Libo1575899134@outlook.com
Libo
(原创文章,转发请注明作者)
本文章主要介绍Gan的应用篇,3,主要介绍图像应用,4, 主要介绍文本以及医药化学其他领域应用
原理篇请看上两篇
https://www.cnblogs.com/Libo-Master/p/11167804.html
https://www.cnblogs.com/Libo-Master/p/11169198.html
图像应用
https://www.cnblogs.com/Libo-Master/p/11187799.html
-----------------------------------------------------------------------------------
本文主要介绍在文本和医药化学上的应用,其实唯一的化学式分子式是可以通过一系列字符串表示的,SEQ-GAN是第一个在文本中work的GAN,由上交的组做的,比较暴力的对离散不能求导的问题,用RL的Policy Gradient来解决,先介绍框架,把文本生成变成了增强学习的过程,奖励在每次生成完完整的文本序列后,得到一个Reward,这个Reward作为此次增强学习的Reward,通过Reward不断迭代策略,之所以要这么做是因为直接把文本用在Gan中会出现刚才说的问题,每次生成出来的文本是一个离散的序列,不管是汉字还是英文是无法直接求导的,比如无法给梯度加减0.1得到另外一个字符,无法在离散空间做字符的变换,不得不转化到增强学习的框架来做,当时做的任务是唐诗宋词五言的生成,基于奥巴马演讲生成的东西,还做了音符也可以认为是个离散序列。

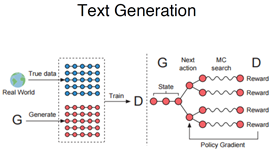
后来有人也做了相关的改进,把Reward不是用到了增强学习中,而是用到了判别器得到的score融合到了基于最大似然的训练的目标函数中,变到了一个稳定的去求解过程。
现在微信也有很多接口,效果也比较好,是因为他们的工作加了很多特征,手动feature,比如要求生成符合韵律的(平仄),都会编码的生成过程中的,还有些意向的映射比如山水都会编码进去。

然后在PTB(一个经典的小数据集文本)的生成的一些句子,基于词建模,一次生成了一些词而不是句子,所以并不会有拼写错误的情况。大意都是在一个topic下的什么事情。


下面是在一个大数据集上生成的结果,是基于improve-WGAN的基础上做的,并没有转化到一个增强学习的框架下,是直接在特征空间或者隐空间来处理这些文本,一般都是把原始的文本映射到一个连续的隐空间中,然后再通过一个连续的隐空间解码成一个离散文本,这是一般的文本生成的过程。然后在解码出来的离散空间来判别是真是假,需要用一些增强学习做(没有办法反向传播的问题),但是如果在连续空间直接判别是真是假,直接可以解决不能求导的问题,但是在连续空间做判别太简单了,很容易判别出假样本是假的,真样本是真的,这会导致整个gan没办法训练起来,因为是一个对抗过程,如果生成不了能够欺骗判别器的假样本,生成器就永远不能提高,训练不起来,判别器也无法提高自己,最终就失败了,所以用了W-GAN 就可以使得离散空间也可以训练判别器 ,不需要借助增强学习,每次只生成一个字母 字符级别的,可以建模语言信息了。

有了普通的文本生成,又做了一些条件的生成,生成一些跟给定文本相关的文本,相关就是在不同任务上体现,对话生成,既符合自然语言的话,又符合上下文逻辑的话,回应用户的对话,下面是一个问路的例子

下面是一个租房的例子。
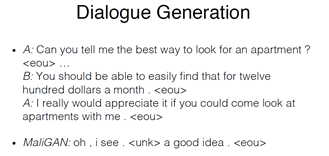
下面是斯坦福博士的,把Adversarial traning 应用在了对话中,下面是解码的结果,他们同样把Gan的生成用到了增强学习中,增强学习具体有多种解法,不同的解法生成的文本长短和内容都会有较大的区别,有些时候生成反问句,有些时候会生成陈述句

后面有些人把对抗训练,用在了机器翻译的任务上,是今年微软亚洲研究院的工作,下面加粗的文本是翻译的结果,第二行是加了对抗训练的结果,可以看到加了对抗学习可以减少拼写错误,减少细微的语法错误,在细微流畅度上得到提升。

下图显示了网络结构,黄色为生成器,红色为判别器,每次先生成假样本,传给判别器。得出80%为真还是20%为真,这个reward,对于更新算法的强度有不同的影响。
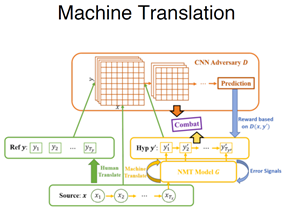
可以看到现在在NLP领域,对抗训练主要做细微事情的调整,传统的RNN或者LSTM在生成过程中已经只能达到一定程度了,但加了对抗训练的话可以精益求精。
下面是生成符合某一类特性的文本,比如餐馆的评价或者商品的评价,生成满意的评价或者不满意的。下面是CMU的工作。

他们是怎么实现的呢?
加入了C,一个额外的变量去控制特征,利用判别器去判别,有没有符合判别器希望生成的特征,最终生成出既满足语言又满足特征。
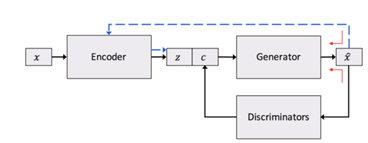
现在controllable-gan 扩展到对话生成上,因为对话中会有很多隐含的情绪,沟通状态,情绪如何,比如下命令和问问题的意图不同的。

未完
-------------------------------------------