动机:
目标:想要获得一个实时的模型,且尽可能的准确。
我们有一个大模型性能很好,但是很慢:

我们有个小模型速度很快,但是性能很差:

动机:面临的挑战
1、由于容量和能力,小模型很难达到一个很好的性能。
2、精确度和模型压缩之间的差距还是很大
3、物体检测比分类要困难得多:
a、 标签的计算更加昂贵
b、 类别不均衡
c、多任务同时需要分类和回归
4、直接应用蒸馏在检测模型上并不能很好的工作。
背景,前人的工作:
1、 大网络的加速
a、减少通道的数量 (训练前)
b、剪枝 (训练后)
c、low rank decomposition (低秩分解见下图)
HWS:高宽通道数。D越小越快,D越大总结信息能力越强。 resnet bottlenek 也是同样的道理,FC层也可以分解

压缩一个模型的步骤:

常用的张量分解方式是:Tucker 分解。将4维张量分解为4个小张量
还可以用SVD分解,就要将四位tensor转变成2维的向量,比如(D*D*R1, R2)2 、 进行SVD分解 3、 恢复成D*D的卷积核 和 1*1 的卷积核

2、 提高小网络的性能:
a、设计新的结构(squeeze Net, Binary connection)
b、知识蒸馏
知识蒸馏:
利用已经训练好的模型
用压缩之前的模型作为老师,压缩之后的模型作为学生。
如何模仿呢?
Hints的方法是,老师的分类标签当成人为设定的标签来用。
当然,有人也探索过别的方法,不用标签用标签的前一层,去模仿老师的神经元,而不是模仿标签。
传统标签是one hot。 老师给出的标签只给出概率值。
qi: 是老师给出的每一类的可能性,Zi 是老师预测最终一层的神经元。第i类神经元的指数处以所有神经元的指数
T :温度软化神经元。不会跟人工给的标签一模一样。放大老师的标签,含有丰富的信息量。
为什么要放大呢?
因为老师的标签中可能含有人工标签没有的信息。image中的汽车预测正确的概率是90%,预测成卡车的概率10%,汽车卡车相似性要远高于汽车和人。但是传统标签中汽车预测称人和汽车预测成卡车的概率都是0
但是老师会捕捉到这一点,可以学到人类没有给出但是确实成立的信息。

基于目标检测的模型蒸馏(景驰):
挑战? 1 分类问题+回归问题
2 在大规模数据集上证明其有效性
1、 成功的应用了知识蒸馏对于多类别物体检测问题
2、 提出了新的LOSS函数对于物体检测任务
3 、 在不同的dataset上验证了方法
4、 分析了只是蒸馏的方法在什么条件下是管用的,为什么管用,且解决了神经网络训练中的哪些问题
模型:
1、目标检测使用的比较传统的fastrcnn,wo stage:
a、 随机产生框,不同比例和大小,先用一个网络判断是否有物体,选择很可能物体的框,(RPN网络)
b、 再把框放回一个分类网络中 解决是什么物体的问题(rcnn 区域分类网络)
在分类的过程中每个框由两部分:1、是否是背景还是有物体,车 还是交通灯?
2、调整大小和位置
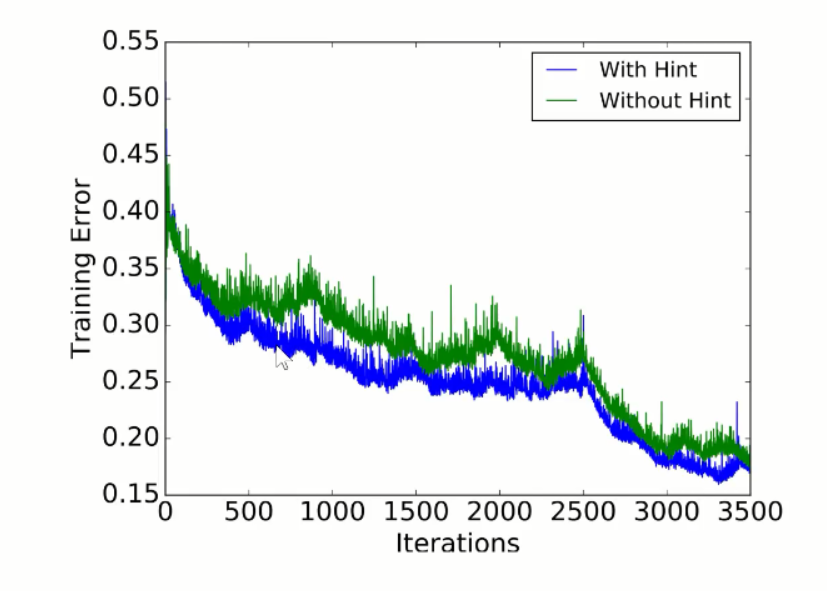
2、在知识蒸馏中,分类和回归都要作为学生学习的目标,不仅仅要学习标签,还让学生网络去学习中间层的一些信息,被证明是很有效的。
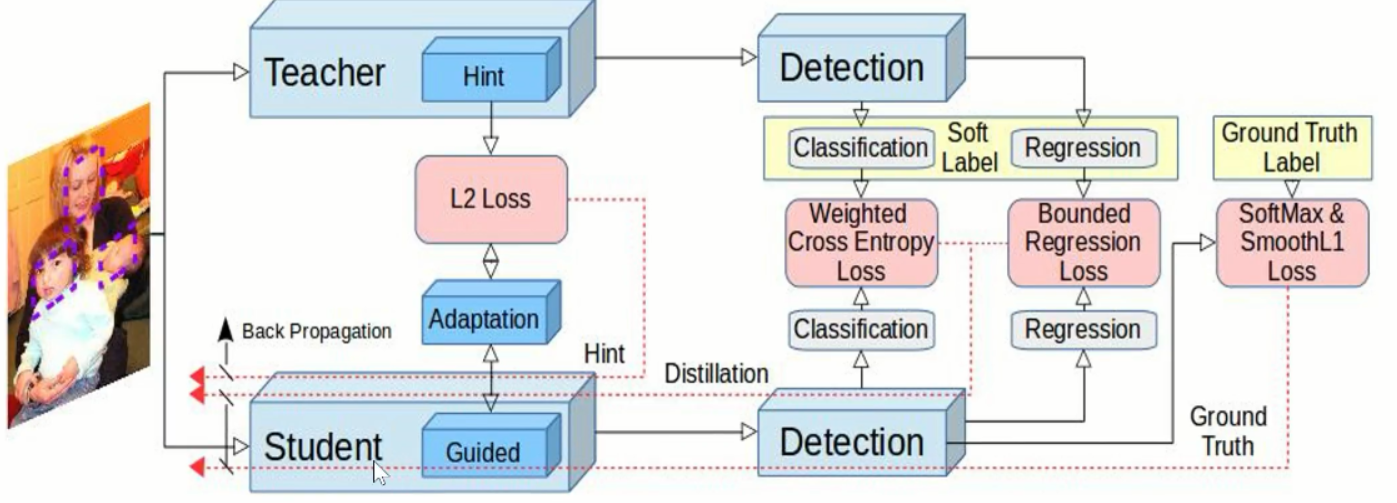
例如:下图中上面非常长的是teacher网路,蓝色的是标签

学生网络:
一方面要学生把老师的输出去学习
另一方面学生的中间层(下图第一块紫色)去尽量模仿老师的某一层。

模仿标签时候,是把老师的标签和学生标签放到一起,接入到一个目标函数,计算反向传播
在模仿中间层的时候并不是直接接目标函数,而是中间加了一个适应层,通过这个适应层使得学生和老师的神经元进行匹配
原因呢?
1、老师和学生尽管有联系,但并不是一一对应的。例如:学生网络比较浅,同一层的神经元看到的区域比较小,老师的一个神经元看到的区域比较大,比较深,直接去匹配是不合适的。
需要进行一些领域的迁移,方便学到有用的信息。
2、卷积网络分卷积层和全连接层。卷积层是一一对应,全连接层是顺序打乱的。
学生和老师每一层里面的神经元,统计上携带的信息可以相比,但是顺序未必是一一对应的,所以要+1层,使其顺序对应。
目标函数:

详细来看呢? Lhard 表示的是:从人工给的标签中学习
Lso'f't 表示的是:从老师给的标签中学习
Lsoft使用的是类似交叉熵,但是给每一类加了不同的权重。是因为目标检测问题和分类问题是不同的:负类远多于正类
回归问题:
不能使用交叉熵,甚至于不能直接使用老师给出的标签。
例如:对于分类问题某个框 70%的概率是一张脸,只盖住了脸的70% 其余是背景
但是对于回归问题:老师给出的是:往右挪10cm才能盖住脸,人给的标签显然是更精准的,老师给的最精准的也无非是挪10cm刚好盖住脸
因此把老师给的当作标签是不合理的。
怎么利用老师给的信息呢?
可以把它当成一个下届来用。比如:当学生预测的比老师还要远的时候,老师预测 老师和人工给的目标更近 ,这个学生做得很差,加倍改正错误
如果学生做的比老师好,就不需要额外的结构学习更多的东西了
所以在这里用了一种把老师的信息当作下届来使用。

学习中间神经元的目标函数:
L2 loss 距离的平方来做的,通过适应层以后,让学生神经元模仿老师神经元的输出。
分析是否知识蒸馏只对特定的老师和学生有用?
比如说:压缩网络得到一个学生,学生参数和老师理应相同,如果是完全不同的网络结构,就不合理了呢?
还有,假设学生和老师的输入是一致的,得到一致的输出,如果不一致呢?
学生在压缩到多少的时候方法管用,压缩的范围是?
工作的流程是:
1,训练一个比较好的网络,来当作老师
2,压缩网络,用SVD或者tucker分解 来压缩
3,最好用imagenet 预训练一个浅层的学生网络
4,用比较深的网络引导学生的训练

下图是将方法,加在不同的学生老师 和不同的数据集上的结果:
最左边是用的经典学生网络:ALEX 7层 VGG是用到最复杂的结构 VGGM 是 VGG16的简化版
Tucker ,是前面提到用tucker分解 压缩alexnet得到的网络结构
第二列是:对于一个学生用不同的老师
可以看到,随着老师越来越好,学生能提高到的精确性也越来越好,例如:Tucker 如果使用VGG16作为引导可以将pascal数据集上精度提升到54.7到59.4 4.7个点
这个数值和老师的70.4 还是有差距,毕竟很深,容量大太多了
有意思的是PASCAL和KITTI都是小数据集,几千到1W
COCO 和ILSVRC 几万到十几万
可以看到,在小数据集上提升很大,在大数据集上提升小,某些情况下还挺大。说明了容量其实是有极限的,知识蒸馏可以帮助召回一些精度,但是很难和复杂网络相媲美

之前提到了很多知识蒸馏的策略,比如:
1、对交叉熵进行加权
2、对于回归问题作为一个上届
3、网络中加一个适应层,去匹配老师的神经元和学生的神经元
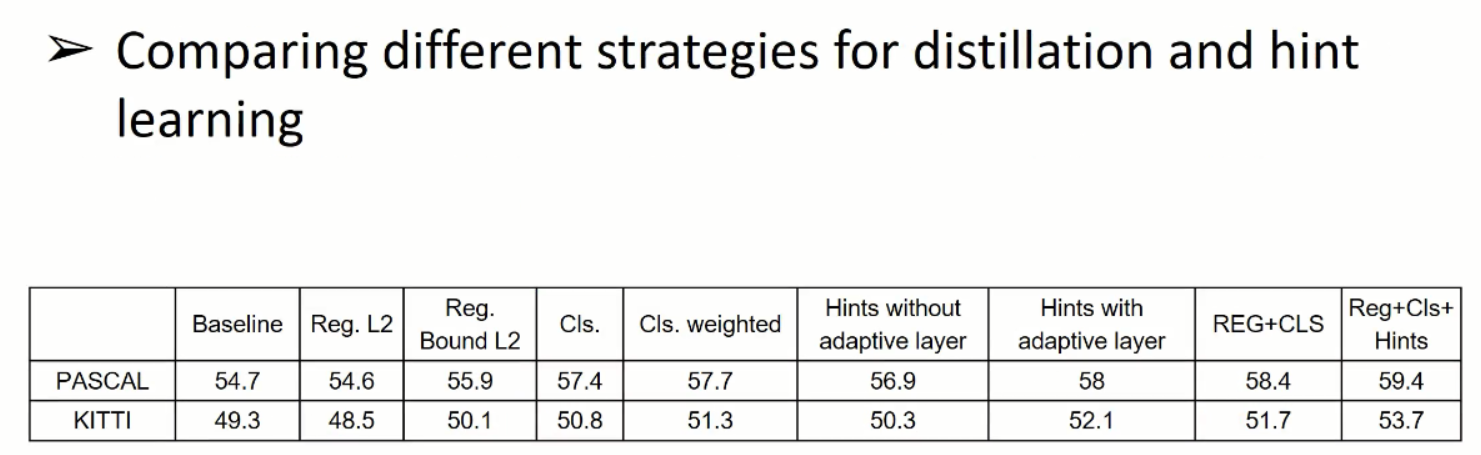
下图说明了这些操作有没有效果,现在小数据集上进行测试,再投放大数据集
第一列是baseline:
第二列是在回归任务中,直接让学生模仿老师,会损害精度,是不如人工给的标签精确的
第三列是把老师作为上届之后提升不少。
后面是是否给分类权重
在后面是去模仿老师神经元的时候,要不要加适应层。
合到一起把之前所有的方法,可以得到最好的精度
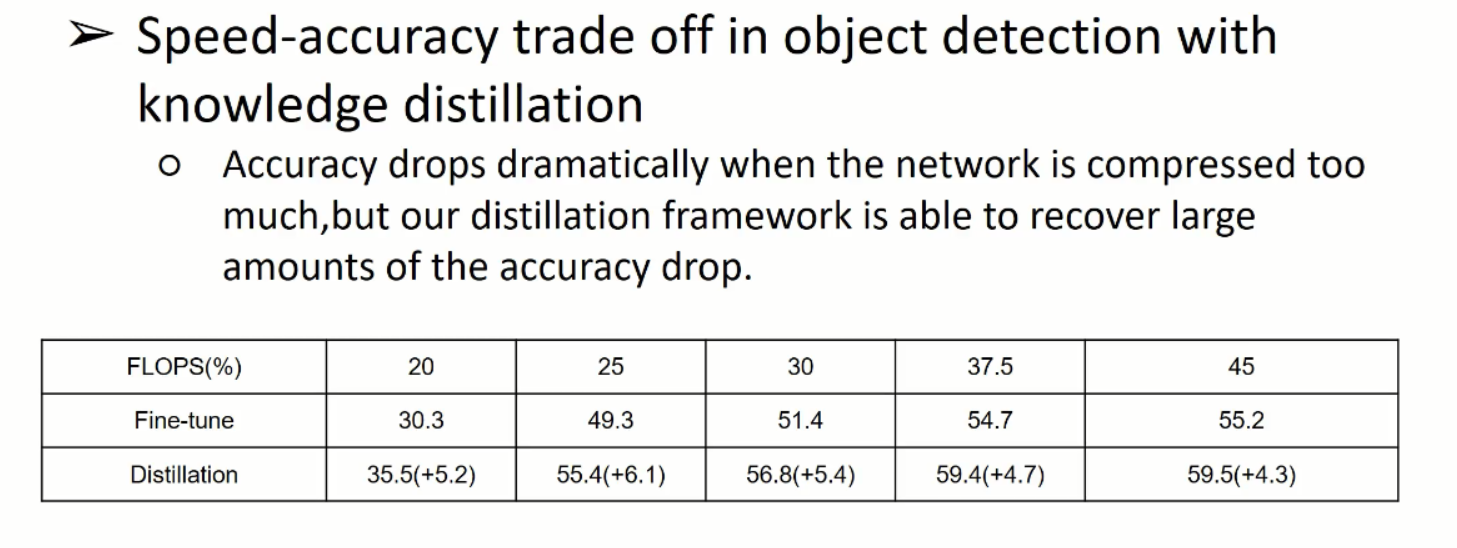
下图是:模型大小和精度之间的关系:
就是蒸馏的极限在哪里?
压缩网络的极限在哪里?什么压缩比,速度和精确性更好的均衡。
所以使用的Tucker
FLOPS 代表的是运算量,FLOPS 20%代表 保留20%的运算量
随着压缩比的提升,实际上知识蒸馏随着压缩比的提高,效果是增加的,比如压缩比在25%的时候,效果提升了+6.1 ,45是只提升+4.3
但是模型容量太小,也不行,只能进行有限的提升
学生和老师的输入是相同,模仿行为是合理的
但是学生和老师输入不相同呢?
都用alexnet 老师看高分辨率的 学生看低分辨率的。毕竟改变大小是提升速度最有效的办法。
可以看到不管是用alexnet作为老师和学生还是压缩过的模型作为老师和学生都有提高

分析一下背后的原理:
为什么知识蒸馏对学生网络会有提升呢?
1、 老师会通过很深的网络学到人类并没有给出但是确实存在的信息。比如:车和卡车更像,和8更像
但是学生网络不能总结出这些信息,让老师交给他,跟容易分类它能力之外的情况
所以它的泛化能力也会相应变强

标签学习为什么会起作用?(知识蒸馏)
知识蒸馏是把网络的输出当成一个标签来用,给出暗藏的信息
但是为什么模仿神经元也是有效的呢?
神经元很难说携带什么信息,每一个卷积对图像不同的位置是有特定的反应的。比如,有些对人脸,有些对电视机
通过模仿神经元的行为,就可以感知到老师是怎么看待这张图像的。
学生网络太浅了,是欠拟合的,训练数据都不能分对,老师欠拟合程度会少一些。
所以:模仿神经元可以帮助学生解决欠拟合的问题,得到更多的信息绕过局部最小和鞍点。

总结一下:
为什么知识蒸馏有用的时候,提到了老师会提供隐含的信息,人类没有给的信息,学生有了这个这个信息以后拟合人类标签的程度是会降低的,解决过拟合问题
模仿神经元解决的是欠拟合的问题。
推测:
如果网络面临是过拟合问题,越教他,在训练集上的表现会越差,至少不会改进
如果欠拟合的问题,对训练集的拟合程度是加深的,也就是说会更加贴合到人类给的标签上去。
但是在实际训练过程中,比如目标检测问题可能同时存在过拟合和欠拟合问题,因为目标检测既要分对前景背景 和 是人是狗,这俩问题同时存在。
所以就做了相应的测试来验证:
知识蒸馏会提升测试的准确性,但是训练的准确性不一定提升。
隐藏神经元学习两个都会提升

得出的结论和预测是一致的:
下图看到在一大一小两个数据集上,知识蒸馏提升了测试的效果,没有提升训练的效果,或者提升很小
模拟神经元会同步的提升

之前提到了过拟合的问题,过拟合解决办法是dropout,用我们的方法(知识蒸馏)和dropout进行对比,下面的绿线是没有知识蒸馏的,也不用模拟神经元,可以看到dropout对他的影响还挺大的,目标检测的最佳比例是0.15. 图像分类最佳是0.5
上面的蓝线是,用了知识蒸馏调节dropout。
可以看到,在不用知识蒸馏和隐藏学习的情况下dropput 影响挺大的,相差了将近0.7.但是用了知识蒸馏相差在0.1,0.2以内,可以下结论说知识蒸馏确实起到了防止过拟合的作用。
但是更严重的欠拟合,模拟神经元有没有提升精度呢? 更快的更精确的拟合人类给的标签
补充:压缩模型的方法,还有很多其他方法,还有很流行的mobilnet和shufflenet。
知识蒸馏和模型压缩是互补的,为了在压缩之后提升精度,这是在不改变任何网络结构的情况下的免费提升
论文的题目:
FAQ: NEC公司决定 代码无法开源
适应层: 并不一定是1*1的卷积层 conv 或者 deconv 比较灵活的层 ,按照 FM size而定,让T和S的神经元数量相匹配
RPN 的标签,分类 :二分类 回归: 框 的回归
RPN 和 RCN的区别是 :一个2分类,一个N+1分类
L2的位置经验:
不要用太浅的层即可
蒸馏网络的温度,使用与出了softmax的其他分类和回归吗? 回归不能直接学老师的
T 二分类问题尽量不要用,应为没有很多隐藏的空间
YOLO也可以在顶层进行蒸馏的,1.2-1.6 如果只对顶层的蒸馏,高度抽象的信息,目标检测有很严重的欠拟合,不一定只对顶层做蒸馏。