[toc]
引用计数法
George E.Collins.1960.
引用计数算法中引入了一个概念计数器。计数器代表对象被引用的次数,它是无符号正整数用于计数器的位数根据算法和实现有所不同。本文结构如下图所示。

在变更数组元素等的时候会进行指针的更新。通过更新指针,可能会产生没有被任何程序引用的垃圾对象。引用计数法中会监督在更新指针的时候是否有产生垃圾,从而在产生 垃圾时将其立刻回收。这样,可以说将内存管理和 mutator 同时运行正是引用计数法的一大特征。
计数器值的增减
引用计数算法中,mutator没有明确启动GC的语句。它在mutator的处理过程中通过增减计数器的值来进行内存管理,这两种情况下计数器的值会发生改变,这使用到了new_obj()函数和update_ptr()函数。
new_obj()和update_ptr()函数
new_obj()生成对象
new_obj(size){
obj = pickup_chunk(size, $free_list)
if(obj == NULL)
allocation_fail()
else
obj.ref_cnt = 1
return obj
}
这是生成新的对象,使用pickup_chunk()函数。当函数返回NULL是代表分配失败。在引用计数法中,除了连接到空闲链表的对象,其他所有对象都是活动对象。也就是说,一旦返回NULL就代表没有任何多余的空间了。也就无法进行分配。
当pickup_chunk()函数返回合适大小的对象时,讲他的计数器ref_cnt置为1,代表其被引用了1次。
update_ptr()更新指针ptr,对计数器进行增减
update_ptr(ptr, obj){
inc_ref_cnt(obj) //计数器+
dec_ref_cnt(*ptr) //计数器-
*ptr = obj // 重新指向 obj
}
在mutator更新指针时会执行此程序。其、*ptr = obj是指针更新的部分。
增加引用和删除引用
inc_ref_cnt(obj)对指针ptr新引用对象obj计数器进行增量操作。
inc_ref_cnt(obj){
obj.ref_cnt++
}
仅仅是对对象计数器进行自增操作。
dec_ref_cnt(*ptr)对之前ptr引用的对象进行计数器减量操作。
dec_ref_cnt(*ptr){
obj.ref_cnt--
if (obj.ref_cnt == 0)
for(child : children(obj)) // 当自己被清除时,自己所引用的孩子的计数器必须减一。进行递归操作。
dec_ref_cnt(*child)
reclaim(obj)
}
- 首先对更新指针之前引用的对象*ptr的计数器进行减量操作。减量操作后,计数器的值为0的对象变成了“垃圾”。因此,这个对象的指针会全部被删除。
- 然后递归调用dec_ref_cnt(*ptr)对孩子进行计数器减量的操作。
- 然后通过reclaim()函数,将obj连接到空闲链表上面。
疑问为什么要先inc_ref_cnt(obj)然后再dec_ref_cnt(*ptr)呢? 觉得应该先调用 dec_ref_cnt() 函数,后调 用 inc_ref_cnt() 函数才合适。
答案就是“为了处理ptr和obj是同一对象时的情况”。如果按照先dec_ref_cnt()后inc_ref_cnt()函数的顺序调用ptr和 obj又是同一对象的话执行dec_ref_cnt(ptr)时ptr的计数器的值就有可能变为0而被回收。这样一来,下面再想执行inc_ref_cnt(obj)时obj早就被回收了,可能会引发重大的BUG。
update_ptr()函数执行情况
初始状态下从根引用A和C,从A引用B。A持有唯一指向B的指针(代指状态a),假设现在将A指针更新到了C(状态b)。如下图。
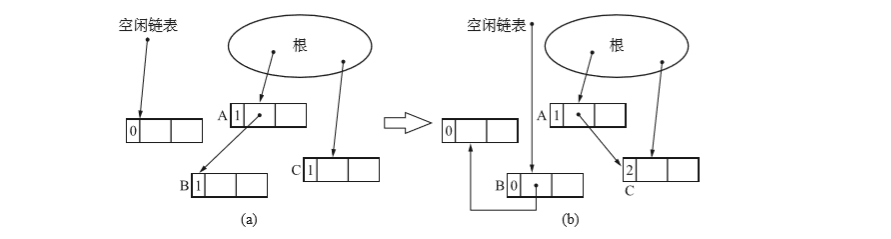
B的计数器值变成了0,因此B被回收。且B连接上了空闲链表,能够再被利用了。又因为新形成了由A指向C的指针,所以C的计数器的值增量为2。
优点
可即可回收垃圾
在引用计数法中,每个对象始终都知道自己的被引用数(就是计数器的值)。当被引用数的值为0时,对象马上就会把自己作为空闲空间连接到空闲链表。也就是说,各个对象在变成垃圾的同时就会立刻被回收。要说这有什么意义,那就是内存空间不会被垃圾占领。垃圾 全部都已连接到空闲链表,能作为分块再被利用。
最大暂停时间短
在引用计数法中,只有当通过mutator更新指针时程序才会执行垃圾回收。也就是说,每次通过执行mutator 生成垃圾时这部分垃圾都会被回收,因而大幅度地削减了mutator的最大暂停时间。
没有沿着指针查找
引用计数法和GC标记-清除算法不一样,没必要由根沿指针查找。当我们想减少沿指针查找的次数时,它就派上用场了。 打个比方,在分布式环境中,如果要沿各个计算节点之间的指针进行查找,成本就会增大,因此需要极力控制沿指针查找的次数。 所以有一种做法是在各个计算节点内回收垃圾时使用GC标记-清除算法在考虑到节点间的引用关系时则采用引用计数法。
缺点
计数器的增减处理频繁
在大多数情况下指针都会频繁地更新,特别是有根的指针,会以近乎令人目眩的势头飞速地进行更新。这是因为根可以通过mutator直接被引用。在引用计数法中,每当指针更新时,计数器的都会随之更新,因此值的增减处理必然会变得繁重。
计数器占用很多位
用于引用计数的计数器最大必须能数完堆中所有对象的引用数。打个比方,**假如我们用的是32位机器,那么就有可能要让2 的32次方个对象同时引用一个对象。考虑到这种情况,就有必要确保各对象的计数器有32位大小。也就是说,对于所有对象,必须留有32位的空间。这就害得内存空间的使用效率大大降低了。打比方说,假如对象只有2个域,那么其计数器就占了它整体的1/3。 **
实现繁琐复杂
进行指针更新操作 update_ptr()函数是在mutator这边调用的打个比方我们需要把以往写成*ptr=obj的地方都重写成updat_ptr(ptr,obj)。因为调用update_ptr()函数的地方非常多,所以重写过程中很容易出现遗漏。如果漏掉了某处,内存管理就无法正确进行,就会产生BUG。
循环引用问题

因为两个对象互相引用,所以各对象的计数器的值都是1。但是这些对象组并没有被其他任何对象引用。因此想一并回收这两个对象都不行,只要它们的计数器值都是1,就无法回收。
延迟引用计数
在讲到引用计数法缺点时候,我们提到了计数器增减处理繁重。下面就对改善此缺点进行说明即延迟引用计数法(Deferred Reference Countin [L. Peter Deutsch 和 Daniel G. Bobrow] )。
什么是延迟引用计数
我们就让从根引用的指针的变化不反映在计数器上。打个比方,我们把重写全局变量指针的 update_ptr(ptr,obj) 改写成 *ptr = obj(直接更改引用对象,没有使用方法也就没有对计数器进行操作。)。如上所述,这样一来即使频繁重写堆中对象的引用关系,对象的计数器值也不会有所变化,因而大大改善了“计数器值的增减处理繁重”这一缺点。然而,这样内存管理还是不能顺利进行。因为引用没有反映到计数器上,所以各个对象的计数器没有正确表示出对象本身的被引用数。因此,有可能发生对象仍在活动,但却被错当成垃圾回收的情况。 如下图所示该对象其实还正在活动。

之后我们在延迟计数法中使用ZCT(Zero Count Table)。ZTC是一个表,他会事先记录下计数器值在dec_ref_cnt()函数的作用下变为0的对象。
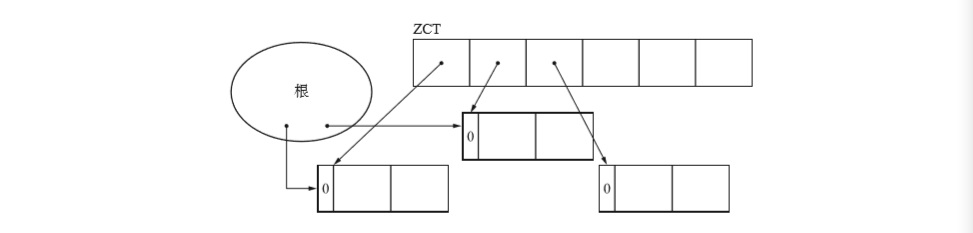
因为计数器值为0的对象不一定都是垃圾,所以暂时先将这些对象保留。由图也能看出,我们必须修正dec_ref_cnt() 函数,使其适应延迟引用计数法。
dec_ref_cnt()函数
dec_ref_cnt(obj){
obj.ref_cnt--
if(obj.ref_cnt == 0)
if(is_full($zct) == TRUE)
scan_zct()
push($zct, obj)
}
当obj计数器为0,就把obj添加到$zct中。不过当$zct爆满,首先要通过scan_zct()函数来减少$zct中的对象。
new_obj()函数
也要修改一线new_obj()函数。当无法分配空间时,执行scan_zct()清理一遍$zct对象(表)。
new_obj(size){
obj = pickup_chunk(size, $free_list)
if(obj == NULL)
scan_zct()
obj = pickup_chunk(size, $free_list)
if(obj == NULL)
allocation_fall()
obj.ref_cnt = 1
return obj
}
如果第一次分配没有顺利进行,就意味着空闲链表中没有了大小合适的分块。此时程序要搜索一遍$zct,以再次分配分块。如果这样还不行,分配就失败了。分配顺利进行之后的流程通常与引用计数法完全一样。
scan_zct()函数
scan_zct(){
for(r :$roots) // 之前我们说过,把根的引用不反应在计数器上,现在要清表了自然要加上。
(*r).ref_cnt++
for(obj :$zct) // 查水表
if(obj.ref_cnt == 0) // 判断值
remove($zct, obj) // 减计数
delete(obj) //清对象
for(r :$root)
(*r).ref_cnt-- // 用完了在给根加回去。
}
- 程序把所有通过根直接引用的对象的计数器都进行增量。这样才算把根引用反映到了计数器的值上。
- 调查所有与$zct相连的对象,如果存在计数器值为0的对象,则将此对象从$zct中删除(delete)。
// delete代码清单
delete(obj){
for(child :children(obj))
(*child).ref_cnt--
if((*child).ref_cnt == 0)
delete(*child) // 同样要递归的去操作孩子的计数器
reclaim(obj) // 加到空闲链表上
}
优缺点
优点在延迟引用计数法中,程序延迟了根引用的计数,将垃圾一并回收。通过延迟,减轻了 因根引用频繁发生变化而导致的计数器增减所带来的额外负担。
缺点为了延迟计数器值的增减,垃圾不能马上得到回收,这样一来垃圾就会压迫堆,我们也 就失去了引用计数法的一大优点(即刻回收垃圾)。
缺点scan_zct() 函数导致最大暂停时间延长了,执行scan_zct() 函数所花费的时间 $zct的大小成正比。$zct 越大,要搜索的对象就越多,妨碍mutator运作的时间也就越长。要想缩减因scan_zct()函数而导致的暂停时间,就要缩小 $zct。但是这样一来调用scan_ zct()函数的频率就增加了,也压低了吞吐量。很明显这样就本末倒置了。
Stricky引用计数法
什么是Stricky引用计数法
在引用计数法中,我们有必要花功夫来研究一件事,那就是要为计数器设置多大的位宽。 假设为了反映所有引用,计数器需要1个字(32位机器就是32位)的空间。但是这样会大量消耗内存空间。打个比方,2 个字的对象就要附加1个字的计数器。也就是说,计数器害得对象所占空间增大了1.5 倍。

对此我们有个方法,那就是用来减少计数器位宽的“Sticky引用计数法”。举个例子我们假设用于计数器的位数为5位,那么这种计数器最多只能数到2的5次方减1也就是31个引用数。如果此对象被大于31个对象引用,那么计数器就会溢出。这跟车辆速度计的指针爆表是一个状况。
针对计数器溢出(也就是爆表的对象),需要暂停对计数器的管理。对付这种对象,我们主要有两种方法。
什么都不做
对于计数器溢出的对象,我们可以这样处理:不再增减计数器的值,就把它放着,什么也不做。不过这样一来,即使这个对象成了垃圾(即被引用数为 0),也不能将其回收。也就是说,白白浪费了内存空间。然而事实上有很多研究表明,很多对象一生成马上就死了。也就是说, 在很多情况下,计数器的值会在0到1的范围内变化,鲜少出现 5 位计数器溢出这样的情况。 此外,因为计数器溢出的对象在执行中的程序里占有非常重要的地位,所以可想而知,其将 来成为垃圾的可能性也很低。也就是说,不增减计数器的值,就把它那么放着也不会有什么大问题。 考虑到以上事项,对于计数器溢出的对象,什么也不做也不失为一个可用的方法。
使用GC标记-清除算法进行管理
另一个方法是,可以使用标记清除算法来辅助。但是需要对标记清除进行修改。 mark_sweep_for_counter_overflow()
// mark_sweep_for_counter_overflow()
mark_sweep_for_counter_overflow(){
reset_all_ref_cnt()
mark_phase()
sweep_phase()
}
首先把所有对象的计数器都置为0。下面进入标记阶段和清除阶段。
mark_phase()
// mark_phase()
mark_phase(){
for(r :roots)
push(*r, $mark_stack)
while(is_empty($mark_stack) == FALSE)
obj = pop($mark_stack)
obj.ref_cnt++
if(obj.ref_cnt == 1)
for(child :children(obj))
push(*child, $mark_stack)
}
首先把由根直接引用的对象堆到标记栈里,然后按顺序从标记栈取出对象。对计数器进行增量操作。不过这里必须把各个对象及其子对象堆进标记栈一次。while里的if是检测各个对象是不是只进栈一次。一旦栈为空,则标记阶段结束。 sweep_phase()
// sweep_phase()
sweep_phase(){
sweeping = $heap_top
while(sweeping < $heap_end)
if(sweeping.ref_cnt == 0)
reclaim(sweeping)
sweeping +=sweeping.size
}
在清除阶段,程序会搜索整个堆,回收计数器值仍为0的对象。
这里的标记清除,和之前的标记清除主要有以下3点不同之处。
- 一开始把所有对象的计数器置为0.
- 不标记对象,而是对计数器进行增量操作。
- 为了对计数器进行增量操作,算法对活动对象进行了不止一次的搜索。
像这样,只要把引用计数法和 GC 标记 - 清除算法结合起来,在计数器溢出后即使对象 成了垃圾,程序还是能回收它。另外还有一个优点,那就是还能回收循环的垃圾。
但是在进行标记处理之前,必须重置所有的对象和计数器。此外,因为在查找对象时没 有设置标志位而是把计数器进行增量,所以需要多次(次数和被引用数一致)查找活动对象。 考虑到这一点的话,显然在这里进行的标记处理比以往的 GC 标记 - 清除算法中的标记处理 要花更多的时间。也就是说,吞吐量会相应缩小。
1位引用计数法
1位引用计数法(1bit Reference Counting)是Sticky引用计数法的一个极端例子。因为计数器只有1位大小,所以瞬间就会溢出。
据Douglas W. Clark和C. Cordell Green观察,“几乎没有对象是被共有的,所有对象都能被马上回收”。考虑到这一点,即使计数器只有 1 位,通过用 0表示被引用数为1 ,用1表示被引用数大于等于2,这样也能有效率地进行内存管理。如下图示。

我们用1位来表示某个对象的被引用数是1个还是多个。一般引用计数法是让对象持有计数器,但是W.R.Stoye、T.J.W.Clarke、A.C.Norman 3个人想出了1位引用计数法,以此来让指针持有计数器。
设对象引用数为1时标签位为0,引用数为复数时标签位为1。我们分别称以上2种状态为UNIQUE和MULTIPLE,处于UNIQUE状态下的指针为“UNIQUE指针”,处于MULTIPLE状态下的指针为“MULTIPLE 指针”。
copy_ptr()函数
1 位引用计数法也是在更新指针的时候进行内存管理的。不过它不像以往那样 指定要引用的对象来更新指针,而是通过复制某个指针来更新指针。进行这项操作的就是 copy_ptr() 函数。下图示。
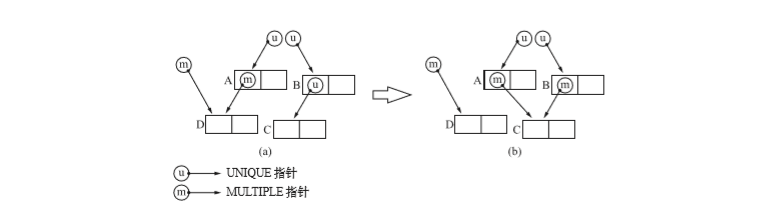
在这里更新之前A引用D的指针,让其引用C。可以看到,B由UNIQUE变为了MULTIPLE。伪代码如下。
copy_ptr(dest_ptr, src_ptr){
delete_ptr(dest_ptr)
*dest_ptr = *src_ptr
set_multiple_tag(dest_ptr)
if(tag(src_ptr) == UNIQUE)
set_multiple_tag(src_ptr)
}
数 dest_ptr 和 src_ptr 分别表示的是目的指针和被复制的原指针。在上图图 中,A 的指针就是目的指针,B 的指针就是被复制的原指针。
- 首先调用delete_ptr()函数,尝试回收dest_ptr引用对象。
- 把src_ptr复制到dest_ptr。
- 把指针src_ptr以及dest_ptr的标签更新为MULTIPLE。
- tag()函数返回实参的标签,返回UNIQUE或者MULTIPLE的任意一值。
- set_multiple_tag()函数则把指针变成MULTIPLE指针。
最后把mutator的update_ptr()函数的调用全换成copy_ptr()就能实现1位引用计数法。
delete_ptr()函数
delete_ptr(ptr){
if(tag(ptr) == UNIQUE)
reclaim(*ptr)
}
只有当指针ptr的标签是UNIQUE时,它才会回收根据这个指针所引用的对象。因为当标签是MULTIPLE时,还可能存在其他引用这个对象的指针,所以它无法回收对象。
优缺点
优点 不容易出现高速缓存缺失。缓存作为存储空间,比内存读取的快得多。如果需要的数据在缓存中,计算机就能进行高速处理。但如果缺失了的话就需要从内存中去读。这样一来浪费许多时间。
也就是说,当某个对象A要引用在内存中离他很远的B时,以往的引用计数法会在增减计数器的值时候去读B,从而导致高速缓存缺失,浪费时间。
1位引用计数法,它不需要在更新计数器的时候读取要引用的对象。指针直接复制就行,没必要读取对象。因为没必要给计数器留出多余的空间,所以节省了内存消耗量。这也不失为1位引用计数法的一个优点。
缺点 没办法处理计数器益处的对象。虽然说,计数器的值一般都不足为2,但是如果少量当然可以放置不管。但我们不能保证某一个任务不会出现很多计数器溢出的现象。