一、开发爬虫的步骤
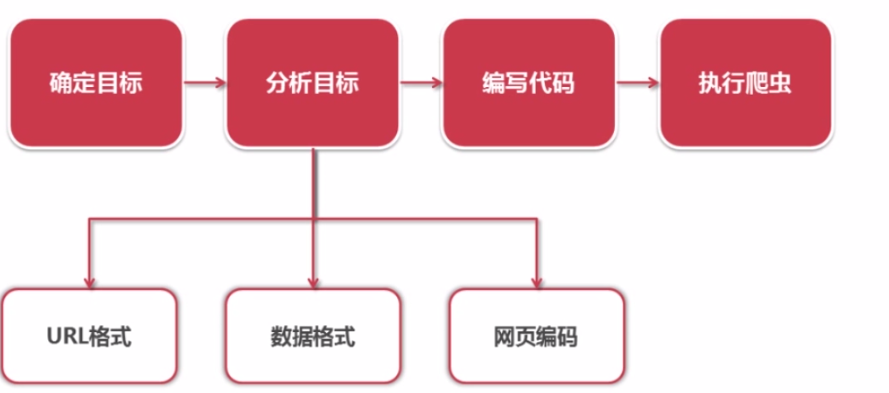
1.确定目标抓取策略:
打开目标页面,通过右键审查元素确定网页的url格式、数据格式、和网页编码形式。
①先看url的格式, F12观察一下链接的形式;
② 再看目标文本信息的标签格式, 比如文本数据为div class="xxx",
③ 容易看到编码为utf-8
2.分析目标
目标: 百度百科python词条
入口页: http://baike.baidu.com/item/Python
词条页面url格式:/item/****
数据格式:
标题: <dd class="lemmaWgt-lemmaTitle-title"><h1>****</h1></dd>
简介: <div class = "lemma-summary">****</div>
页面编码: utf-8
3.实例代码
爬取百度百科Python词条以及相关的1000个页面数据