一.准备
1.百度ai开放平台提供了优质的接口资源https://ai.baidu.com/ (基本免费)
2.在语音识别的接口中, 对中文来说, 讯飞的接口是很好的选择https://www.xfyun.cn/ (收费)
3.图灵机器人提供了可以用http访问的接口, http://www.turingapi.com/
二.创建
1.百度: 在具体功能中创建应用, 点击技术文档-> python sdk 按照文档使用

2.图灵机器人, 如果所示,创建机器人
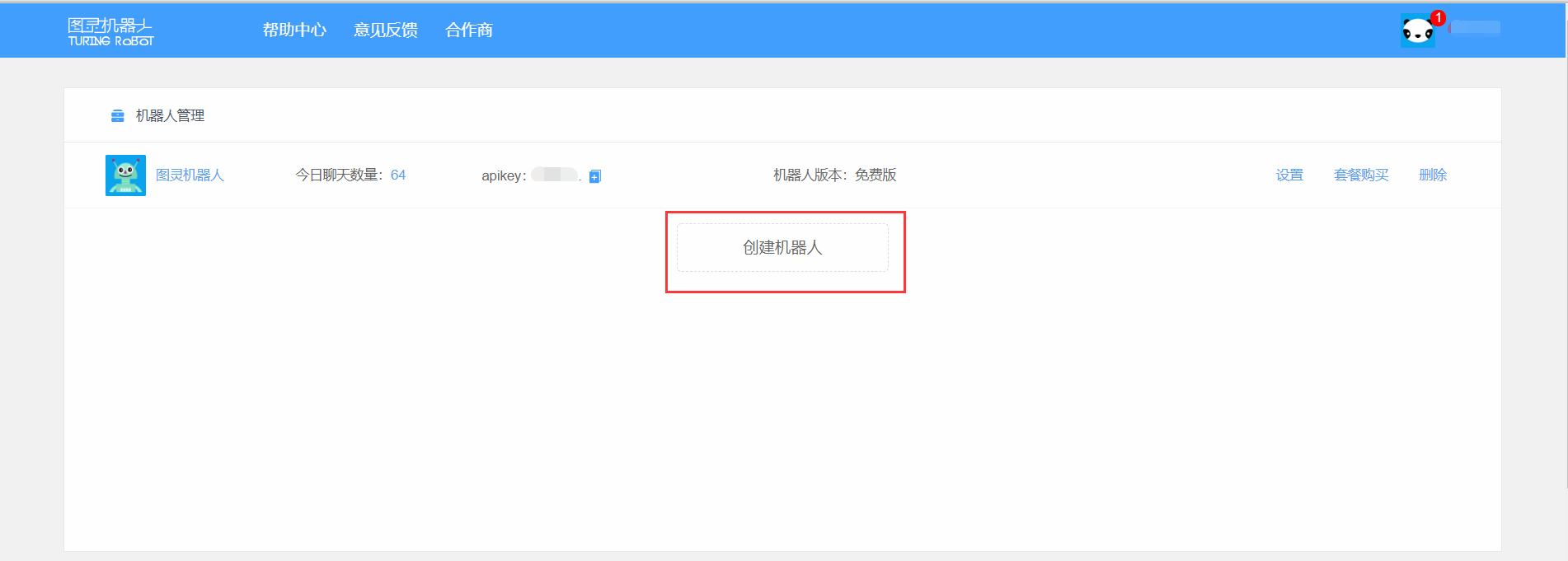
在设置中可以对机器人的属性设置,包括年龄星座等, 之后可以点击查看api使用文档进行使用
三.使用
由于百度的语音识别需要的格式为.pcm, 而示例中主要用win系统自带的录音机文件进行声音采集,需要对文件转码.所以需要安装ffmpeg, 安装后将目录/bin配置进系统环境变量
配置完环境变量之后,编译器(pycharm)要重启一下,重新加载一下环境变量,否则会报错

如图,环境变量配置成功, cd命令切换到音频文件目录下, 使用下面的命令将文件转换为pcm格式
ffmpeg -y -i audio.wav -acodec pcm_s16le -f s16le -ac 1 -ar 16000 audio.pcm
# 1.你说一句话 # 2.根据语音转化为文字 # 3.机器人通过对文字的处理返回应答 # 4.将应答文字转化为语音,实现对话 import os import requests from aip import AipNlp, AipSpeech """ 你的 APPID AK SK """ APP_ID = '输入 app_id' API_KEY = '输入api_key' SECRET_KEY = '输入secret_key' client = AipNlp(APP_ID, API_KEY, SECRET_KEY) client2 = AipSpeech(APP_ID, API_KEY, SECRET_KEY) client3 = AipSpeech(APP_ID, API_KEY, SECRET_KEY) # 1. 说-> 转换为文字 # 读取文件 def get_file_content(filePath): os.system(f'ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm') with open(f'{filePath}.pcm', 'rb') as fp: return fp.read() # 调用图灵机器人交互 def to_url(text, uid): url = 'http://openapi.tuling123.com/openapi/api/v2' data = { "reqType": 0, "perception": { "inputText": { "text": "" }, }, "userInfo": { "apiKey": "图灵机器人的apikey", "userId": "1" } } data['userInfo']['userId'] = uid data['perception']['inputText']['text'] = text
# 使用requests模块模拟http请求 res = requests.post(url, json=data).json() return res.get('results')[-1].get('values').get('text') # 将语音转化为文字 def text(file): # 识别本地文件 ret = client2.asr(get_file_content(file), 'pcm', 16000, { 'dev_pid': 1536, }) text = ret.get('result')[-1] return text # 将交互结果转化为语音 def to_audio(text): result = client3.synthesis(text, 'zh', 1, { 'vol': 5, # 音量 'spd': 5, # 语速 'pit': 8, # 音调 'per': 4, # 发声人选择 }) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open('auido.mp3', 'wb') as f: f.write(result) # 在win系统下 os.system可以直接打开这个文件 os.system('auido.mp3')
# ####入口#### t = text('录音.m4a') # 录音文件 放在这里
# NLP自然语言处理 ret = client.simnet('你爸爸是谁', t) print(ret) # {'log_id': 7122976772040456976, 'texts': {'text_2': '你把我是谁', 'text_1': '你爸爸是谁'}, 'score': 0.656308} # 0.656308 score = ret.get('score') print(score) # 0.656308 if score >= 0.58: # score在0.58以上证明两个文本表达的意思基本一致 to_audio('当然是罗伯特X了') else: to_audio(t)


import os from aip import AipSpeech,AipNlp """ 你的 APPID AK SK """ APP_ID = '16027154' API_KEY = '5a8u0aLf2SxRGRMX3jbZ2VH0adfa' SECRET_KEY = 'UAaqS13z6DjD9Qbjd065dAh0HjbqPrzVadfad' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) client_nlp = AipNlp(APP_ID, API_KEY, SECRET_KEY) # res = client_nlp.simnet("你叫什么名字","你的名字是什么") # print(res) def text2audio(text): result = client.synthesis(text, 'zh', 1, { "spd": 4, 'vol': 5, "pit": 8, "per": 4 }) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open('audio.mp3', 'wb') as f: f.write(result) return 'audio.mp3' def audio2text(filepath): res = client.asr(get_file_content(filepath), 'pcm', 16000, { 'dev_pid': 1536, }) print(res.get("result")[0]) return res.get("result")[0] def get_file_content(filePath): os.system(f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm") with open(f"{filePath}.pcm", 'rb') as fp: return fp.read() def goto_tl(text,uid): URL = "http://openapi.tuling123.com/openapi/api/v2" import requests data = { "perception": { "inputText": { "text": "你叫什么名字" } }, "userInfo": { "apiKey": "be41cf8596a24aec95b0e86be895cfa9asd", "userId": "123" } } data["perception"]["inputText"]["text"] = text data["userInfo"]["userId"] = uid res = requests.post(URL, json=data) # print(res.content) # print(res.text) print(res.json()) return res.json().get("results")[0].get("values").get("text") text = audio2text("jttqhbc.m4a") # 自然语言处理 简单实现 score = client_nlp.simnet("你叫什么名字",text).get("score") print(score) if score >= 0.58: filename = text2audio("需要回复的音频文件名") # os.system(f"ffplay {filename}") os.system(filename) answer = goto_tl(text,"qiaoxiaoqiang") filename = text2audio(answer) os.system(filename)