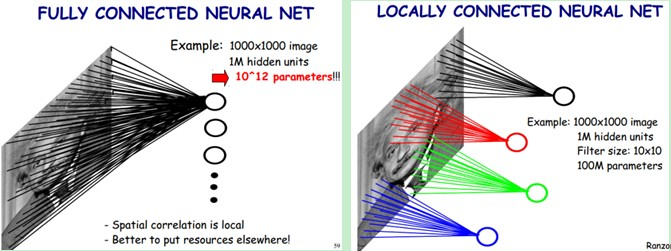
从图中我们可以看出,对于一张1000×1000像素的图片,假设神经网络中的隐节点有1M个。对于传统的深度神经网络,所有的隐节点会连接到图像中的每个像素点,那么我们需要训练的权重参数就达到了匪夷所思的10^12量级。而CNN提出局部感知,即图中右侧展示的,每个神经元只与10×10个像素值相连,那么我们的权重参数就下降到10^8,参数数量为原来的万分之一(虽然还是很多TT) -
权值共享:形象地说,就如同你的某个神经中枢中的神经细胞,它们的结构、功能是相同的,甚至是可以互相替代的。局部感知的方式在一定程度上减少了参数,那么另一个减少参数的神器便是权值共享。在上面我们提到的局部感知的例子中,对于1M个神经元,每个神经元需要局部感知10×10个像素点,那么参数个数是100×1M个,那么如果我们在这里假设每个神经元的权重参数都是相同的,那么我们的参数个数就会骤减到100个,很夸张对不拉,做到这一步的神器便是卷积操作。
权值共享基于的原理或者说假设是图像中局部的统计特征与其他部分是一样的,也就意味着假设我们在图像的局部学习到了一组特征,那么我们可以直接将这组特征应用到图像的其它部分。就拿上面的例子来看,我们假设在第一个神经元中学习到了局部10×10像素点的特征,那么我们完全可以将这个特征应用在图像的其他位置上,那么我们另外的1M-1的神经元权重参数就不需要训练了,所以我们只需要训练第一个神经元的权重参数即可,而这第一个神经元得到的局部特征称为卷积核。当然啦,我们不会这么变态的只用一个卷积核,这样对于图像特征的提取也是不充分的,所以往往CNN中都会有多个卷积核来进行卷积操作,每个卷积核会提取出图像某一方面的特征。如下图展示了卷积操作的基本原理: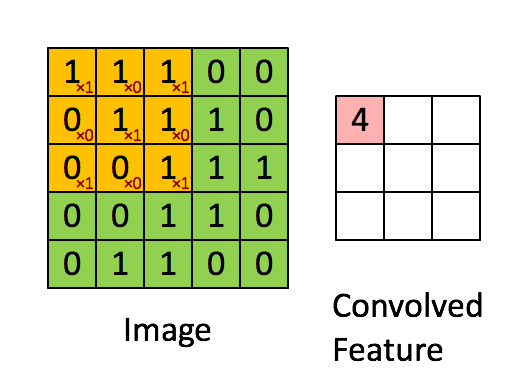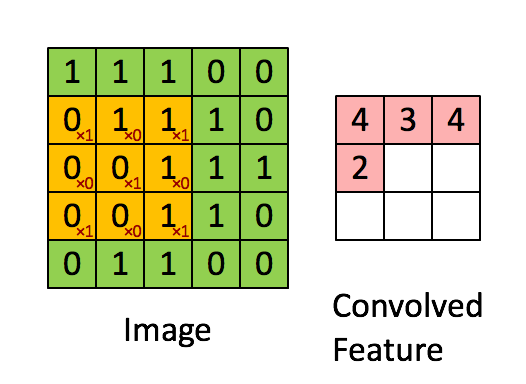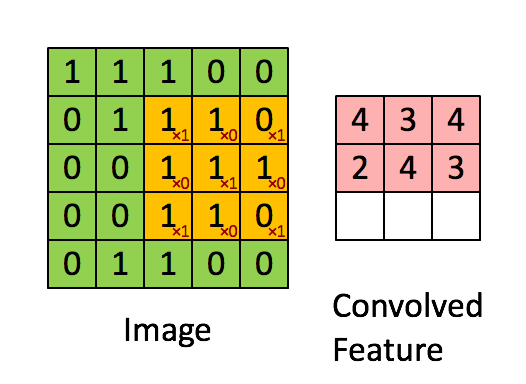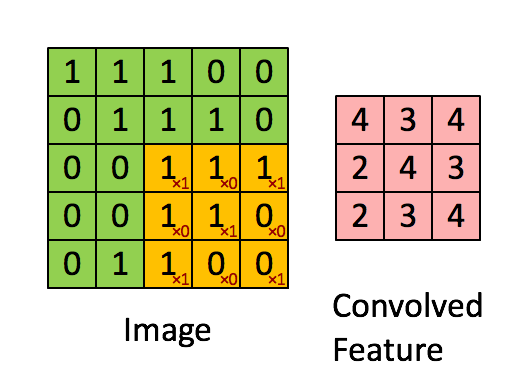
图中展示了一个3×3的卷积核在5×5的图像上做卷积的过程。每个卷积都是一种特征提取方式,就像一个筛子,将图像中符合条件(激活值越大越符合条件)的部分筛选出来。 -
池化:形象地说,你先随便看向远方,然后闭上眼睛,你仍然记得看到了些什么,但是你能完全回忆起你刚刚看到的每一个细节吗?不能(也没必要),我们通常会提取整个图像中一些关键的点作为一种“映像”放到脑海中。同样,在卷积神经网络中,通过卷积获得了特征之后,下一步我们需要利用这些特征去做分类,当然我们可以利用所有这些特征去做分类(如softmax分类器),但同样的这里又会遇到我们的老问题,计算量过大。所以,在进行分类之前,我们利用人类判别图片记录关键特征的原理,同样在处理卷积层输出的特征时,我们也可以做一些“压缩”或者说提取处理,这种方法被称为池化(Down-pooling)。以最大池化(Max Pooling)为例,1000×1000的图像经过10×10的卷积核卷积后,得到的是991×991的特征图(参考上图5×5图像经过卷及操作变成了3×3的图像),然后使用2×2的池化规模,即每4个点组成的小方块中,取最大的一个作为输出,最终得到的是496×496大小的特征图。池化得原理我们可以用下图形象的说明:
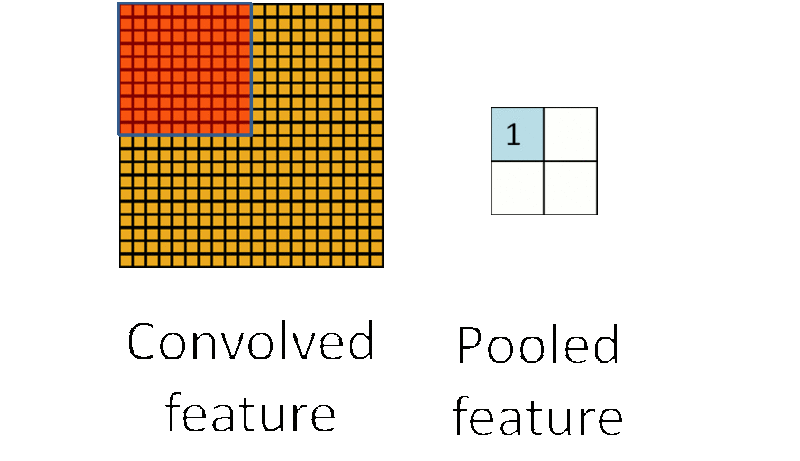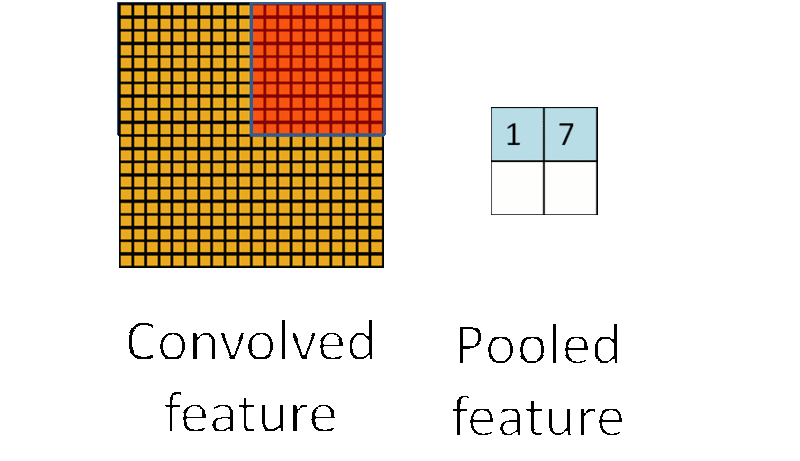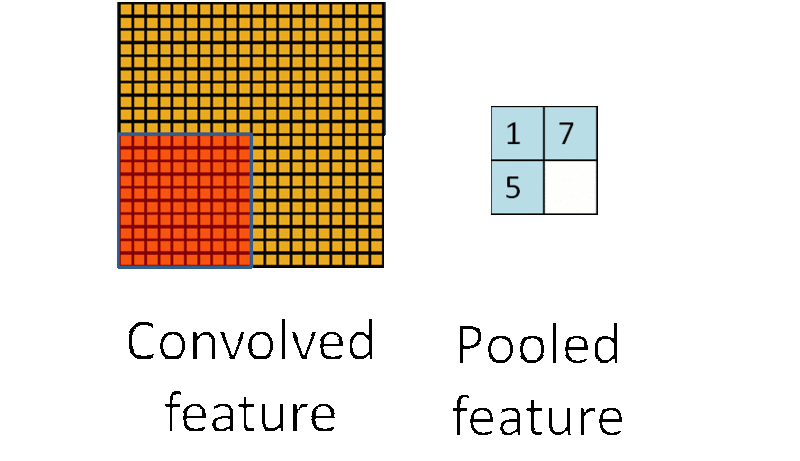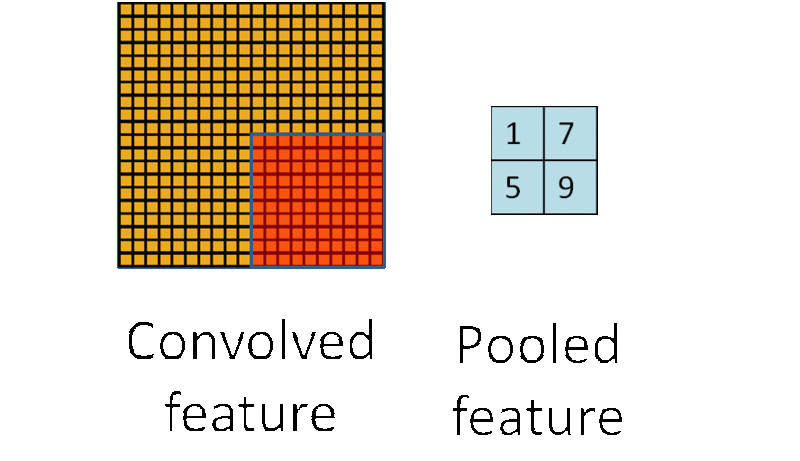
CNN整体结构
上面我们从CNN的三个核心点出发,阐述了CNN的基本原理,下图我们列出了CNN的整体结构: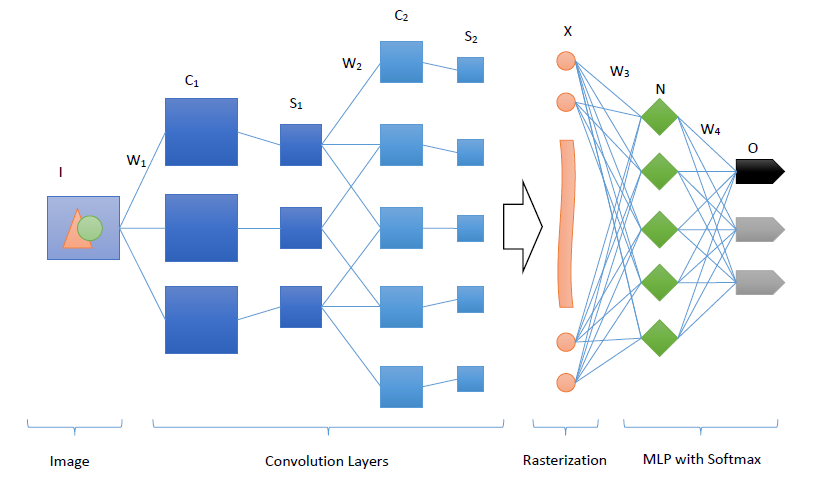
图中从左至右描述了CNN神经网络的几个不同层
- 输入层(图像):在CNN神经网络的输入当中,一般为了减少复杂度,往往采用灰度化后的图像作为输入,而如果使用RGB的彩色图像,那么输入会分为RGB三个分量图像。输入图像一般都需要归一化,常规的可以使用我们前面阐述的sigmoid函数,归一化到[0,1],如果使用tanh激活函数,则归一化到[-1, 1]。这一部分我们涉及到了我们上面阐述的局部感知的方式来减少参数。
- 多个卷积(C)-下采样(S)层:将上一层的输出与本层权重W做卷积得到各个C层,然后下采样得到各个S层,这一部分主要涉及了我们上面阐述的三个核心点中的卷积和池化操作,而这些层的输出称为Feature Map。
- 光栅化(X):是为了与传统的多层感知器全连接。即将上一层的所有Feature Map的每个像素依次展开,排成一列。
- 传统的多层感知器(N&O):最后的分类器一般使用Softmax,如果是二分类,当然也可以使用逻辑回归LR。
至此关于CNN的基本原理基本阐述完毕啦,关于CNN的参数训练等内容这里不再赘述,可以参考Deep learning:五十一(CNN的反向求导及练习)
总结
~长出一口气~,从最一开始单个神经元模型的提出,到两层和三层的简单神经网络,再到时下火热的深度学习,我们可以用下图从时间上进行一个大致的梳理: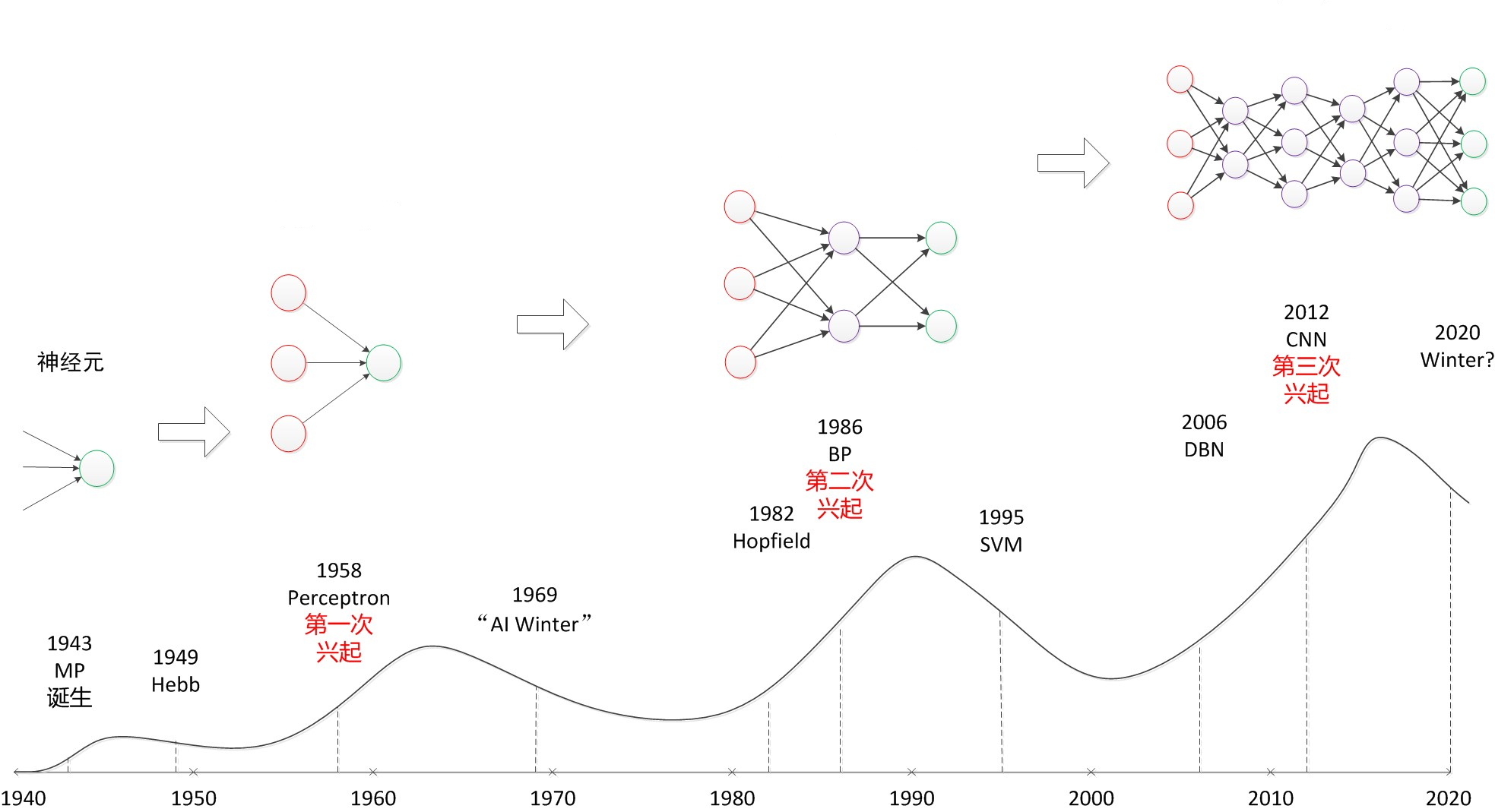
我们可以看到,神经网络的发展经历了三次跌宕起伏:
- 感知器:第一次兴起的研究点便是科研人员利用两层神经网络(起了个玄乎的名字感知器)进行了简单的分类问题,当时的人们大呼找到了人工智能的奥秘,从而兴起了对神经网络的研究,但是随着众多学者发现两层感知器只能完成最简单的线性分类问题,对于经典的异或分类问题都无法完成时,神经网络陷入低谷。
- BP算法:第二次兴起的关键点便是BP算法的提出,当人们发现两层神经网络无法胜任非线性分类问题时,已经想到了增加神经网络层数,但是随着网络层数的增加,权重参数如何训练的问题无法解决,直到BP反向传播算法的提出,解决了这一问题,从而发生了神经网络的又一次兴起。但是随之而来的其它算法,如SVM,等算法的提出,人们发现这些算法的通用性和可计算性都优于神经网络,神经网络进入到了第二次低谷。
- 深度学习:第三次兴起的关键点便是时下火热的深度学习了,它的标致之一便是CNN卷积神经网络的提出,将它用于图像分类问题当中(当然了这也离不开硬件水平的提高,比如高并行的GPU诞生)。
而对于每次神经网络可解决的问题,我们可以用下图来阐述: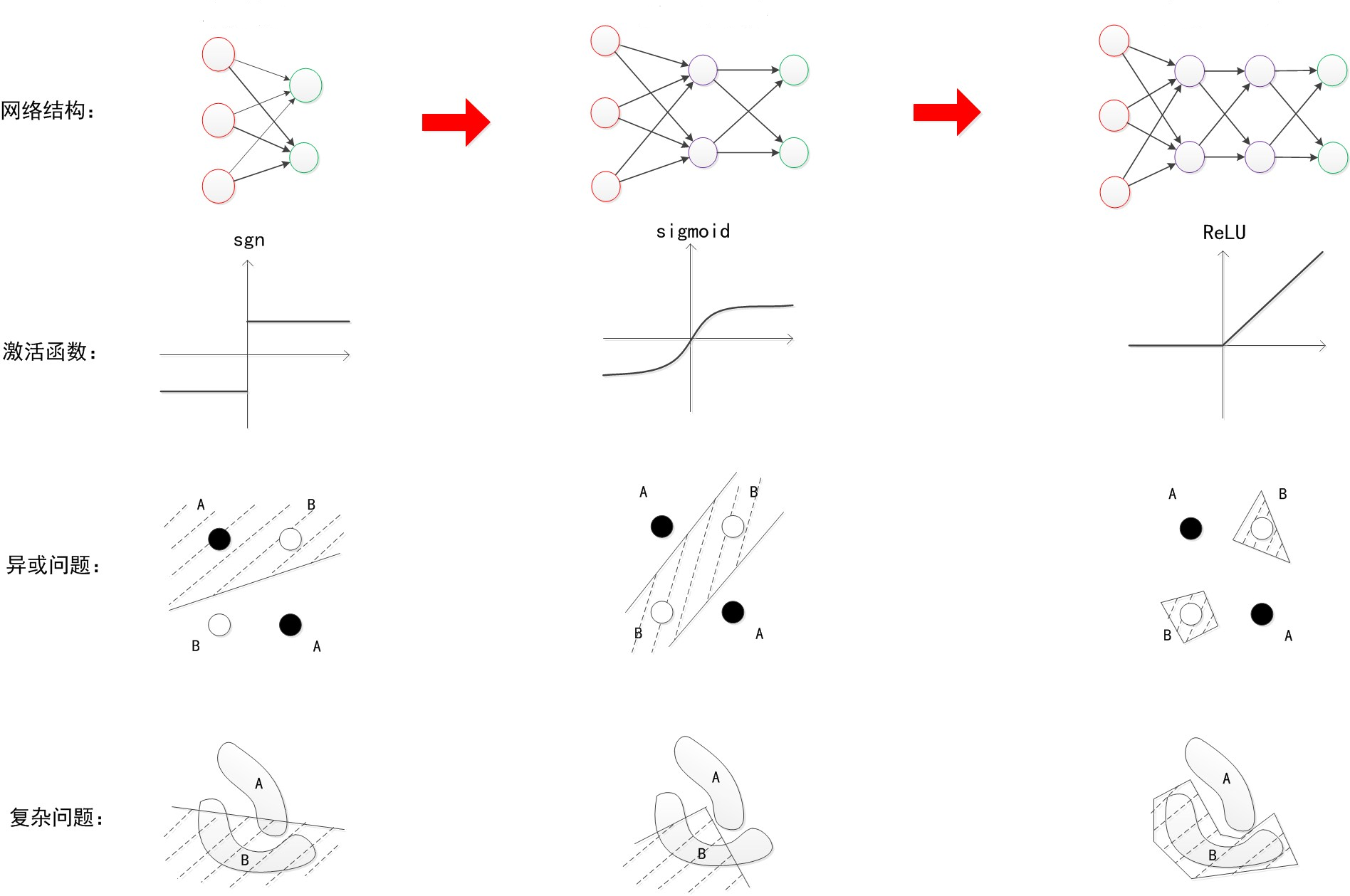
上图中我们可以看出,随着神经网络的发展,我们在解决最基本的分类问题时的效果越来越好,这也是神经网络的魅力所在啦^v^。当然在神经网络发展的过程当中,计算机硬件水平的发展也是不容忽视的,随着计算能力和性能的提高,原来不可能实现的想法、算法都能付诸实践进行试验。
增强学习
机器学习领域,我们都知道两位大哥就是监督学习和非监督学习,我们有样本X和标记或者未标记的Y,我们通过训练可以做一些分类或者聚类的任务。但是,对于一些序列决策或者控制问题,是很难得到上面那样的规则样本的,比如机器人的控制问题,决策机器人下一步该怎么走,那么这时我们就需要清楚另外一位大哥——增强学习,虽然他似乎曝光度并不是很高,那么何谓增强学习呢?
增强学习(Reinforcement Learning, RL),其英文定义如下:
Reinforcement learning is learning what to do ----how to map situations to actions ---- so as to maximize a numerical reward signal.[6]
也就是说增强学习关注的是智能体如何在环境中采取一系列行为,从而获得最大的累积回报。
通过增强学习,一个智能体(agent)应该知道在什么状态下应该采取什么行为。RL是从环境状态到动作的映射的学习,我们把这个映射称为策略。
马尔可夫决策过程(MDP)
一提到马尔科夫,大家通常会立刻想起马尔可夫链(Markov Chain)以及机器学习中更加常用的隐式马尔可夫模型(Hidden Markov Model, HMM)。它们都具有共同的特性便是马尔可夫性:当一个随机过程在给定现在状态及所有过去状态情况下,其未来状态的条件概率分布仅依赖于当前状态;换句话说,在给定现在状态时,它与过去状态(即该过程的历史路径)是条件独立的,那么此随机过程即具有马尔可夫性质。具有马尔可夫性质的过程通常称之为马尔可夫过程。[7]
之后我们便来说说马尔可夫决策过程(Markov Decision Process),其也具有马尔可夫性,与上面不同的是MDP考虑了动作,即系统下个状态不仅和当前的状态有关,也和当前采取的动作有关。
用表格描述马尔可夫各个模型的关系(摘自[8])
基本定义
一个马尔可夫决策过程由五元组组成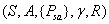
- S:表示状态集(states)
- A:表示一系列动作(actions)
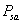 :表示状态转移概率。表示的是在当前s ∈ S状态下,经过a ∈ A作用后,会转移到的其他状态的概率分布情况。比如,在状态s下执行动作a,转移到s'的概率可以表示为p(s'|s,a)。
:表示状态转移概率。表示的是在当前s ∈ S状态下,经过a ∈ A作用后,会转移到的其他状态的概率分布情况。比如,在状态s下执行动作a,转移到s'的概率可以表示为p(s'|s,a)。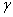 (dicount factor):表示阻尼系数[0,1)
(dicount factor):表示阻尼系数[0,1)- R:
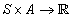 ,表示回报函数(reward function)
,表示回报函数(reward function)
MDP 的动态过程如下:某个智能体(agent)的初始状态为s0,然后从 A 中挑选一个动作a0执行,执行后,agent 按概率随机转移到了下一个s1状态,s1∈ 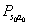
。然后再执行一个动作a1,就转移到了s2,接下来再执行a2…,我们可以用下面的图表示状态转移的过程。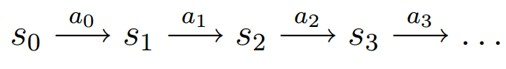
如果回报r是根据状态s和动作a得到的,则MDP还可以表示成下图: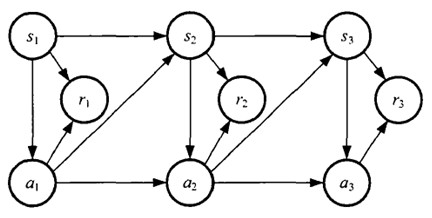
值函数
上面我们给出了MDP的定义,作为一个智能体(agent),当它在决定下一步应该走什么时,最简单的方式就是看下Reward函数的值是多少,即比较走不同动作的回报,从而做出决定。但是就像下棋的时候,我们每走一步都会向后考虑,所谓“走一步看三步”,所以这里我们只看一步即一次Reward函数是不够的,这就引出了值函数(Value Function)也叫折算累积回报(discounted cumulative reward)。
状态值函数(state value function)
当我们遵循某个策略 ,我们将值函数定义如下:
,我们将值函数定义如下: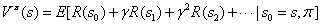
我们将上面的式子写作递推的样子如下: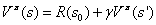
另外当策略,在状态s时,我们可以确定唯一的动作a,但是s经过动作a会进入哪个状态是不唯一的,比如同样是掷骰子操作,可能得到的状态有6种,那么利用Bellman等式我们便可以得到下面的公式: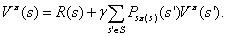
再根据我们最初增强学习的目的,我们便可以得出,求V的目的就是想找到一个当前状态s下,最优的行动策略,表示如下: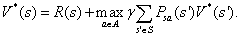
动作值函数(action value function)
上面我们的值函数的只与状态s有关,如果与状态s和动作a都有关,便称为动作值函数,即所谓的Q函数,如下: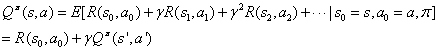
从上式我们可以看出,我们不仅仅依赖状态s和策略,并且还依赖于动作a。
综上我们可以将MDP的最优策略定义如下: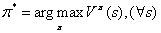
关于MDP的求解主要分为值迭代和策略迭代,分别站在不同的角度对MDP进行求解,这里我们不在赘述,网上有很多相关资料。下面我们简单阐述下动作值函数的值迭代求解方式,即所谓的Q-learning
Q学习
Q学习的基本迭代公式如下:
从公式中我们也可以看出它是一种值迭代方式,因为我们每次更新的是Q函数的值,而非策略。简单起见,整理一个简单的例子加以说明。
假设我们有这样一个房间: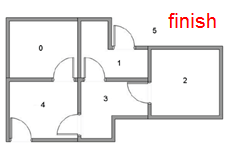
我们的目的是训练一个机器人,使得它在图中的任意一个房间都能够到达房间外。
OK,我们对房间进行建模: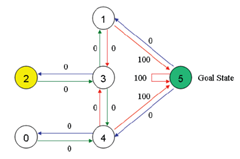
并得到reward矩阵: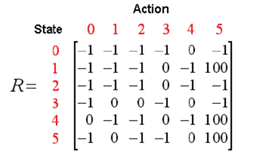
通过一下过程的迭代我们最终得出了我们的结果Q矩阵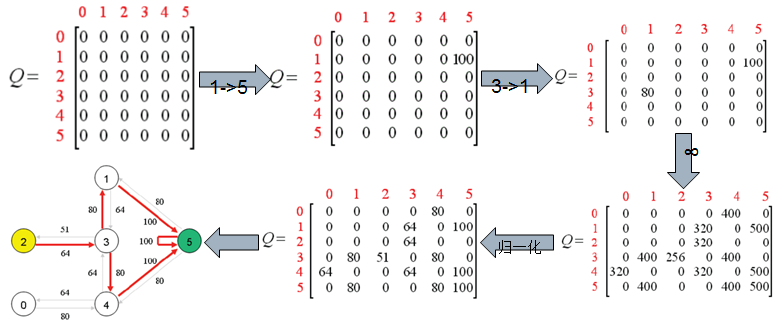
可以看出,我们的机器人现在无论在哪个房间,都可以利用我们的Q矩阵顺利的走到屋外。
噗噗噗,终于写到这里了,综上我们将马里奥只能AI需要用到的算法简单整理了下(如有任何谬误请指出^v^)。下面我们结合两种成熟的算法,归纳整理马里奥AI的两种实现方式。
基于NEAT算法的马里奥AI实现
所谓NEAT算法即通过增强拓扑的进化神经网络(Evolving Neural Networks through Augmenting Topologies),算法不同于我们之前讨论的传统神经网络,它不仅会训练和修改网络的权值,同时会修改网络的拓扑结构,包括新增节点和删除节点等操作。
NEAT算法几个核心的概念是:
- 基因:网络中的连接
- 基因组:基因的集合
- 物种:一批具有相似性基因组的集合
- Fitness:有点类似于增强学习中的reward函数
- generation:进行一组训练的基因组集合,每一代训练结束后,会根据fitness淘汰基因组,并且通过无性繁殖和有性繁殖来新增新的基因组
- 基因变异:发生在新生成基因组的过程中,可能会出现改变网络的权重,增加突出连接或者神经元,也有可能禁用突触或者启用突触
下图我们展示了算法从最一开始简单的神经网络,一直训练到后期的网络
利用NEAT算法实现马里奥的只能通关的基本思想便是,利用上面NEAT算法的基本观点,从游戏内存中获取实时的游戏数据,判断马里奥是否死忙、计算Fitness值、判断马里奥是否通关等,从而将这些作为神经网络的输入,最后输出对马里奥的操作,包括上下左右跳跃等操作,如下图:
大多数该算法实现马里奥的智能通关都依赖于模拟器,运用lua语言编写相应脚本,获取游戏数据并操作马里奥。NeuroEvolution with MarI/O。实现效果图如下:
基于Deep Reinforcement Learning的马里奥AI实现
NEAT算法是相对提出较早的算法,在2013年大名鼎鼎的DeepMind提出了一种深度增强学习的算法,该算法主要结合了我们上面讨论的CNN和Q-Learning两种算法,DeepMind的研究人员将该算法应用在Atari游戏机中的多种小游戏中进行AI通关。
其基本算法核心便是我们之前介绍的CNN和增强学习的Q-Learning,游戏智能通关的基本流程如下图:
利用CNN来识别游戏总马里奥的状态,并利用增强学习算法做出动作选择,然后根据新的返回状态和历史状态来计算reward函数从而反馈给Q函数进行迭代,不断的训练直到游戏能够通关。研究人员在训练了一个游戏后,将相同的参数用在别的游戏中发现也是适用的,说明该算法具有一定的普遍性。下图反映了一个学习的过程
而同样的方法,将DRL应用在马里奥上,github上有一个开源的实现方式:aleju/mario-ai
其最终的实现效果图如下:
我们发现在CNN识别过程中,每4帧图像,才会进行一次CNN识别,这是识别速率的问题,图中曲线反映了直接回报函数和简介回报函数。
总结
综上便是从最基本的神经网络算法+增强学习,到将这些算法用在智能AI上的一些基本整理,长舒一口气,整理了好久。。。关于智能AI的应用有很多,也跟好多小伙伴讨论过,包括智能测试、新式游戏、游戏平衡性调整以及AI机器人的加入。这个领域除了枯燥的理论知识还能玩游戏,想想有点小激动。总结完毕,如有任何纰漏还请指出,我会尽快修改,谢谢^v^。
参考文献:
- 漫谈ANN(1):M-P模型
- 漫谈ANN(2):BP神经网络
- 卷积神经网络
- 卷积神经网络全面解析
- 重磅!神经网络浅讲:从神经元到深度学习
- R.Sutton et al. Reinforcement learning: An introduction , 1998
- 马尔可夫性质
- 增强学习(二)----- 马尔可夫决策过程MDP
- 增强学习(三)----- MDP的动态规划解法
- 增强学习(Reinforcement Learning and Control)
- wiki-Q-learning
- Q-Learning example
- Stanley K O, Miikkulainen R. Evolving neural networks through augmenting topologies[J]. Evolutionary computation, 2002, 10(2): 99-127.
- Wang Y, Schreiber B. Creating a Traffic Merging Behavior Using NeuroEvolution of Augmenting Topologies[J]. 2015.
- Cussat-Blanc S, Harrington K, Pollack J. Gene regulatory network evolution through augmenting topologies[J]. IEEE Transactions on Evolutionary Computation, 2015, 19(6): 823-837.
- Mnih V, Kavukcuoglu K, Silver D, et al. Playing atari with deep reinforcement learning[J]. arXiv preprint arXiv:1312.5602, 2013.