1. 实验要求
- 以fork和execve系统调用为例分析中断上下文的切换
- 分析execve系统调用中断上下文的特殊之处
- 分析fork子进程启动执行时进程上下文的特殊之处
- 以系统调用作为特殊的中断,结合中断上下文切换和进程上下文切换分析Linux系统的一般执行过程
2. fork系统调用
2.1 分析fork系统调用的上下文切换
fork() 系统调用将创建一个与父进程几乎一样的新进程,之后继续执行下面的指令。程序可以根据 fork() 的返回值,确定当前处于父进程中,还是子进程中——在父进程中,返回值为新创建子进程的进程 ID,在子进程中,返回值是 0。一些使用多进程模型的服务器程序(比如 sshd),就是通过 fork() 系统调用来实现的,每当新用户接入时,系统就会专门创建一个新进程,来服务该用户。
fork() 系统调用所创建的新进程,与其父进程的内存布局和数据几乎一模一样。在内核中,它们的代码段所在的只读存储区会共享相同的物理内存页,可读可写的数据段、堆及栈等内存,内核会使用写时拷贝技术,为每个进程独立创建一份。
在 fork() 系统调用刚刚执行完的那一刻,子进程即可拥有一份与父进程完全一样的数据拷贝。对于已打开的文件,内核会增加每个文件描述符的引用计数,每个进程都可以用相同的文件句柄访问同一个文件。
为了直观地理解fork系统调用,编写了forkTest.c程序,如下所示:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
void main(){
int pid;
printf("before fork
");
pid = fork();
if(pid<0){
perror("fork failed
");
exit(1);
}
if (pid == 0){
printf("Child process
");
}else {
printf("parent process
");
}
printf("after fork
");
}
然后编译forkTest.c为forkTest可执行文件,放到内存根文件系统的home目录下,重新编译并重新制作根文件系统镜像,在qemu虚拟机下运行forkTest程序。
gcc -o forkTest forkTest.c -static#静态编译forkTest可执行程序
find . -print0 | cpio --null -ov --format=newc | gzip -9 > ../rootfs.cpio.gz#重新制作根文件系统镜像
qemu-system-x86_64 -kernel linux-5.4.34/arch/x86/boot/bzImage -initrd rootfs.cpio.gz -nographic -append "console=ttyS0" #在终端下启动qemu虚拟机,并挂载根文件系统
执行的结果如下:

可以看到,cpu先执行了父进程中的三条输出语句,然后再执行了创建出来的子进程中的两个输出语句。子进程中“before fork”语句没有执行,说明父进程创建出来的子进程,得到cpu调度后,是从“pid = fork();”语句后面开始执行的。
在以上的程序中,当父进程也就是main函数,调用了fork()库函数后,之后到底发生了什么呢?我们不妨来分析下:
第一步: 父进程调用c语言的fork()库函数,编译器去arch/x86/entry/syscalls/syscall_64.tbl 中寻找对应的系统调用号,如图所示对应56,57,58号系统调用号:

第二步:有了系统调用号之后,就可以找到相应的入口地址,执行相应的服务程序:
fork函数定义在linux-5.4.34/kernel/fork.c文件中,如下图,fork、vfork和 clone这3个系统调⽤,以及do_fork和 kernel_thread内核函数都可以创建⼀个新进程,且都是通过_do_fork函数来创建进程,只不过传递的参数不同。

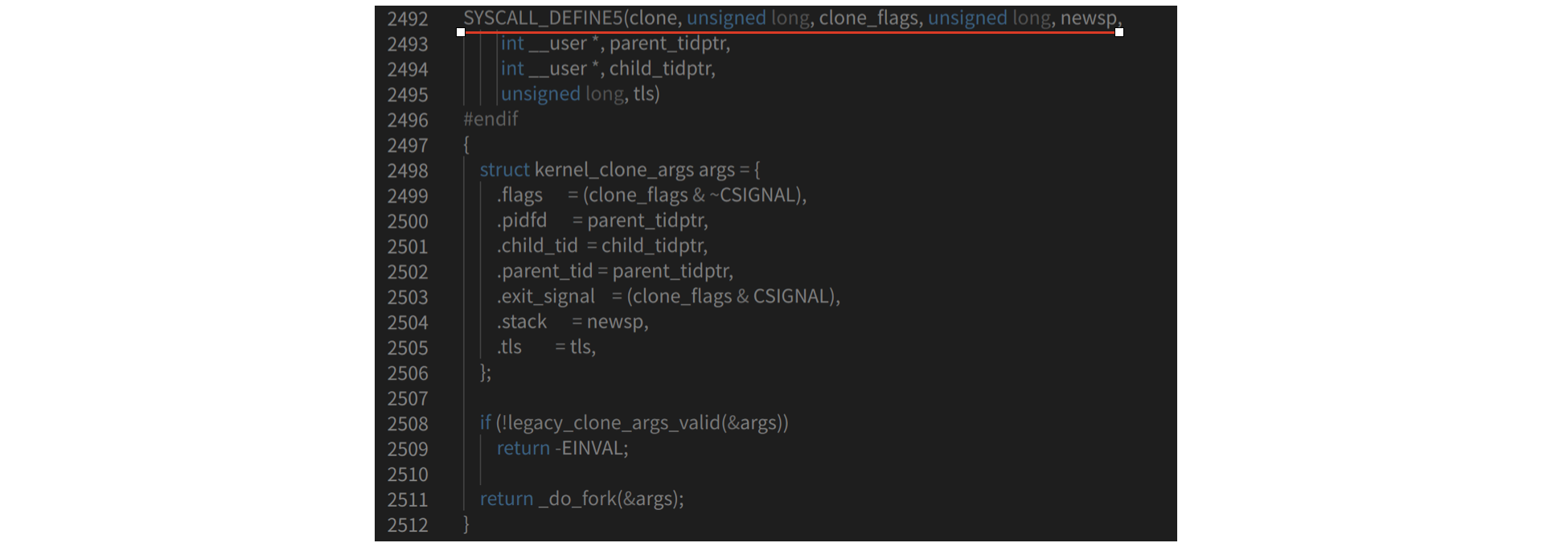
第三步:理解fork.c文件中的_do_fork函数:
从代码中可以看到,_do_fork()函数是通过copy_process()函数复制子进程。
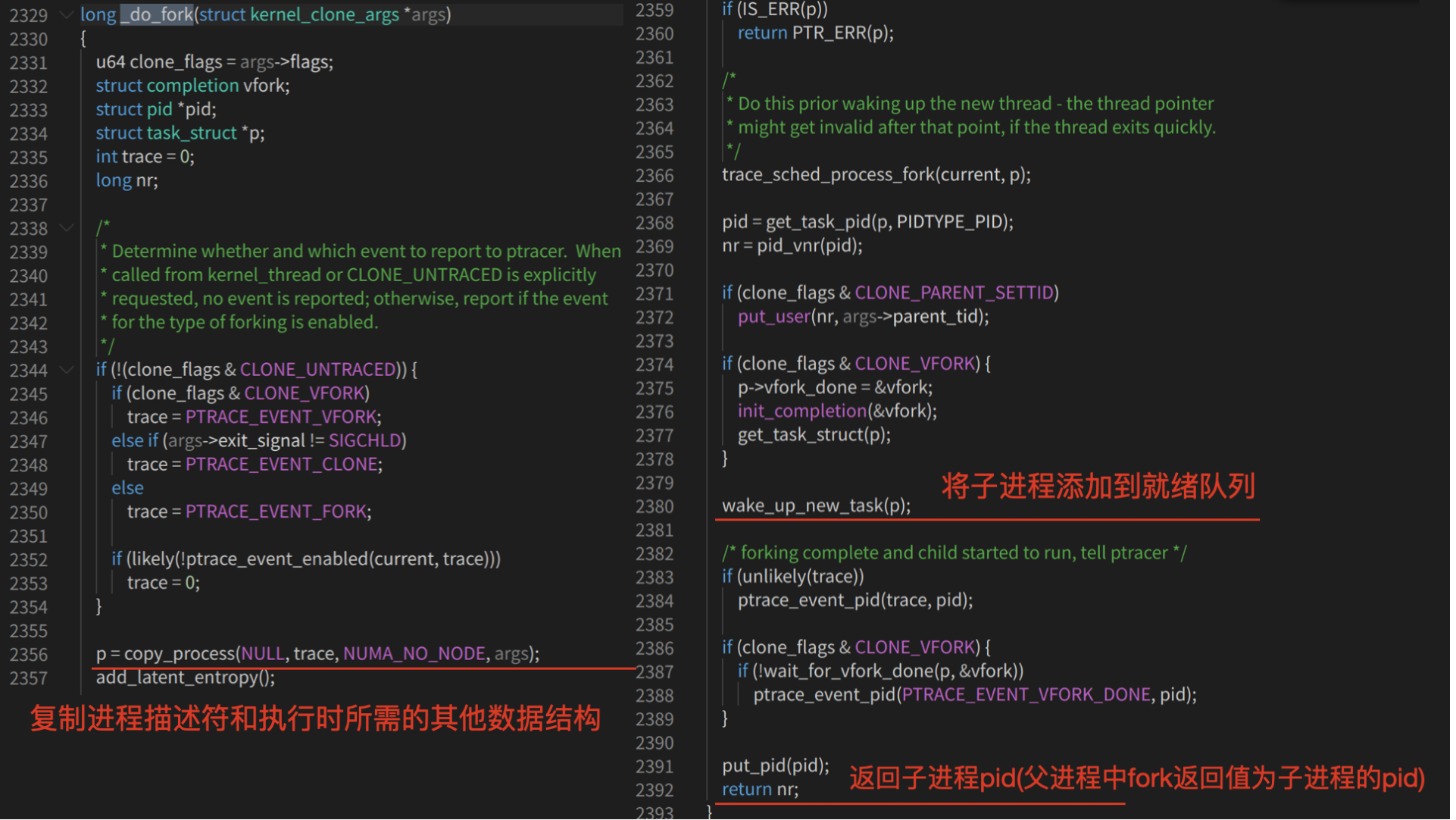
第四步:理解copy_process()函数复制父进程的过程:
部分代码截图如图所示;
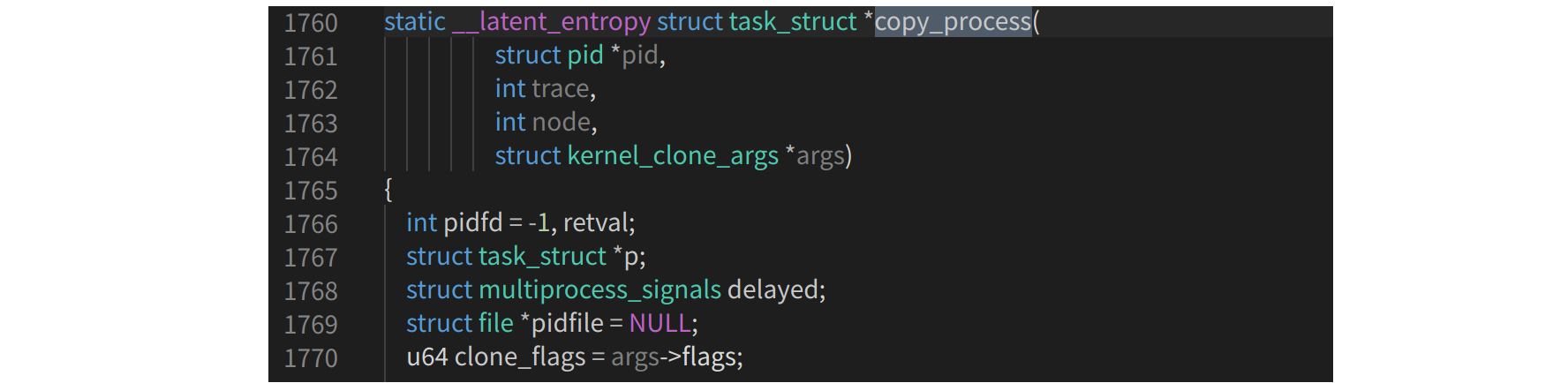
根据老师上课时的讲解,简化后的代码如图所示;

从代码中可以看到,copy_process()函数主要完成了调用dup_task_struct复制当前进程(父进程)描述符task_struct、信息检查、初始化、把进程状态 设置为TASK_RUNNING(此时子进程置为就绪 态)、采用写时复制技术逐一复制所有其他进 程资源、调用copy_thread_tls初始化子进程内核栈、设置子进程pid等。其中最关键的就是 dup_task_struct复制当前进程(父进程)描述 符task_struct和copy_thread_tls初始化子进程内核栈。
总结来说,进程的创建过程大致是父进程通过fork系统调用进入内核_do_fork函数,复制进程描述符及相关进程资源(采用写时复制技术)、分配子进程的内核堆栈并对内核堆栈和thread等进程关键上下文进行初始化,最后将子进程放入就绪队列,fork系统调用返回;而子进程则在被调度执行时根据设置的内核堆栈和thread等进程关键上下文开始执行。
2.2 fork子进程启动执行时进程上下文的特殊之处
fork和其他系统调⽤不同之处是它在陷⼊内核态之后有两次返回,第⼀次返回到原来的⽗进程的位置继续向下执⾏,这和其他的系统调⽤是⼀样的。第二次返回是在⼦进程中,会返回到⼀个特定的点——ret_from_fork,通过内核构造的堆栈环境,它可以正常系统调⽤返回到⽤户态。
3. execve系统调用
3.1 分析execve系统调用的上下文切换
execve() 系统调用的作用是运行另外一个指定的程序。它会把新程序加载到当前进程的内存空间内,当前的进程会被丢弃,它的堆、栈和所有的段数据都会被新进程相应的部分代替,然后会从新程序的初始化代码和 main 函数开始运行。同时,进程的 ID 将保持不变。
execve() 系统调用通常与 fork() 系统调用配合使用。从一个进程中启动另一个程序时,通常是先 fork() 一个子进程,然后在子进程中使用 execve() 变身为运行指定程序的进程。 例如,当用户在 Shell 下输入一条命令启动指定程序时,Shell 就是先 fork() 了自身进程,然后在子进程中使用 execve() 来运行指定的程序。
execve() 系统调用的函数原型为:
int execve(const char *filename, char *const argv[], char *const envp[]);
filename 用于指定要运行的程序的文件名,argv 和 envp 分别指定程序的运行参数和环境变量。除此之外,该系列函数还有很多变体,它们执行大体相同的功能,区别在于需要的参数不同,包括 execl、execlp、execle、execv、execvp、execvpe 等。
Linux系统一般会提供了execl、execlp、execle、execv、execvp和execve等6个用以加载执行 一个可执行文件的库函数,这些库函数统称为exec函数,差异在于对命令行参数和环境变量参数 的传递方式不同。exec函数都是通过execve系统调用进入内核,对应的系统调用内核处理函数为 sys_execve或__x64_sys_execve,它们都是通过调用do_execve来具体执行加载可执行文件的 工作。
整体的调用关系为sys_execve()或x64_sys_execve -> do_execve() –> do_execveat_common() -> do_execve_file -> exec_binprm()-> search_binary_handler() ->load_elf_binary() -> start_thread()。
3.2 execve系统调用中断上下文的特殊之处
当前的可执行程序在执行,执行到execve系统调用时陷入内核态,在内 核里面用do_execve加载可执行文件,把当前进程的可执行程序给覆盖掉。当execve系统调用返回 时,返回的已经不是原来的那个可执行程序了,而是新的可执行程序。execve返回的是新的可执行 程序执行的起点,静态链接的可执行文件也就是main函数的大致位置,动态链接的可执行文件还需 要ld链接好动态链接库再从main函数开始执行。
4. Linux系统的一般执行过程
下图就是中断上下文切换和进程上下文切换的一般过程:
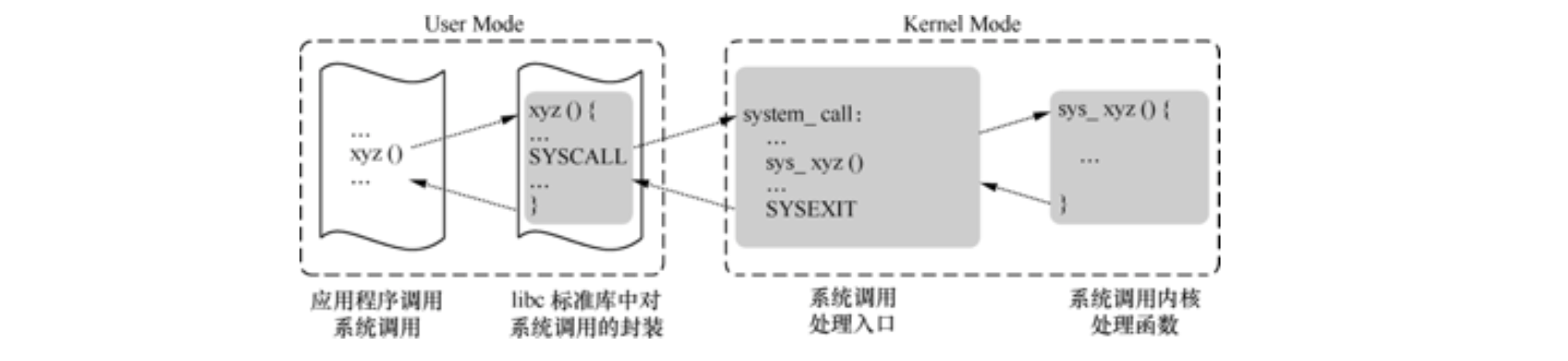
libc标准库中对系统调用进行了封装,使得应用程序可以通过c语言的系统调用API来实现系统调用的功能。在正常触发系统调用时,用户态有一个int $0x80或syscall指令触发系统调用,跳转到系统调用入口的汇编代码。int $0x80指令触发entry_INT80_32并以iret返回系统调用,syscall指令触发entry_SYSCALL_64并sysret或iret返回系统调用。
系统调用陷入内核态,从用户态堆栈转换到内核态堆栈,然后把相应的CPU关 键的现场栈顶寄存器、指令指针寄存器、标志寄存器等保存到内核堆栈,保存现 场。系统调用入口的汇编代码还会通过系统调用号执行系统调用内核处理函数, 最后恢复现场和系统调用返回将CPU关键现场栈顶寄存器、指令指针寄存器、 标志寄存器等从内核堆栈中恢复到对应寄存器中,并回到用户态int $0x80或 syscall指令之后的下一条指令的位置继续执行。