人工智能,机器学习,深度学习,神经网络
要说2017年什么技术最火爆,无疑是google领衔的深度学习开源框架Tensorflow。本文简述一下深度学习的入门例子MNIST。
深度学习简单介绍
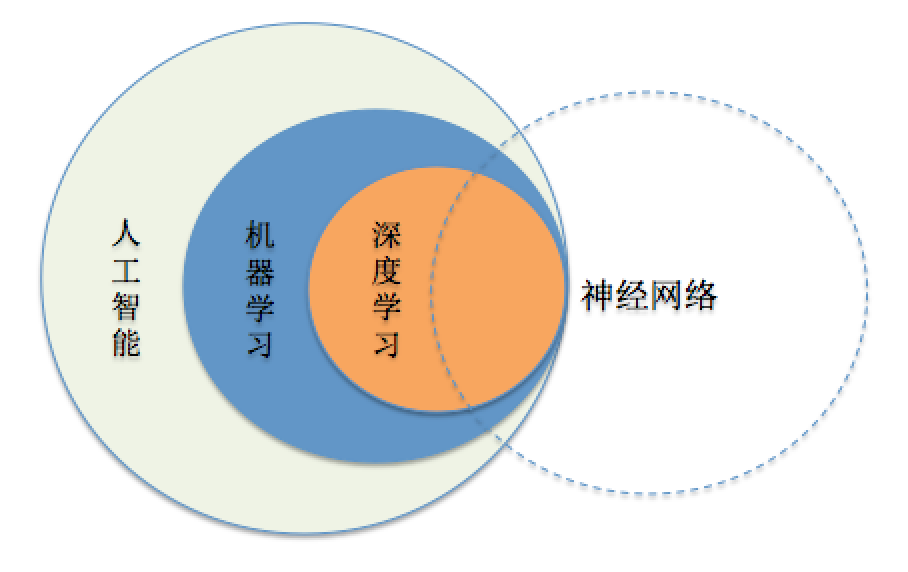
首先要简单区别几个概念:人工智能,机器学习,深度学习,神经网络。这几个词应该是出现的最为频繁的,但是他们有什么区别呢?
人工智能:人类通过直觉可以解决的问题,如:自然语言理解,图像识别,语音识别等,计算机很难解决,而人工智能就是要解决这类问题。
机器学习:如果一个任务可以在任务T上,随着经验E的增加,效果P也随之增加,那么就认为这个程序可以从经验中学习。
深度学习:其核心就是自动将简单的特征组合成更加复杂的特征,并用这些特征解决问题。
神经网络:最初是一个生物学的概念,一般是指大脑神经元,触点,细胞等组成的网络,用于产生意识,帮助生物思考和行动,后来人工智能受神经网络的启发,发展出了人工神经网络。
来一张图就比较清楚了,如下图:
MNIST解析
MNIST是深度学习的经典入门demo,他是由6万张训练图片和1万张测试图片构成的,每张图片都是28*28大小(如下图),而且都是黑白色构成(这里的黑色是一个0-1的浮点数,黑色越深表示数值越靠近1),这些图片是采集的不同的人手写从0到9的数字。TensorFlow将这个数据集和相关操作封装到了库中,下面我们来一步步解读深度学习MNIST的过程。

上图就是4张MNIST图片。这些图片并不是传统意义上的png或者jpg格式的图片,因为png或者jpg的图片格式,会带有很多干扰信息(如:数据块,图片头,图片尾,长度等等),这些图片会被处理成很简易的二维数组,如图:
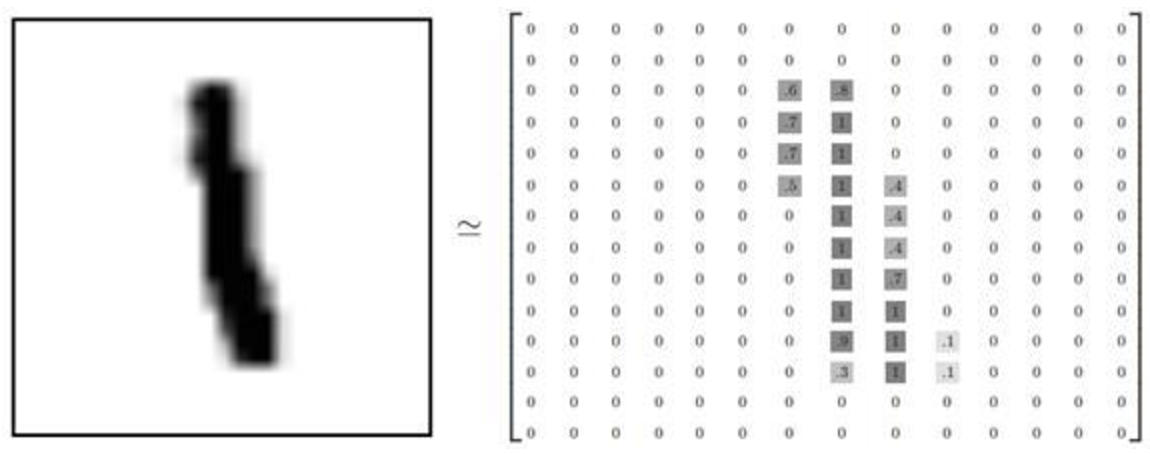
可以看到,矩阵中有值的地方构成的图形,跟左边的图形很相似。之所以这样做,是为了让模型更简单清晰。特征更明显。
我们先看模型的代码以及如何训练模型:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True)# x是特征值 x = tf.placeholder(tf.float32, [None, 784])# w表示每一个特征值(像素点)会影响结果的权重 W = tf.Variable(tf.zeros([784, 10])) b = tf.Variable(tf.zeros([10])) y = tf.matmul(x, W) + b# 是图片实际对应的值 y_ = tf.placeholder(tf.float32, [None, 10])<br> cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y)) train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy) sess = tf.InteractiveSession() tf.global_variables_initializer().run() # mnist.train 训练数据 for _ in range(1000): batch_xs, batch_ys = mnist.train.next_batch(100) sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys}) #取得y得最大概率对应的数组索引来和y_的数组索引对比,如果索引相同,则表示预测正确 correct_prediction = tf.equal(tf.arg_max(y, 1), tf.arg_max(y_, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})) |
首先第一行是获取MNIST的数据集,我们逐一解释一下:
x(图片的特征值):这里使用了一个28*28=784列的数据来表示一个图片的构成,也就是说,每一个点都是这个图片的一个特征,这个其实比较好理解,因为每一个点都会对图片的样子和表达的含义有影响,只是影响的大小不同而已。至于为什么要将28*28的矩阵摊平成为一个1行784列的一维数组,我猜测可能是因为这样做会更加简单直观。
W(特征值对应的权重):这个值很重要,因为我们深度学习的过程,就是发现特征,经过一系列训练,从而得出每一个特征对结果影响的权重,我们训练,就是为了得到这个最佳权重值。
b(偏置量):是为了去线性话(我不是太清楚为什么需要这个值)
y(预测的结果):单个样本被预测出来是哪个数字的概率,比如:有可能结果是[ 1.07476616 -4.54194021 2.98073649 -7.42985344 3.29253793 1.96750617 8.59438515 -6.65950203 1.68721473 -0.9658531 ],则分别表示是0,1,2,3,4,5,6,7,8,9的概率,然后会取一个最大值来作为本次预测的结果,对于这个数组来说,结果是6(8.59438515)
y_(真实结果):来自MNIST的训练集,每一个图片所对应的真实值,如果是6,则表示为:[0 0 0 0 0 1 0 0 0]
再下面两行代码是损失函数(交叉熵)和梯度下降算法,通过不断的调整权重和偏置量的值,来逐步减小根据计算的预测结果和提供的真实结果之间的差异,以达到训练模型的目的。
算法确定以后便可以开始训练模型了,如下:
|
1
2
3
|
for _ in range(1000): batch_xs, batch_ys = mnist.train.next_batch(100) sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys}) |
mnist.train.next_batch(100)是从训练集里一次提取100张图片数据来训练,然后循环1000次,以达到训练的目的。
之后的两行代码都有注释,不再累述。我们看最后一行代码:
|
1
2
|
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})) |
mnist.test.images和mnist.test.labels是测试集,用来测试。accuracy是预测准确率。
当代码运行起来以后,我们发现,准确率大概在92%左右浮动。这个时候我们可能想看看到底是什么样的图片让预测不准。则添加如下代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
for i in range(0, len(mnist.test.images)): result = sess.run(correct_prediction, feed_dict={x: np.array([mnist.test.images[i]]), y_: np.array([mnist.test.labels[i]])}) if not result: print('预测的值是:',sess.run(y, feed_dict={x: np.array([mnist.test.images[i]]), y_: np.array([mnist.test.labels[i]])})) print('实际的值是:',sess.run(y_,feed_dict={x: np.array([mnist.test.images[i]]), y_: np.array([mnist.test.labels[i]])})) one_pic_arr = np.reshape(mnist.test.images[i], (28, 28)) pic_matrix = np.matrix(one_pic_arr, dtype="float") plt.imshow(pic_matrix) pylab.show() breakprint(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})) |
for循环内指明一旦result为false,就表示出现了预测值和实际值不符合的图片,然后我们把值和图片分别打印出来看看:
预测的值是: [[ 1.82234347 -4.87242508 2.63052988 -6.56350136 2.73666072 2.30682945 8.59051228 -7.20512581 1.45552373 -0.90134078]]
对应的是数字6。
实际的值是: [[ 0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]]
对应的是数字5。
我们再来看看图片是什么样子的:

的确像5又像6。
总体来说,只有92%的准确率,还是比较低的,后续会解析一下比较适合识别图片的卷积神经网络,准确率可以达到99%以上。
一些体会与感想
我本人是一名iOS开发,也是迎着人工智能的浪潮开始一路学习,我觉得人工智能终将改变我们的生活,也会成为未来的一个热门学科。这一个多月的自学下来,我觉得最为困难的是克服自己的畏难情绪,因为我完全没有AI方面的任何经验,而且工作年限太久,线性代数,概率论等知识早已还给老师,所以在开始的时候,总是反反复复不停犹豫,纠结到底要不要把时间花费在研究深度学习上面。但是后来一想,假如我不学AI的东西,若干年后,AI发展越发成熟,到时候想学也会难以跟上步伐,而且,让电脑学会思考这本身就是一件很让人兴奋的事情,既然想学,有什么理由不去学呢?与大家共勉。
参考文章:
https://zhuanlan.zhihu.com/p/25482889
https://hit-scir.gitbooks.io/neural-networks-and-deep-learning-zh_cn/content/chap1/c1s0.html