第一次个人编程作业——论文查重
林荣胜 031802318
一、作业提交与作业链接
二、计算模块接口的设计与实现过程
1)余弦相似度
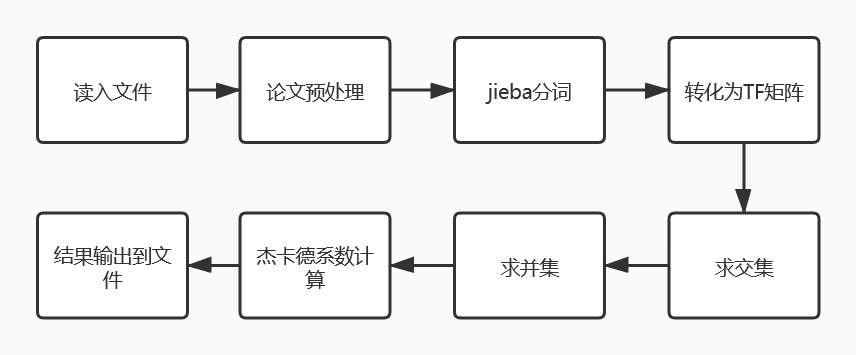
- 流程图
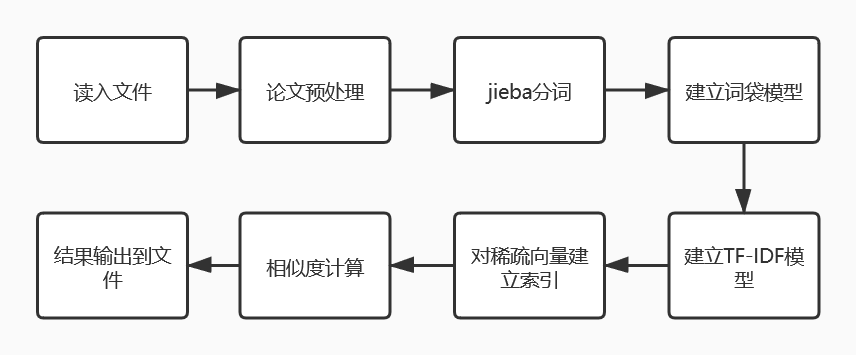
- 接下来以一个简单的例子来讲解如何实现
txt0 = '我在福州'
txt1 = '福州大学有计算机学院'
txt2 = '福州大学在有计算机专业'
txt3 = '福州大学有很多专业'
test = '我在福州大学上计算机专业'
all_txt = []
all_txt.append(txt0)
all_txt.append(txt1)
all_txt.append(txt2)
all_txt.append(txt3)
all_txt_list = []
for txt in all_txt:
#jieba分词
txt_list = [word for word in jieba.cut(txt)]
all_txt_list.append(txt_list)
#jieba分词
test_list = [word for word in jieba.cut(test)]
- 调用jieba库进行了中文词语的分割,print一下all_txt_list和test_list,分词的效果很直观
[['我', '在', '福州'], ['福州大学', '有', '计算机', '学院'], ['福州大学', '在', '有', '计算机专业'], ['福州大学', '有', '很多', '专业']]
['我', '在', '福州大学', '上', '计算机专业']
- 接下来建立词袋模型和TF-IDF模型
#基于上面的四句语句建立词典,每个词对应不同的特征数
dictionary = corpora.Dictionary(all_txt_list)
print(dictionary.token2id)
#基于词典,建立稀疏向量集,即语料库
corpus = [dictionary.doc2bow(txt) for txt in all_txt_list]
print(corpus)
#建立测试语句向量
txt_test_vec = dictionary.doc2bow(test_list)
print(txt_test_vec)
#建立TF-IDF模型,处理稀疏向量集
tfidf = models.TfidfModel(corpus)
- 三个print的结果为
{'在': 0, '我': 1, '福州': 2, '学院': 3, '有': 4, '福州大学': 5, '计算机': 6, '计算机专业': 7, '专业': 8, '很多': 9}
[[(0, 1), (1, 1), (2, 1)], [(3, 1), (4, 1), (5, 1), (6, 1)], [(0, 1), (4, 1), (5, 1), (7, 1)], [(4, 1), (5, 1), (8, 1), (9, 1)]]
[(0, 1), (1, 1), (5, 1), (7, 1)]
- 稀疏矩阵相似度计算
#对稀疏向量建立索引
index = similarities.SparseMatrixSimilarity(tfidf[corpus], num_features=len(dictionary.keys()))
#进行相似度的计算
sim = index[tfidf[txt_test_vec]]
print(sim)
- 得到最终四句话与测试语句的相似度
[0.5503141 0.01968957 0.73873365 0.01968957]
- 至于相似度如何计算,查了一下官网的API,只说明了采用余弦相似度,但与自己计算出来的cos结果总有略微的差别,可能API使用了什么黑科技吧,以后查到了原因再补充,这里先给出余弦计算公式
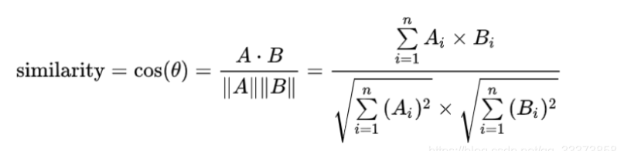
基于上述的例子,对此次的论文测试样例进行编写代码测试
- 由于论文中包含大量的标点符号、数字、空格、换行等,所以先进行数据预处理,将这些非中文的字符全部删掉,得到结果如下(其中myself_test.txt是关于毛概的,myself_test2.txt是关于计算机导论的)
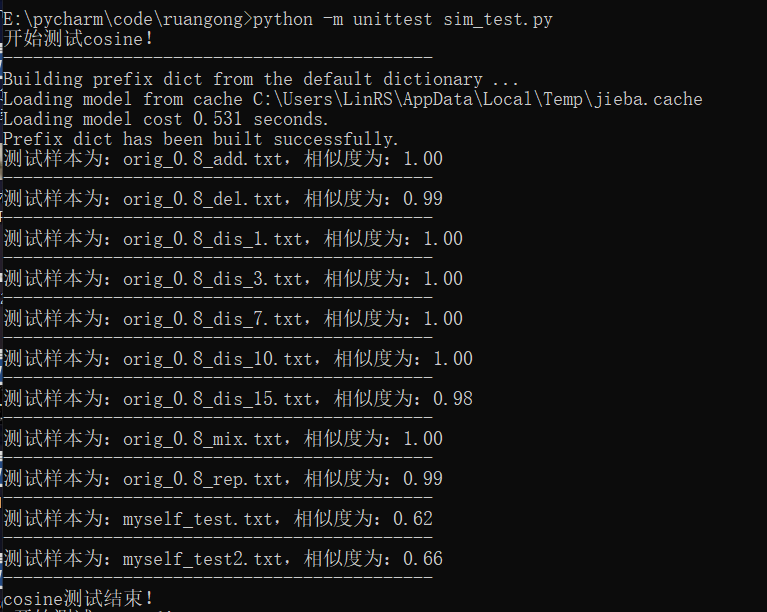
- 从结果来看,对于改论文的抄袭论文,该算法都以接近1的相似度来判断,对于我自己做的两个测试集,也有60%+的相似度。这很明显,该算法计算的相似度不切合实际的文本相似度。两个与《活着》毫不相关的文本,相似度自然不可能达到60%+!
- 找了找网上的代码,发现很多文本处理,在预处理阶段,都进行了停用词的删除。不过,作业要求不能读取其他文件,那就自己先测试测试,看看有没有用……(停用词表可以从我的Github上下载,还包括了中文停用词表、百度停用词表、四川大学停用词表,点击这里下载)
#进行停用词的删除也很简单,循环一下
stop_words = open('hit_stopwords.txt', 'r', encoding='utf-8').read()
temp = [word for word in jieba.cut(file)]
result = []
for item in temp:
if item not in stop_words:
result.append(item)
-
再看看测试结果,只能说停用词表牛逼,确实有用。也就是说,如果能在停用词表的基础上,再增加中文词库中一些对判断文本相似度没用的词语,比如他、今天、明天、后天等,这些词都不在哈工大停用词表中。当然,增加停用词表只能够适用于大文本的相似度检测,对于上面举的例子语句,经过分词后再删除停用词,很可能都把字典或者语料库删光了。

-
因为不能读取文件,所以上面的方法就pass掉了,重新找一个度量的算法,于是乎,查到了篇博客,讲的很好参考博客链接。在这篇博客的启发下,决定选取Jaccard相似度
2)Jaccadr相似度
- 杰卡德相似度,严格来说应该叫杰卡德系数(百度百科上面这样写的)。从定义的角度上来说,就是A与B交集的大小与A与B并集的大小的比值,用于比较有限样本集之间的相似性与差异性,系数值越高,文本相似度越高
- Jaccadr系数公式
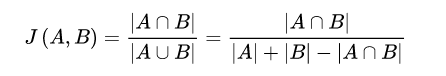
- 针对文本相似度这一应用场景,选择算法基于广义的Jaccadr系数公式
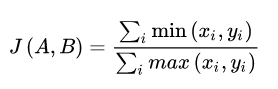
- 流程图
- 同样的,再次以一个简单的例子来讲解该算法
txt0 = '我在福州大学'
txt1 = '我在数计学院'
#对txt0和txt1进行简单的空格分词,转换为TF矩阵为
['在', '大', '学', '州', '我', '数', '福', '计', '院']
#对于TF矩阵,txt0和txt1对应的向量分别为
[[1 1 1 1 1 0 1 0 0]
[1 0 1 0 1 1 0 1 1]]
#根据广义的Jaccadr相似度计算
a = 数组每一列的最小值相加 = 1 + 0 + 1 + 0 + 1 + 0 + 0 + 0 + 0 = 3
b = 数组每一列的最大值相加 = 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 = 9
result = a / b = 0.3333333
#文本相似度为0.3333333
-
对于论文的查重,当然不能简单进行地进行空格分词,于是加入jieba,并进行测试,得到结果如下。确实,该方法比余弦相似度得出的结果更具有可信度
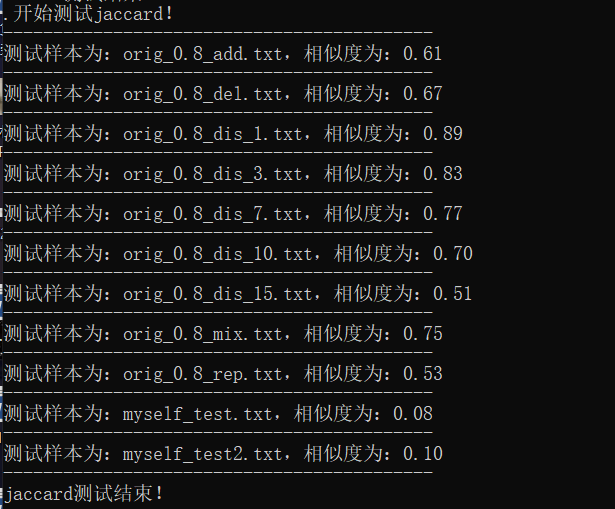
-
再试试加入停用词,相比之下,我认为加入停用词的测试结果更贴合实际,相似度都有所减小。有的抄袭论文测试点相似度只有0.41、0.43等,但由于算法中是使用jieba分词,这些测试点是在原文基础上进行的字符串变化,因而有很多词语不是正常地被分词(实际生活中的抄袭论文应该也不会像测试点这么特殊,大体上词序是正确的,能正常地分词)。对于我自己生成的无关测试点,测试的结果就很不错。

- 所有方法的源代码将会放在Github中,其中作业提交代码为main.py,采用杰卡德无停用词算法。
三、计算模块接口部分的性能改进
1)文本相似度
- 两种算法的具体实现和最终计算结果在前面已经展示过了。在我心中的认可度为:杰卡德+停用词 > 杰卡德 > 余弦+停用词 > 余弦
2)时间花费
- 为了方便,我将主要步骤放在同一个函数中,使用line_profiler比较杰卡德与余弦两种算法的时间花费(均未加停用词)
- 余弦算法时间花费,总时间为0.925s,花费最多时间的步骤为jieba分词
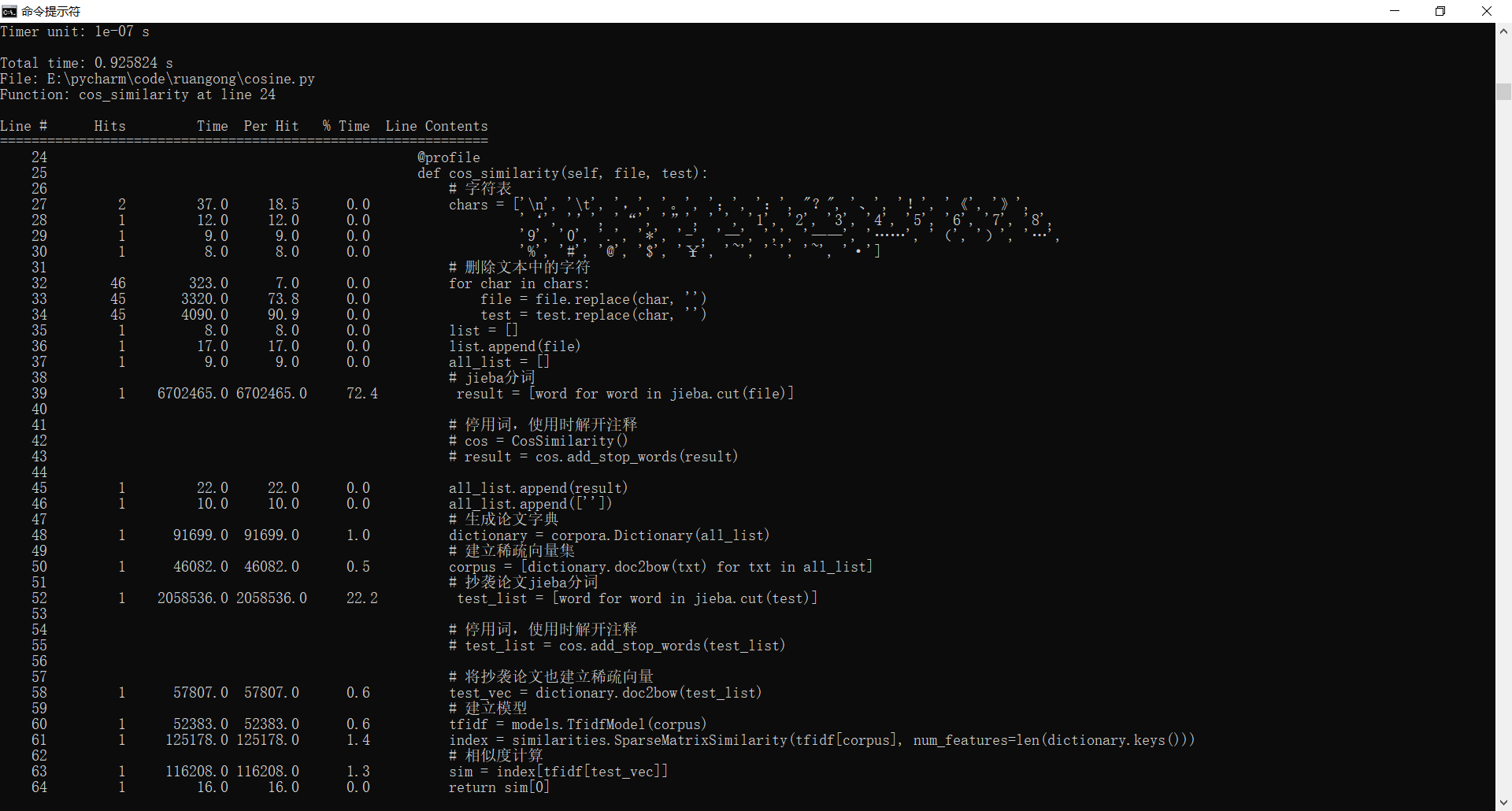
- 杰卡德算法时间花费,总时间约为0.67s,花费最多时间的步骤为字符串拼接
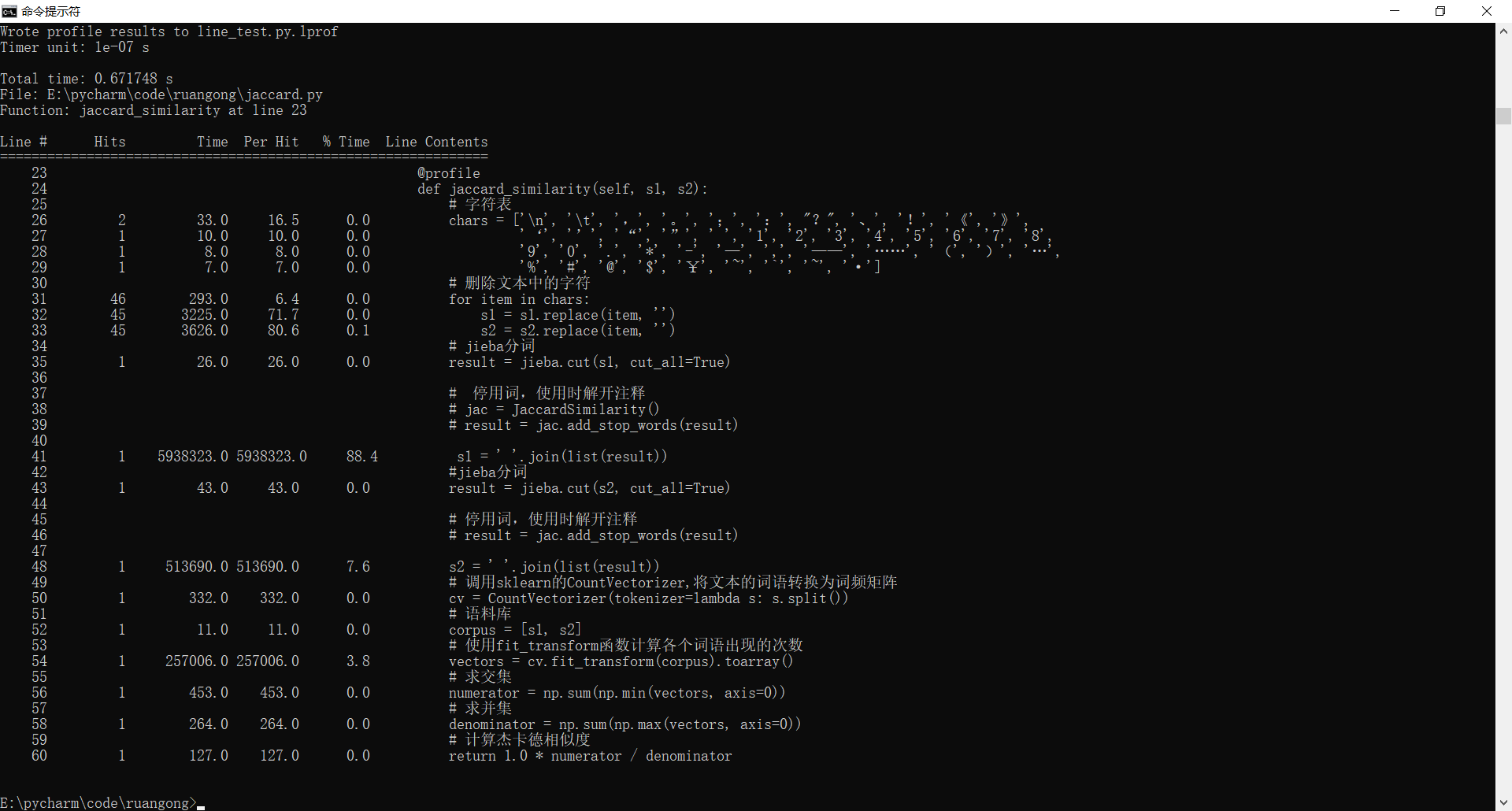
从结果可以看出杰卡德更快!
3)内存占用
- 同样地,将算法主要步骤放在同一个函数中,使用memory_profiler比较两种算法的内存占用(均未加停用词)
- 余弦内存占用169.5MiB(MiB略大于MB,为2的20次方B)

- 杰卡德内存占用167.965MiB
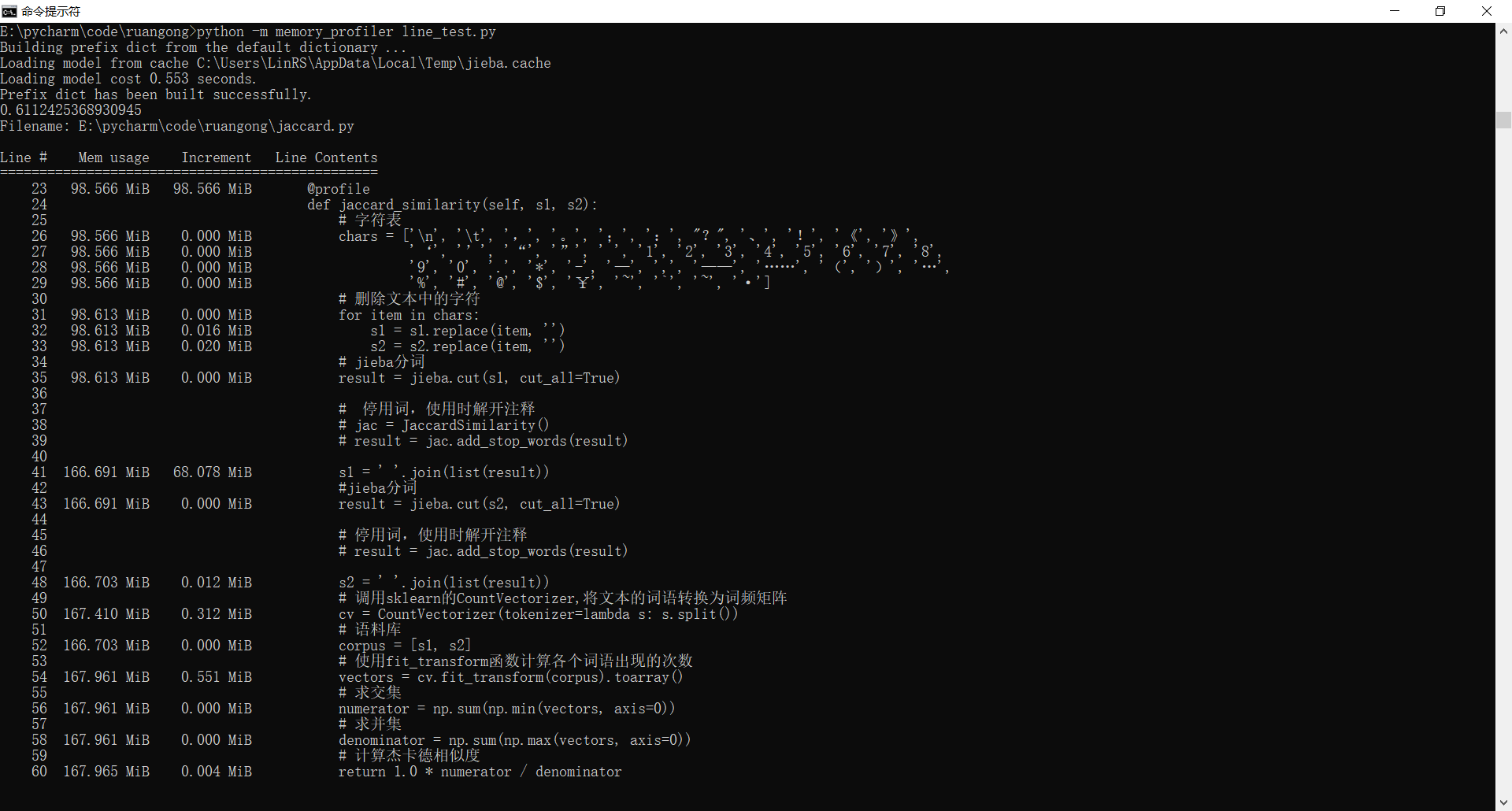
从结果可以看出杰卡德占用内存更少!
四、计算模块部分单元测试展示
1)测试代码
import unittest
from cosine import CosSimilarity
from jaccard import JaccardSimilarity
from diy_exception import NoWordError, SimIsOneError, DeleteAllWordsError
file = open('orig.txt', 'r', encoding='utf-8').read()
test = {}
test['orig_0.8_add.txt'] = open('orig_0.8_add.txt', 'r', encoding='utf-8').read()
test['orig_0.8_del.txt'] = open('orig_0.8_del.txt', 'r', encoding='utf-8').read()
test['orig_0.8_dis_1.txt'] = open('orig_0.8_dis_1.txt', 'r', encoding='utf-8').read()
test['orig_0.8_dis_3.txt'] = open('orig_0.8_dis_3.txt', 'r', encoding='utf-8').read()
test['orig_0.8_dis_7.txt'] = open('orig_0.8_dis_7.txt', 'r', encoding='utf-8').read()
test['orig_0.8_dis_10.txt'] = open('orig_0.8_dis_10.txt', 'r', encoding='utf-8').read()
test['orig_0.8_dis_15.txt'] = open('orig_0.8_dis_15.txt', 'r', encoding='utf-8').read()
test['orig_0.8_mix.txt'] = open('orig_0.8_mix.txt', 'r', encoding='utf-8').read()
test['orig_0.8_rep.txt'] = open('orig_0.8_rep.txt', 'r', encoding='utf-8').read()
test['myself_test.txt'] = open('myself_test.txt', 'r', encoding='utf-8').read()
test['myself_test2.txt'] = open('myself_test2.txt', 'r', encoding='utf-8').read()
# 同时测试两种算法对于测试样例计算的相似度
class Testsim(unittest.TestCase):
def test_cosine(self):
cos = CosSimilarity()
print('开始测试cosine!')
print('-------------------------------------------')
for key in test.keys():
result = cos.cos_similarity(file, test[key])
print('测试样本为:%s,相似度为:%.2f' % (key, result))
print('-------------------------------------------')
print('cosine测试结束!')
def test_jaccard(self):
jac = JaccardSimilarity()
print('开始测试jaccard!')
print('-------------------------------------------')
for key in test.keys():
result = jac.jaccard_similarity(file, test[key])
print('测试样本为:%s,相似度为:%.2f' % (key, result))
print('-------------------------------------------')
print('jaccard测试结束!')
if __name__ == '__main__':
unittest.main()
2)代码覆盖率截图

3)测试数据的思路
- 此次测试了11个数据样本,其中9个为作业提供的抄袭论文样本,另外2个为与论文不相关的文本。在此次测试中,并没有加入停用词表,如果想要测试加入停用词表的结果,可以将我上传到Github的代码的停用词表相关注释解注释。同时,此次测试均设置不抛出异常
五、计算模块部分异常处理说明
1)自定义异常代码
class NoWordError(Exception):
def __init__(self):
print('该文件没有文字!')
class SimIsOneError(Exception):
def __init__(self):
print('两个文件是不同的文件!相似度不可能为1!')
class DeleteAllWordsError(Exception):
def __init__(self):
print('该文件被你在删除停用词的时候都删光了!')
2)异常解释以及各个异常测试样例
1、NoWordError
- 该异常为读入文件没有任何字符,即空文件时,报出的异常
- 异常的测试样例设置为myself_test3.txt,测试结果如下

2、SimIsOneError
- 该异常为两个不是相同的文件,相似度却为1时,报出的异常
- 异常的测试样例设置为orig_0.8_add.txt(其实使用余弦相似度计算该样本结果时,结果并不为1,但是结果与1十分接近,保留2位小数时,采取四舍五入后,计算结果记为1),测试结果如下

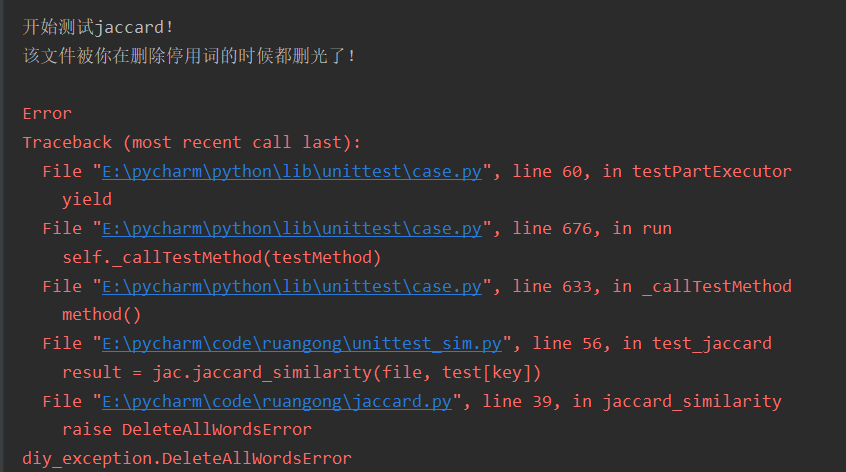
3、DeleteAllWordError
- 该异常为在删除停用词后,文本为空时,报出的异常
- 异常的测试样例设置为myself_test4_txt,测试结果如下
六、PSP表格分析
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 60 |
| Estimate | 估计这个任务需要多少时间 | 60 | 30 |
| Development | 开发 | 600 | 900 |
| Analysis | 需求分析(包括学习新技术) | 120 | 180 |
| Design Spec | 生成设计文档 | 60 | 120 |
| Design Review | 设计复审 | 20 | 20 |
| Coding Standard | 代码规范( 为目前的开发制定合适的规范) | 20 | 10 |
| Design | 具体设计 | 60 | 60 |
| Coding | 具体编码 | 40 | 100 |
| Code Review | 代码复审 | 30 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 200 |
| Reporting | 报告 | 150 | 300 |
| Test Repor | 测试报告 | 30 | 60 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 30 | 40 |
| 合计 | 1350 | 2120 |