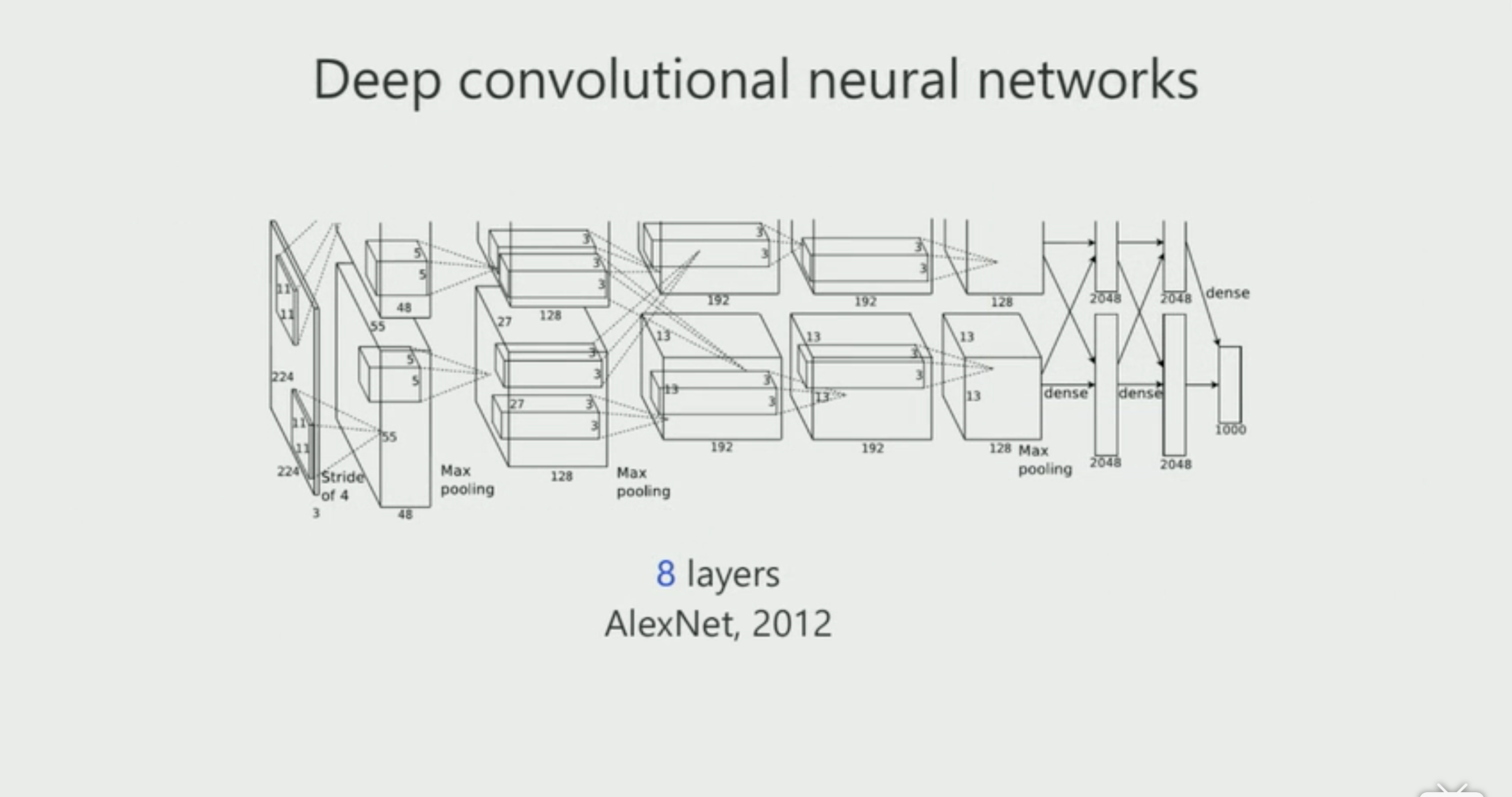
深度学习被引起关注是在2012年,用神经网络训练的一个分类模型在ImagNet上取得了第一名,而且其分类精度比第二名高出10多个点,当时所使用的模型为AlexNet,现在看来其为一个比较简单的网络,而且只有比较浅的八层网络,但是在当时来讲已经很了不起了。这也就引发了后面对神经网络研究的两个方向,以提高网络的分类精度:1.网络变得更深更宽(Going Deeper);2.减少网络中存在的冗余性(Eliminate the Redundancy)。
研究增加网络的深度(Going Deeper)。比如VGGNet,通过增加更多的卷积层和全连接层,变成了一个19层的网络,随着网络深度的加深,会发现带来的训练上的问题:过拟合、梯度消失、梯度爆炸等问题,使得后面的信息不能很好的反馈到前面。基于这些问题,出现了一些新的网络模型:
GoogLeNet提出了inception模块,该模块实现:使用1x1的卷积来进行升维度和降维;多尺寸同时卷积后聚合,并且用了中间层的监督信息,使得信息可以很快的进行反馈。
相继出现的还有Highway、ResNet(前后信息和交融起来)、DenseNet等等。
研究减少网络冗余(Eliminate the Redundancy)。随着网络模型的加深和更宽之后,计算量和memory会越来越大,而在实际的应用中,考虑更多的是如何可以应用一个小的model就可以达到好的分类效果,这就要研究如何减少网络中存在的冗余性。
神经网络中用的最多的操作是卷积,把输入信息设定为矩阵向量,卷积操作就相当于矩阵相乘,一种减少冗余的操作是采用核(kernels)操作,将高维度特征用低维度数据映射,来完成部分线性不可分问题,同时保持在低维度进行运算,从而提高了效率。例如用二值化,就会把矩阵的相乘变成矩阵相加减的运算,或者将其变成整型,通过一些量化的方式将一些相互接近的值采用同一个值来表示。另外一种就是把矩阵行或列减少,减少输入的channel。还有一种是把这个channel变成一个稀疏的(sparse)的矩阵,那么计算量和memory就会随之减少,其中现在很火IGC(Interleaved Group Convolutions)就是采用 structured sparse的结构。
对于一个传统的卷积,假设input channel是六个, 然后output channel是六个,假若卷积为5x5,那么complexity为6x5x5x6,group convolution会将其分为两组,对每一组分别做卷积,那么每一组的complexity为3x5x5x3,总的complexity为2x(3x5x5x3),这样计算量和memory就减少了,但是带来的问题是两组之间没有特征相融,所以需要考虑将特征融合加入进去,提出了第二个IGC,也就是IGCV1,希望第一个group convolution不同组的channel可以在第二个group convolution里融合在一组,这样对于每一个output channel与所有的input channel都是相连的。如果将一个传统的卷积替换为IGC的话,就可以获得相当于原来1/2的memory和计算量的更高精度结果。同时比较了ImageNet上的一个实验,用的18层的ResNets网络,将其卷积变成IGC,获得了在memory更少和计算量更少的情况下,训练误差和验证误差都得到了降低。
另外一个相关的工作是Xception,用一个1x1的卷积,再接一个channel 3x3的卷积,这是一个特例的IGC,把第一个group convolution的组数等于channel数,第二个group convolution的group数等于1。实验比较之后,发现不是在极端的第二个group convolution的group数等于1的情况分类精度最高,而是在第二个group convolution的group数等于2的时候分类精度最高,不过第二个group convolution的计算量还是比较大,所以又进一步的将其中的卷积用IGC来替换,也就是IGCV2,同样的中间网络中的所有output channel与所有的input channel都是相连的。
IGCV2实际上是由一连串的group convolution组成的,在设计的时候需要满足两点:1.矩阵的形式不变,核(kernel)操作矩阵依然是一个稠密(dense)矩阵;2.前后group convolution互补,也就是在前面group convolution里不同组的channel,在后面的group convolution要在同一个组里面,这样最终得到的卷积矩阵也会是一个dense的矩阵。
通过实验比较,在同样的参数量的情况下,通过变换不同的参数,实验表明的满足前后group convolution互补的情况下,最终的结果是最好的。
在模型宽度一样的情况下,如何去选择各种参数,使得模型的参数量最少,也就是Balance condition。当Balance condition满足的时候,可以通过公式计算出参数量。
经过比较,IGCV2能够比IGCV1有更好的提高性能。而且实验表明,IGCV2在小model的情况,对性能的提升是很明显的。
IGCV3
本质上解决了低秩矩阵解决和IGCV2的问题。
将传统的卷积通过group convolution,提出了IGC的单元,把传统的卷积替换为IGC,可以获得一个更小、更快、更准的model。
信息来自:CVPR 2018 中国论文分享会
报告人:张婷 微软研究院
报告题目:Interleaved Structured Sparse Convolutional Neural Networks
论文 IGCV1:Interleaved Group Convolutions for Deep Neural Networks
论文 IGCV2:Interleaved Structured Sparse Convolutional Neural Networks
代码1:Deep Merge-and-Run Nets: https://github.com/zlmzju/fusenet
代码2:Interleaved group convolutions: https://github.com/hellozting/interleavedGroupConvolutons