一、Linux&Shell
1.1 Linux常用高级命令
1)top:查看内存
2)df -h:查看磁盘存储情况
3)iotop:查看磁盘IO读写情况(sudo yum install iotop)
4)iotop -o:查看较高的磁盘IO读写程序
5)netstat -nlpt | grep 端口号:查看端口占用情况
6)uptime:查看报告系统运行时长及平均负载
7)pa -aux:查看进程
1.2 Shell常用工具及写过的脚本
1.2.1 常用工具
1)awk
2)sed
3)cut
4)sort
1.2.2 用shell写过哪些脚本
1)集群启动,分发脚本
2)数仓与Mysql的导入导出
3)数仓层级内部的导入
1.2.3 Shell中提交了一个脚本,进程号已经不知道了,但是需要kill掉这个进程,怎么操作?
ssh $i "ps -ef | grep file-flume-kafka | grep -v grep | awk '{print \$2}' | xargs kill"
1.2.4 Shell中单引号和双引号的区别
1)单引号不取变量值
2)双引号取变量值
3)反引号`,执行引号中的命令
4)双引号内部嵌套单引号,取出变量值
5)单引号内部嵌套双引号,不取出变量值
二、Hadoop
2.1 Hadoop常用端口号
1)访问HDFS:9870
2)查看MR执行情况:8088
3)客户端访问集群端口:8020
4)历史服务器:19888
2.2 Hadoop配置文件以及简单的Hadoop集群搭建
2.2.1 配置文件
1)core-site.xml
2)hdfs-site.xml
3)mapred-site.xml
4)yarn-site.xml
5)workers
2.2.2 简单的集群搭建过程
1)JDK的安装
2)配置SSH免密登录
3)配置hadoop核心文件
4)格式化namenode
2.2.3 HDFS读写流程
2.2.3.1 读流程
1)首先HDFS客户端创建Distributed FileSystem
2)然后想NameNode请求下载文件
3)NameNode接收到请求后给客户端返回目标文件的元数据
4)客户端接收到元数据后创建输入流FSDataInputStream
5)根据获取到的元数据信息开始向DataNode发送读请求
6)DataNode收到读请求后开始传输数据至客户端
7)传输完成后客户端关闭输入流FSDataInputStream
2.2.3.2 写流程
1)首先客户端创建Distributed FileSystem
2)然后客户端想NameNode请求上传文件
3)NameNode收到写请求后向客户端响应可以上传文件
4)客户端收到可以上传文件的响应后开始向NameNode请求上传相应的块文件,并获取DataNode信息
5)NameNode收到请求后返回DataNode节点信息给客户端,表示这些DataNode节点可以存储数据
6)客户端得到DataNode节点信息后开始创建输出流FSDataOutputStream
7)客户端根据获取到的DataNode节点信息找到相应的DataNode,并向DataNode请求建立Block传输通道
8)DataNode接收到请求后建立通道,并响应给客户端
9)客户端收到DataNode响应后开始传输数据
10)传输完成后客户端向NameNode发送传输已完成的信息
11)客户端关闭输出流FSDataOutputStream
2.2.4 HDFS小文件处理
2.2.4.1 有什么影响?
一个文件块的元数据信息占用NameNode150字节的内存,如果有1亿个小文件,则需要占用的元数据内存容量 = 1亿*150字节
若一台主句内存是128G,则能存储的文件块数量 = 128 * 1024*1024*1024byte/150字节 = 9亿文件块
2.2.4.2 怎么解决?
1)采用har归档,将小文件归档
2)采用CombineTextInputFormat,合并小文件
3)开启JVM重用(会一直占用使用到的task卡槽,直到任务完成后才释放)
2.2.5 Shuffle及优化
2.2.5.1 Shuffle过程
1)客户端submit()之前,获取待处理的数据信息,然后根据获取到的信息以及相关的参数属性配置,得到任务规划信息
2)客户端计算出任务规划信息后开始submit(),提交相关资源至Yarn上
3)NodeManager中的AppMaster根据客户端提交的信息开始计算MapTask的数据
4)MapTask开始执行,创建输入流TextInputFormat读取客户端上的文本数据
5)MapTask读取完成后数据开始进入map()方法
6)再通过outputCollector数据收集器将数据输送到环形缓冲区
7)环形缓冲区会先对数据进行分区,然后排序,环形缓冲区默认100M内存,数据量达到80%后反向
8)在分区、排序的过程中,内存不足时数据会溢写至磁盘,完成分区、排序后将内存中的数据以及溢写产生的数据文件进行归并排序
9)归并排序完成后对文件进行Combin合并(此时数据在各个分区中且分区内有序)
10)MapTask任务结束后,ReduceTask开始将各个MapTask产生的数据文件下载到内存中,若内存不足则下载到磁盘
11)然后将各个MapTask结束后产生的数据文件进行合并,然后进行归并排序、分组
12)完成之后数据进入Reduce()方法
13)最后通过TextOutputFormat将数据输出
2.2.5.2 优化
1)Map阶段
(1)增大环形缓冲区大小,由100M扩大到200M
(2)增大环形缓冲区溢写的比例,有80%扩大到90%
(3)减少对溢写文件的归并排序次数
(4)不影响实际业务的前提下,采用Combine提前合并,减少I/O传输带来的网络资源消耗
2)Reduce阶段
(1)合理设置Map和Reduce数:太少,会导致Task等待,延长处理时间;太多,会导致 Map、Reduce任务间竞争资源,造成处理超时等错误
(2)设置Map、Reduce共存:调整slowstart.completedmaps参数,使Map运行到一定程度后,Reduce也开始运行,减少Reduce的等待时间
(3)能不使用Reduce就不使用:因为Reduce在用于连接数据集的时候将会产生大量的网络消耗
(4)增加每个Reduce去Map中拿数据的并行度
(5)集群性能可以的情况下,增加Reduce端存储数据内存的大小
3)IO传输
(1)Map输入端采用lzo压缩
(2)Map输出端采用snappy或lzo压缩
(3)reduce输出端看具体需求,若作为下一个MR的数据就需要考虑切片,若永久保存考虑压缩率比较大的gzip压缩
4)整体优化
(1)NodeManager默认内存8G,需要根据服务器实际配置灵活调整,例如128G内存,配置为100G左右,yarn.nodemanager.resource.memory-mb
(2)单任务默认内存8G,需要根据该任务的数据量灵活调整,例如128m数据,配置1G内存,yarn-scheduler.maximum-allocation-mb
(3)控制分配给MapTask的内存上限,默认内存大小为1G,若数据量是128m,正常不需要调整内存,若数据量大于128m,可以增加至4~5G
(4)控制分配给ReduceTask的内存上限,默认内存大小为1G,若数据量是128m,正常不需要调整内存,若数据量大于128m,可以增加ReduceTask内存大小为4~5G
(5)控制MapTask堆内存大小
(6)控制ReduceTask堆内存大小
(7)增加MapTask和ReduceTask的CPU核数
(8)增加每个Container的CPU核数和内存大小
(9)在hdfs-site.xml中配置多磁盘
(10)设置NameNode的工作线程池数量,若集群规模为8台,此参数设置为41,该值可以通过python命令计算出来

2.2.6 Yarn工作机制
1)YarnRunner向ResourceManager申请获取一个Application资源提交路径以及一个Application_id
2)ResourceManager向YarnRunner返回Application资源提交路径以及一个Application_id
3)YarnRunner根据从ResourceManager中获取到的Application资源提交路径以及Application_id,将Job运行所需资源提交至HDFS
4)YarnRunner提交完资源后向ResourceManager申请运行MRAppMaster
5)ResourceManager收到请求后将该请求初始化为一个Task任务,并将该Task任务放入Capacity调度队列中
6)ResourceManager向NodeManager派发Task任务,NodeManager获取到Task任务后创建Contrainer容器
7)MRAppMaster运行成功后,开始从HDFS上下载Job运行相关资源至本地
8)MRAppMaster向ResourceManager申请运行MapTask容器(任务存放在Container容器中)
9)ResourceManager接收到请求后选择一个空闲的NodeManager节点,在该节点上创建Container容器以运行MapTask
10)容器创建完成后MRAppMaster向该容器发送程序启动运行脚本,MapTask开始执行
11)当MapTask运行结束后MRAppMaster向ResourceManager申请运行ReduceTask程序
12)ReduceTask程序运行后开始向MapTask获取分区数据
13)ReduceTask运行结束后,MRAppMaster向ResourceManager请求注销自己
2.2.7 Yarn调度器
2.2.7.1 三类Hadoop调度器
1)FIFO(先进先出调度器)
2)Capacity Scheduler(Apache默认容量调度器)
3)Fair Scheduler(CDH默认公平调度器)
2.2.7.2 调度器区别
1)FIFO调度器:支持单队列、先进先出
2)容量调度器:支持多队列、保证先进去的任务优先执行
3)公平调度器:支持多队列、保证每个任务公平享有队列资源
2.2.7.3 在生产环境下如何选择调度器?
大厂一般服务器性能很强并且对并发度要求比较高,所以选择公平调度器
中小公司集群服务器性能资源等不太充裕,所以选择容量调度器
2.2.7.4 在生产环境下如何创建队列?
1)调度器默认就一个default队列,不能满足生产要求
2)按照框架分类,将每个框架的任务放入指定队列(hive、spark、flink)
3)按照业务模块分类,将任务放入指定队列(登录、注册、购物、收藏、下单、支付)
2.2.7.5 创建多队列的好处?
1)担心员工不小心,写递归死循环代码,把所有资源全部耗尽
2)实现任务的降级使用,特殊时期保证重要的任务队列资源充足
2.2.8 项目经验之基准测试
搭建完Hadoop集群后需要对HDFS读写性能和MR计算能力进行测试,测试的Jar包在Hadoop的share文件下
2.2.9 Hadoop宕机
1)若MR造成的系统宕机,此时要控制Yarn同时运行的任务数和每个任务申请的最大内存。调整参数yarn.scheduler.maximum-allocation-mb(单个任务可申请的最多物理内存量,默认8192M)
2)若写入文件过快造成NameNode宕机,此时要调高Kafka的存储大小,控制从Kafka到HDFS的写入速度。调整batchsize参数,控制Flume每批次拉取数据量的大小
2.2.10 Hadoop解决数据倾斜
1)提前在Map阶段将小文件进行combiner合并,减少网络IO传输(若导致数据倾斜的key大量分布在不同的map中时,此方式不是很有效)
2)导致数据倾斜的key大量分布在不同的mapper
(1)局部聚合+全局聚合:先添加随机前缀进行局部聚合,再去掉随机前缀进行全局聚合
(2)增加Reduce数,提升并行度
(3)自定义分区,将key均匀分配至不同的Reduce中
2.2.11 集群资源分配参数(项目中遇到的问题)
集群有30台机器,跑MR任务的时候发现5个map任务全都分配到了同一台机器上,这个可能是由于什么原因导致的吗?
解决方案:yarn.scheduler.fair.assignmultiple 这个参数,默认是关闭的,将该参数设置为true,以控制一个nodemanager里Container的数量
<property> <name>yarn.scheduler.fair.assignmultiple</name> <value>true</value> <discription>是否允许NodeManager一次分配多个容器</discription> </property> <property> <name>yarn.scheduler.fair.max.assign</name> <value>20</value> <discription>如果允许一次分配多个,一次最多可分配多少个,这里按照一个最小分配yarn.scheduler.minimum-allocation-mb4gb来计算总共内存120/4=30给20即可</discription> </property>
三、Zookeeper
3.1 选举机制
半数机制:2n + 1,安装奇数台
1)10台服务器:3台
2)20台服务器:5台
3)100台服务器:11台
3.2 常用命令
1)ls
2)get
3)create
3.3 Paxos算法
Paxos算法一种基于消息传递且具有高度容错特性的一致性算法。
分布式系统中的节点通信存在两种模型:共享内存(Shared memory)和消息传递(Messages passing)。
基于消息传递通信模型的分布式系统,不可避免的会发生以下错误:进程可能会慢、被杀死或者重启,消息可能会延迟、丢失、重复,在基础Paxos场景中,先不考虑可能出现消息篡改即拜占庭错误的情况。Paxos算法解决的问题是在一个可能发生上述异常的分布式系统中如何就某个值达成一致,保证不论发生以上任何异常,都不会破坏决议的一致性。
3.4 CAP法则
1)强一致性
2)高可用性
3)分区容错性
四、Sqoop
4.1 sqoop参数
/opt/module/sqoop/bin/sqoop import \ --connect \ --username \ --password \ --target-dir \ --delete-target-dir \ --num-mappers \ --fields-terminated-by \ --query "$2" ' and $CONDITIONS;'
4.2 sqoop导入导出Null存储一致性问题
Hive中的Null在底层是以“\N”来存储,而MySQL中的Null在底层就是Null。
为了保证数据两端的一致性,在导出数据时采用:
--input-null-string
--input-null-non-string
两个参数,导入数据时采用:
--null-string
--null-non-string
4.3 sqoop数据导出一致性问题
4.3.1 场景
Sqoop在导出数据至Mysql时,使用4个Map任务,在此过程中有2个任务失败,但另外2个任务已经成功将数据导入MySQL,而此时老板正好看到了这个残缺的报表数据。开发工程师发现任务失败后,会调试问题并最终将全部数据正确的导入MySQL,而后面老板再次看报表数据,发现本次看到的数据与之前的不一致,这种情况是生产环境中不允许发生的
4.3.2 解决方案
--staging table:指定暂存表来作为导出数据的辅助表,暂存表中的数据最终在单个事务中移动到目标表
sqoop export --connect jdbc:mysql://192.168.137.10:3306/user_behavior --username root --password 123456 --table app_cource_study_report --columns watch_video_cnt,complete_video_cnt,dt --fields-terminated-by "\t" --export-dir "/user/hive/warehouse/tmp.db/app_cource_study_analysis_${day}" - -staging-table app_cource_study_report_tmp --clear-staging-table --input-null-string '\N'
4.4 sqoop底层运行的任务是什么?
只有MapTask,没有ReduceTask的任务,默认4个有MapTask任务
4.5 sqoop一天导入多少数据?
一天60万日活,产生5多万订单,平均每人5个订单,每天500多M左右的业务数据,所以Sqoop需要将500M左右的数据导入数仓
4.6 sqoop数据导出的时候一次执行多长时间?
凌晨一点开始执行,一般执行时间在半个小时左右,取决于数据量的大小(11:11,6:18等活动执行时间在1个小时左右)
4.7 sqoop导入数据时发生数据倾斜时解决方案
1)split-by:按照某一列来切分表的工作单元
2)num-mappers:启动N个map来并行导入数据,默认4个
4.8 sqoop数据导出Parquet(项目中遇到的问题)
Ads层数据往MySql中导入数据时,若用了orc(Parquet),需转化成text格式
1)创建临时表,把Parquet中表数据导入到临时表,把临时表导出到目标表用于可视化
2)ads层建表的时候就不要建Parquet表
五、Hive
5.1 Hive的架构
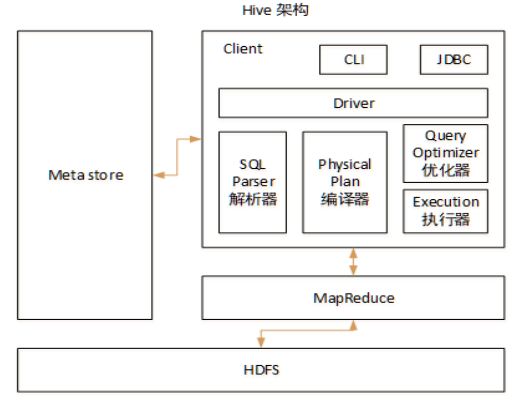
5.2 Hive和数据库的比较
1)数据库存储位置:Hive存储在HDFS中,数据库存储在本地文件系统
2)数据更新:Hive中不建议对数据进行改写
3)执行延迟:Hive执行延迟较高
4)数据规模:Hive能支持大规模的数据计算
5.3 内部表和外部表
5.3.1 两种表在删除数据时的区别
内部表:元数据和原始数据全部删除
外部表:只删除元数据
5.3.2 在生产环境下,什么时候创建内部表,什么时候创建外部表?
绝大部分都是使用外部表,只有临时表才会创建内部表
5.4 四个By的区别
1)Order By:全局排序,只有一个Reduce
2)Sort By:分区内排序
3)Distrbute By:类似MR中的Partition分区,结合Sort By使用,分区完后再对分区中的数据排序
4)Cluster By:当Distrbute By 和 Sort By 字段相同时,可以使用Cluster By,但排序规则只有升序排序
5.5 系统函数
1)date_add:加日期
2)date_sub:减日期
3)date_format:格式化日期
4)last_day:本月最后一天
5)collect_set:列转行,聚合
6)get_json_object:解析Json数据
7)NVL(表达式1,表达式2):第一个表达式的值不为空,则返回第一个表达式的值;第一个表达式的值为空,则返回第二个表达式的值
5.6 自定义UDF、UDTF函数
5.6.1 在项目中是否定义过UDF、UDTF函数,用它们处理了什么问题,定义的步骤是什么?
1)用UDF解析公共字段,用UDTF解析事件字段
2)自定义UDF:继承UDF,重写evaluate方法
3)自定义UDTF:继承GenericUDTF,重写initialize()、process()、close()
5.6.2 为什么要自定义UDF或UDTF?
1)可以自己埋点Log打印日志,出现异常时方便调试
2)可以增加第三方依赖,比如:地图、ip解析、json嵌套
5.6.3 创建函数步骤
1)打包
2)上传至HDFS
3)在hive客户端创建函数
5.7 窗口函数
5.7.1 排序函数
1)rank() 排序相同时会重复,但总数不变
2)dense_rank() 排序相同时会重复,总数会减少
3)row_number() 根据顺序排序
5.7.2 over()
1)current row:当前行
2)n preceding:往前n行数据
3)n following:往后n行数据
4)unbounded:起始点,unbounded preceding 表示起始点,unbounded following表示终点
5)lag(col,n):往前第n行数据
6)lead(col,n):往后第n行数据
7)ntile(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型
5.7.3 手写SQL
5.7.3.1 写出SQL
1)表名:macro_index_data
2)字段名:数据期(年月)(occur_period)、地区代码(area_code)、指标代码(index_code)、指标类型(增速、总量)(index_type)、指标值(index_value)、数据更新时间(update_time)。说明:罗湖区的区划代码为440305000000、GDP指标代码为gmjj_jjzl_01、指标类型的枚举值分别是增速(TB)、总量(JDZ)
3)请写出,2020年4个季度中GDP的增速都超过罗湖区同期的区有哪些
4)SQL如下
--最后比较指标,若都大于即为所求的区 select t2.area_code from ( --先求出罗湖区2020年四季度的GDP指标 select area_code, sum(case when month('occur_period') between 1 and 3 then index_value else 0 end) `one`, --一季度GDP指标 sum(case when month('occur_period') between 4 and 6 then index_value else 0 end) `two`, --二季度GDP指标 sum(case when month('occur_period') between 7 and 9 then index_value else 0 end) `three`, --三季度GDP指标 sum(case when month('occur_period') between 10 and 12 then index_value else 0 end) `four` --四季度GDP指标 from macro_index_data where area_code = '440305000000' --罗湖区 and index_code = 'gmjj_jjzl_01' --GDP指标 and index_type = 'TB' --增速 and year('occur_period') = 2020 --2020年 group by area_code ) t1 join ( --再求出其它区2020年四季度的GDP指标 select area_code, sum(case when month('occur_period') between 1 and 3 then index_value else 0 end) `one`, --一季度GDP指标 sum(case when month('occur_period') between 4 and 6 then index_value else 0 end) `two`, --二季度GDP指标 sum(case when month('occur_period') between 7 and 9 then index_value else 0 end) `three`, --三季度GDP指标 sum(case when month('occur_period') between 10 and 12 then index_value else 0 end) `four` --四季度GDP指标 from macro_index_data where area_code <> '440305000000' --其它区 and index_code = 'gmjj_jjzl_01' --GDP指标 and index_type = 'TB' --增速 and year('occur_period') = 2020 --2020年 group by area_code ) t2 on t2.one > t1.one and t2.two > t1.two and t2.three > t1.three and t2.four > t1.four;
5.7.3.2 写出SQL
1)表1:t_syrkxxb (实有人口信息表),字段名:姓名(xm)、证件号码(zjhm)、证件类型(zjlx)、出生日期(csrq)、居住地址(jzdz)、所在街道(jdmc)、所在社区(sqmc)、联系电话(lxdh)、更新时间(gxsj)
2)表2:t_hsjcqkb (核酸检测情况表),字段名:姓名(xm)、证件号码(zjhm)、证件类型(zjlx)、检测机构(jcjg)、检测时间(jcsj)、报告时间(bgsj)、检测结果(jcjg)
3)说明:实有人口信息表中,因网格统计的时候一人有多处房产或者在多地有居住过的,会有多条数据,仅取最新一条记录;核酸检测情况表中,同一人在同一天内不同检测机构检测多次的算多次检测,同一人在同一天内同一检测机构检测多次的只算最后一次
4)请写出各街道已参与核酸检测总人数、今日新增人数、已检测人数占总人口数的比例;
select t6.jdmc `所在街道`, t8.jiance_person_num `已参与核酸检测总人数`, t7.add_num `今日新增人数`, t6.person_num `已检测人数占总人口数的比例` from ( --各街道总人口数 select jdmc,count(*) `person_num` from t_syrkxxb group by jdmc ) t6 join ( --各街道今日新增人数:以前没有检测过的用户 select t4.jdmc,count(*) `add_num` from ( select zjhm,zjlx,jdmc from t_hsjcqkb where date_format('jcsj','yyyy-MM-dd') = '2021-07-29' ) t4 left join ( --求出检测过的用户 select zjhm,zjlx from t_hsjcqkb group by zjhm,zjlx ) t5 on t4.zjhm = t5.zjhm and t4.zjlx = t5.zjlx where t5.zjhm is null group by jdmc --按照所在街道分组 ) t7 on t6.jdmc = t7.jdmc join ( --求出各街道已参与核酸检测总人数 select t1.jdmc,count(*) `jiance_person_num` from ( --先将实有人口表按更新时间排序后过滤出最新的记录 select t1.* from ( select *,row_number() over(partition by zjhm order by gxsj desc) `rank_gxsj` from t_syrkxxb group by zjhm --以证件号码分组 ) t1 where rank_gxsj = '1' ) t2 join ( --求出检测过的用户 select zjhm,zjlx from t_hsjcqkb group by zjhm,zjlx ) t3 on t2.zjhm = t3.zjhm and t2.zjlx = t3.zjlx group by t1.jdmc --以街道分组 ) t8 t6.jdmc = t8.jdmc;
5)已参与2次以上核酸检测人数、2次以上核酸今日新增数、已检测2次以上人数占总人口数的比例
6)已参与3次以上核酸检测人数、3次以上核酸今日新增数、已检测3次以上人数占总人口数的比例
5.7.3.3 写出SQL语句
1)表名:t_patent_detail (专利明细表)
2)表字段:专利号(patent_id)、专利名称(patent_name)、专利类型(patent_type)、申请时间(aplly_date)、授权时间(authorize_date)、申请人(apply_users)
3)说明:同一个专利,可以有1到多个申请人,多人之间按分号隔开。本表记录数约1万条。例如:
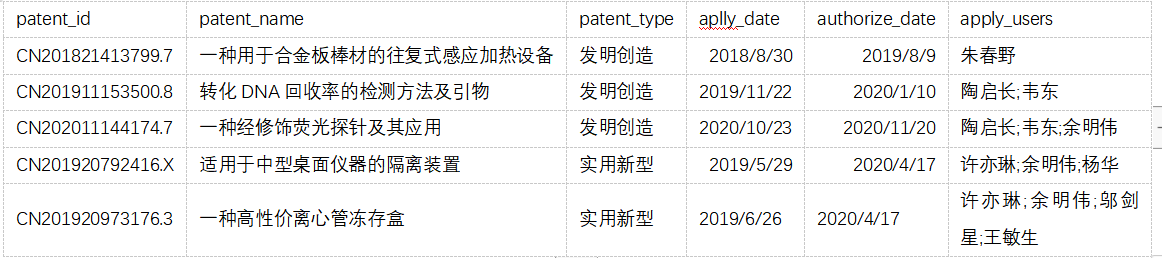
4)请写出hive查询语句,各类型专利top 10申请人,以及对应的专利申请数
--各类型专利top 10申请人,以及对应的专利申请数 select t1.apply_name `申请人`,count(*) `专利申请数`,rank() over(order by count(*) desc) `专利数排名` from ( --先将申请人字段炸裂 select d.*, t1.coll `apply_name` from t_patent_detail d lateral view explode(split(apply_users,';')) t1 as coll ) t1 group by t1.apply_name; --按照申请人分组
5.7.3.4 写出SQL
1)核额流水表hee,字段名:ds(日期分区,20200101,每个分区有全量流水)、sno(每个ds内主键,流水号)、uid(用户id)、is_nsk_apply(是否核额申请,取0或1)、is_pass_rule(是否通过规则,取0或1)、is_obtain_qutoa(是否授信成功,取值0或1)、quota(授信金额)、update_time(更新时间,2020-11-14 08:12:12)
2)借据表jieju,字段名:ds(日期分区,20200101,每个分区有全量借据号)、duebill_idid(借据号,每个日期分区内的主键)、uid(用户id)、prod_type(产品名称,XX贷、YY贷、ZZ贷)、putout_date(发放日期,2020-10-10 00:10:30)、putout_amt(发放金额)、balance(借据余额)、is_buding(状态是否不良,取0或1)、owerduedays(逾期天数)
3)输出模型表moxin,字段名:ds(日期分区,20200101,增量表,部分流水记录有可能更新)、sno(流水号,主键)、create_time(创建日期,2020-10-10 00:30:12)、uid(用户id)、content(Json格式key值名称为V01-V06,value值取值为0和1)、update_time(更新日期,2020-10-10 00:30:12)
4)基于核额流水表和借据表统计如下指标的当日新增、昨日新增、历史累计
(1)申请户数
select t1.count(*) `当日新增用户数` from ( select uid from hee where ds = '20210729' --当日新增 and is_nsk_apply = 1 --已申请核额 group by uid ) t1 select t1.count(*) `昨日新增用户数` from ( select uid from hee where ds = '20210728' --昨日新增 and is_nsk_apply = 1 --已申请核额 group by uid ) t1 select t1.count(*) `历史累计` from ( select uid from hee where ds <= '20210729' --历史累计 and is_nsk_apply = 1 --已申请核额 group by uid ) t1
(2)规则通过户数
select t1.count(*) `当日新增规则通过户数` from ( select uid from hee where ds = '20210729' --当日新增 and is_nsk_apply = 1 --已申请核额 and is_pass_rule = 1 --已通过规则 group by uid ) t1 select t1.count(*) `昨日新增规则通过户数` from ( select uid from hee where ds = '20210728' --昨日新增 and is_nsk_apply = 1 --已申请核额 and is_pass_rule = 1 --已通过规则 group by uid ) t1 select t1.count(*) `历史累计规则通过户数` from ( select uid from hee where ds <= '20210729' --历史累计 and is_nsk_apply = 1 --已申请核额 and is_pass_rule = 1 --已通过规则 group by uid ) t1
(3)核额成功户数
select t1.count(*) `当日新增核额成功户数` from ( select uid from hee where ds = '20210729' --当日新增 and is_nsk_apply = 1 --已申请核额 and is_pass_rule = 1 --已通过规则 and is_obtain_qutoa = 1 --已授信成功 group by uid ) t1 select t1.count(*) `昨日新增核额成功户数` from ( select uid from hee where ds = '20210728' --昨日新增 and is_nsk_apply = 1 --已申请核额 and is_pass_rule = 1 --已通过规则 and is_obtain_qutoa = 1 --已授信成功 group by uid ) t1 select t1.count(*) `历史累计` from ( select uid from hee where ds <= '20210729' --历史累计 and is_nsk_apply = 1 --已申请核额 and is_pass_rule = 1 --已通过规则 and is_obtain_qutoa = 1 --已授信成功 group by uid ) t1
(4)授信金额
select sum(quota)from hee where ds = '20210729' ----当日新增 and is_nsk_apply = 1 --已申请核额 and is_pass_rule = 1 --已通过规则 and is_obtain_qutoa = 1 --已授信成功 select sum(quota)from hee where ds = '20210728' ----当日新增 and is_nsk_apply = 1 --已申请核额 and is_pass_rule = 1 --已通过规则 and is_obtain_qutoa = 1 --已授信成功 select sum(quota)from hee where ds <= '20210729' ----历史累计 and is_nsk_apply = 1 --已申请核额 and is_pass_rule = 1 --已通过规则 and is_obtain_qutoa = 1 --已授信成功
(5)平均核额
select avg(quota)from hee where ds = '20210729' --当日新增 and is_nsk_apply = 1 --已申请核额 and is_pass_rule = 1 --已通过规则 and is_obtain_qutoa = 1 --已授信成功 select avg(quota)from hee where ds = '20210728' --昨日新增 and is_nsk_apply = 1 --已申请核额 and is_pass_rule = 1 --已通过规则 and is_obtain_qutoa = 1 --已授信成功 select avg(quota)from hee where ds < '20210729' --历史累计 and is_nsk_apply = 1 --已申请核额 and is_pass_rule = 1 --已通过规则 and is_obtain_qutoa = 1 --已授信成功
(6)发放金额
select sum(putout_amt)from jieju where ds = '20210729' --当日新增 select sum(putout_amt)from jieju where ds = '20210728' --昨日新增 select sum(putout_amt)from jieju where ds <= '20210728' --历史累计
(7)户均发放金额
select avg(putout_amt) `当日户均发放金额` from jieju where ds = '20210729' select avg(putout_amt) `昨日户均发放金额` from jieju where ds = '20210728' select avg(putout_amt) `历史累计户均发放金额` from jieju where ds <= '20210729'
5)基于借据表,统计SQL
(1)XX贷(在贷客户数、在贷余额、不良余额、余额不良率、不良客户数、客户不良率)
select count(*) `在贷客户数` from ( select uid from jieju where ds = '20210729' and prod_type = 'XX贷' group by uid ) t1 select sum(balance) `在贷余额` from jieju where ds = '20210729' and prod_type = 'XX贷' select sum(balance) `不良余额` from jieju where ds = '20210729' and prod_type = 'XX贷' and is_buding = 1 余额不良率=不良余额/在贷余额 select count(*) `不良客户数` from ( select uid from jieju where ds = '20210729' and prod_type = 'XX贷' and is_buding = 1 group by uid ) t1 客户不良率=不良客户数/在贷客户数
(2)YY贷(在贷客户数、在贷余额、不良余额、余额不良率、不良客户数、客户不良率)
select count(*) `在贷客户数` from ( select uid from jieju where ds = '20210729' and prod_type = 'YY贷' group by uid ) t1 select sum(balance) over(partition by ds) `在贷余额` from jieju where ds = '20210729' and prod_type = 'YY贷' select sum(balance) over(partition by ds) `不良余额` from jieju where ds = '20210729' and prod_type = 'YY贷' and is_buding = 1 余额不良率=不良余额/在贷余额 select count(*) `不良客户数` from ( select uid from jieju where ds = '20210729' and prod_type = 'YY贷' and is_buding = 1 group by uid ) t1 客户不良率=不良客户数/在贷客户数
(3)ZZ贷(在贷客户数、在贷余额、不良余额、余额不良率、不良客户数、客户不良率)
select count(*) `在贷客户数` from ( select uid from jieju where ds = '20210729' and prod_type = 'ZZ贷' group by uid ) t1 select sum(balance) over(partition by ds) `在贷余额` from jieju where ds = '20210729' and prod_type = 'ZZ贷' select sum(balance) over(partition by ds) `不良余额` from jieju where ds = '20210729' and prod_type = 'ZZ贷' and is_buding = 1 余额不良率=不良余额/在贷余额 select count(*) `不良客户数` from ( select uid from jieju where ds = '20210729' and prod_type = 'ZZ贷' and is_buding = 1 group by uid ) t1 客户不良率=不良客户数/在贷客户数
6)基于借据表,统计SQL
(1)逾期1~30天(户数、余额、逾期率)
select count(distinct uid) `户数`,sum(balance) `余额`,round((sum(10to30) / count(*)),2) `逾期率` from ( select uid, balance, case when owerduedays between 1 and 30 then 1 else 0 `10to30` from jieju ) t1
(2)逾期30~90天(户数、余额、逾期率)
select count(distinct uid) `户数`,sum(balance) `余额`,round((sum(30to90) / count(*)),2) `逾期率` from ( select uid, balance, case when owerduedays between 30 and 90 then 1 else 0 `30to90` from jieju ) t1
(3)逾期90天以上(户数、余额、逾期率)
select count(distinct uid) `户数`,sum(balance) `余额`,round((sum(90day) / count(*)),2) `逾期率` from ( select uid, balance, case when owerduedays > 90 then 1 else 0 `90day` from jieju ) t1
(4)逾期合计(户数、余额、逾期率)
select count(distinct uid) `户数`,sum(balance) `余额`,round((sum(1day) / count(*)),2) `逾期率` from ( select uid, balance, case when owerduedays > 1 then 1 else 0 `1day` from jieju ) t1
(5)不良合计(户数、余额、逾期率)
select count(distinct uid) `户数`,sum(balance) `余额`,round((sum(1day) / count(*)),2) `逾期率` from ( select uid, balance, case when owerduedays > 1 then 1 else 0 `1day` from jieju where is_buding = 1 ) t1
7)基于模型输出表,统计SQL(value值为1即为命中)
(1)统计日期20201010,统计指标V01(命中户数、命中率)
select count(*) `user_num`,sum(mingzhon) `mingzhon_num`,round(mingzhon_num / user_num,2) `命中率` from ( select uid,(case when get_json_object('content','$.V01') == 1 then 1 else 0 end) `mingzhon` from moxin where ds = '20201010' ) t1
(2)统计日期20201010,统计指标V02(命中户数、命中率)
select count(*) `user_num`,sum(mingzhon) `mingzhon_num`,round(mingzhon_num / user_num,2) `命中率` from ( select uid,(case when get_json_object('content','$.V02') == 1 then 1 else 0 end) `mingzhon` from moxin where ds = '20201010' ) t1
(3)类推即可。。。
8)基于借据表统计指标,请提供Vintage统计SQL(mobX指的是发放后第X月末的不良余额/发放月金额)
(1)发放月份2019-10(发放金额、MOB1、MOB2、MOB3、MOB4、MOB5、MOB6、MOB7、MOB8、MOB9、MOB10、MOB11、MOB12)
--MOB1,一个月后再来查询 select sum(bad_monery) `不良余额`,sum(putout_amt) `发放月金额` from ( select (case when is_buding = 1 then balance else 0 end) `bad_monery`,putout_amt from jieju where date_format('ds','yyyy-MM') = '2019-10' --数据都按天存放,过滤出当月的即可 and date_format('putout_date','yyyy-MM') = '2019-10' ) t1 --MOB2,两个月后再来查询 select sum(bad_monery) `不良余额`,sum(putout_amt) `发放月金额` from ( select (case when is_buding = 1 then balance else 0 end) `bad_monery`,putout_amt from jieju where date_format('ds','yyyy-MM') = '2019-10' --数据都按天存放,过滤出当月的即可 and date_format('putout_date','yyyy-MM') = '2019-10' ) t1
(2)发放月份2019-11(发放金额、MOB1、MOB2、MOB3、MOB4、MOB5、MOB6、MOB7、MOB8、MOB9、MOB10、MOB11、MOB12)
--MOB1,一个月后再来查询 select sum(bad_monery) `不良余额`,sum(putout_amt) `发放月金额` from ( select (case when is_buding = 1 then balance else 0 end) `bad_monery`,putout_amt from jieju where date_format('ds','yyyy-MM') = '2019-11' --数据都按天存放,过滤出当月的即可 and date_format('putout_date','yyyy-MM') = '2019-11' ) t1 --MOB2,两个月后再来查询 select sum(bad_monery) `不良余额`,sum(putout_amt) `发放月金额` from ( select (case when is_buding = 1 then balance else 0 end) `bad_monery`,putout_amt from jieju where date_format('ds','yyyy-MM') = '2019-11' --数据都按天存放,过滤出当月的即可 and date_format('putout_date','yyyy-MM') = '2019-11' ) t1
5.7.3.5 请把下面的HQL语句改为其他方式实现
1)请优化:
select a.key,a.value from a where a.key not in (select b.key from b)
2)已优化:
select t1.key,t1.value from ( select a.key,a.value from a ) t1 right join ( select b.key from b ) t2 on t1.key = t2 .key where t1.key is null;
3)请优化:
select a.key,a.value from a where a.key in (select b.key from b)
4)已优化:
select t1.key,t1.value from ( select a.key,a.value from a ) t1 join ( select b.key from b ) t2 on t1.key = t2 .key;
5.7.3.6 写出SQL
1)student表,student(id,num,name,class),字段说明:num(学号)、name(学生姓名)、class(班级)
2)course_score表,course_score(student_num,course,score),字段说明:student_num(学号)、courese(科目)、score(分数)
3)查询班级为"2020"的所有学生科目"PE"的平均分
select avg(score) `班级为2020的所有学生科目"PE"的平均分` from ( select * from student where class = '2020' ) t1 join ( select student_num,score from course_score where courese = 'PE' ) t2 on t1.num = t2.student_num
4)查询所有科目大于80分的学生的姓名
select num,name from student s join ( select student_num from course_score group by student_num having score > 80 ) t1 on s.num = t1.student_num;
select s.num,s.name from student s left join ( select student_num from course_score where score <= 80 group by student_num ) t1 on s.num = t1.student_num where t1.student_num is null;
5)60分以上合格,查出所有学生合格与不合格科目的总数,格式为(student_num,passed,failed)
select student_num, sum(case when score >= 60 then 1 else 0 end) `passed`, sum(case when score < 60 then 1 else 0 end) `failed` from course_score group by student_num
5.7.3.7 写出SQL
1)一张理财项目的表大致如下:begin_date代表买入一笔的时间,end_date代表将其卖出的时间,求用户历史最大的持仓笔数

2)请写出SQL
select user_id, max(num) max_num from ( select id, user_id, dt, sum(p) over(partition by user_id order by dt) num from ( select id, user_id, begin_date dt, 1 p from test union select id, user_id, end_date dt, -1 p from test ) t1 ) t2 group by user_id;
5.7.3.8 写出SQL
1)订单表A(user int,order_id int,time datetime),查询每个用户按订单时间排序标号
2)请写出SQL
select user, order_id, time, row_number() over(partition by user order by time asc) `order_id` from A
5.7.3.9 写出SQL
1)一张用户交易表order,其中有userid(用户ID)、amount(消费金额)、paytime(支付时间),查出每个用户第一单的消费金额
2)如下:
select userid,amount from ( select userid,amount,paytime,row_number() over(partition by userid order by paytime asc) `rank` from order ) t1 where t1.rank = 1;
5.7.3.10 写出SQL
1)用户行为表tracking_log,字段有userid(用户ID),evt(用户行为),evt_time(用户操作时间)
2)计算每天的访客数和他们的平均操作次数
select count(distinct userid) `user_num`, round(count(evt) / user_num,2) `平均操作次数` from tracking_log where date_format('evt_time','yyyy-MM-dd') = '2021-07-30'
3)统计每天符合以下条件的用户数:A操作之后是B操作,AB操作必须相邻(两种写法:lag() 函数或 lead() 函数)
select count(userid) `A操作之后是B操作,AB操作必须相邻的用户数` from ( select userid,sum(case when (evt = 'B' && evtOne = 'A') then 1 else 0 end) `evt_sum` from ( select userid, evt, --用户行为 lag(evt,1) over(partition by userid order by evt_time) `evtOne` --往前一行的用户行为 from tracking_log where date_format('evt_time','yyyy-MM-dd') = '2021-07-30' ) t1 group by userid ) t2 where t2.evt_sum >=1;
select count(userid) `A操作之后是B操作,AB操作必须相邻的用户数` from ( select userid,sum(case when (evt = 'A' && evtOne = 'B') then 1 else 0 end) `evt_sum` from ( select userid, evt, --用户行为 lead(evt,1) over(partition by userid order by evt_time) `evtOne` --往后一行的用户行为 from tracking_log where date_format('evt_time','yyyy-MM-dd') = '2021-07-30' ) t1 group by userid ) t2 where t2.evt_sum >=1;
5.7.3.11 有一个表A:班级,姓名,性别,身高,求每个班级身高最高的数据(两种写法)
select A.* from A join ( select class,max(height) `max_height` from A group by class ) t1 on A.class = t1.class and A.height = t1.height;
select class, name, sex, height from ( select class, name, sex, height, rank() over(partition by class order by height desc) `rank` from A ) t1 where t1.rank = 1;
5.7.3.12 写出SQL
1)user表,用户访问数据:
userId visitDate visitCount u01 2017/1/21 5 u02 2017/1/23 6 u03 2017/1/22 8 u04 2017/1/20 3 u01 2017/1/23 6 u01 2017/2/21 8 U02 2017/1/23 6 U01 2017/2/22 4
2)使用SQL统计出每个用户的累积访问次数
select userId, mn mn_count `当前月访问次数`, sum(mn_count) over(partition by userId order by mn) `累计访问次数` from ( --统计每个用户每个月的访问次数 select userId, mn, sum(visitCount) `mn_count` from ( --先将访问时间格式化 select userId, date_format(regexp_replace(visitDate,'/','-'),'yyyy-MM') mn, visitCount from user ) t1 group by userId,mn ) t2;
3)Scores表,数据如下:
+----+-------+ | Id | Score | +----+-------+ | 1 | 3.50 | | 2 | 3.65 | | 3 | 4.00 | | 4 | 3.85 | | 5 | 4.00 | | 6 | 3.65 | +----+-------+
4)按照分数从高到低排序
select id,score,rank() over(order by score desc) `排名` from scores
5.7.3.13 写出SQL(此题我也不太会,答案仅供参考,非权威)
1)停车表user_parking_record,字段 user_id(string),date(yyyy-MM-dd),start_time(hh:mm:ss),end_time(hh:mm:ss),community_id(string)
2)分时统计各小区用户停车数
select community_id, date, hour(dt) hour_dt max(sum_p) max_cat from ( select user_id, date, dt, community_id, sum(p) over(partition by community_id order by dt) sum_p from ( select user_id, date, concat(date,start_time) dt, community_id, 1 p from user_parking_record union select user_id, date, concat(date,end_time) dt, community_id, -1 p from user_parking_record ) t1 ) t2 group by community_id,date,hour_dt
3)统计各小区用户停车高峰时段Top3
4)各用户近两周内最大连续停车天数
5)若非连续停车天数不超过1天,也可做连续停车,求各小区最大连续停车天数的用户数分布情况
5.7.3.14 写出SQL
1)score表结构:uid,subject_id,score
2)找出所有科目成绩都大于某一学科平均成绩的学生
select uid from ( select uid, if(score>avg_score,0,1) flag from ( --先求出各个学科的平均成绩 select uid, score, avg(score) over(partition by subject_id) avg_score from score )t1 )t2 group by uid having sum(flag)=0;
5.7.3.15 写出HQL
1)访问日志存储的表名为Visit,访客的用户id为user_id,被访问的店铺名称为shop
2)求每个店铺的UV(访客数)
select shop,count(distinct user_id) `访客数` from Visit group by shop
3)求每个店铺访问次数top3的访客信息,输出店铺名称、访客id、访问次数
select t2.shop, t2.user_id, t2.user_count from ( select shop, user_id, user_count, rank() over(partition by shop order by user_count) `rank` from ( select shop,user_id,count(user_id) `user_count` from Visit group by shop,user_id ) t1 ) t2 where t2.rank <= 3;
5.7.3.16 写出HQL
1)ORDER表,字段:Date,Order_id,User_id,amount(数据样例:2017-01-01,10029028,1000003251,33.57)
2)给出 2017年每个月的订单数、用户数、总成交金额
select month('date'),count(order_id) `订单数`,count(distinct user_id) `用户数`,sum(amount) `总成交金额` from order where year('date') = '2017' group by month('date')
3)给出2017年11月的新客数(指在11月才有第一笔订单)
select count(distinct user_id) `新客数` from ( select * from order where date_format('date','yyyy-MM') = '2017-11' ) t1 left join ( select * from order where date_format('date','yyyy-MM') < '2017-11' ) t2 on t1.user_id = t2.user_id where t2.user_id is null;
5.7.3.17 写出HQL
1)表user_age,数据集:
日期 用户 年龄 2019-02-11,test_1,23 2019-02-11,test_2,19 2019-02-11,test_3,39 2019-02-11,test_1,23 2019-02-11,test_3,39 2019-02-11,test_1,23 2019-02-12,test_2,19 2019-02-13,test_1,23 2019-02-15,test_2,19 2019-02-16,test_2,19
2)求所有用户和活跃用户的总数及平均年龄(活跃用户指连续两天都有访问记录的用户)
select sum(user_total_count), sum(user_total_avg_age), sum(twice_count), sum(twice_count_avg_age) from ( select 0 `user_total_count`, 0 `user_total_avg_age`, count(*) `ct`, cast(sum(age)/count(*) as decimal(10,2)) `twice_count_avg_age` from ( select user_id, min(age) `age` from ( select user_id, min(age) `age` from ( select user_id, age, date_sub(dt,rank) `flag` from ( select dt, user_id, min(age) `age`, rank() over(partition by user_id order by dt) `rank` from user_age group by dt,user_id ) t1 ) t2 group by user_id,flag having count(*) >= 2 ) t3 group by user_id ) t4 union all select count(*) `user_count`, cast((sum(age)/count(*)) as decimal(10,1)), 0 `twice_count`, 0 `twice_count_avg_age` from ( select user_id, min(age) `age` from user_age group by user_id ) t5 ) t6;
5.7.3.18 写出HQL
1)表ordertable,字段(购买用户:userid,金额:money,购买时间:paymenttime(格式:2017-10-01),订单id:orderid)
2)求所有用户中在今年10月份第一次购买商品的金额
select userid, money, paymenttime, orderid from ( select userid, money, paymenttime, orderid, row_number() over(partition by userid order by paymenttime desc) `rank` from ordertable where date_format('paymenttime','yyyy-MM') = '2017-10' ) t1 where t1.rank = 1
5.7.3.19 写出HQL
1)数据:
时间 接口 ip地址 2016-11-09 11:22:05 /api/user/login 110.23.5.33 2016-11-09 11:23:10 /api/user/detail 57.3.2.16 ..... 2016-11-09 23:59:40 /api/user/login 200.6.5.166
2)求11月9号下午14点(14-15点),访问api/user/login接口的top10的ip地址
select address_id,count(*) `ip_count` frrom address where date_format('date','MM-dd HH') = '11-09 14' and url = 'api/user/login' group by address_id order by ip_count desc limit 10
5.7.3.20 写出HQL
1)表信息
CREATE TABLE `account` ( `dist_id` int(11)DEFAULT NULL COMMENT '区组id', `account` varchar(100)DEFAULT NULL COMMENT '账号', `gold` int(11)DEFAULT 0 COMMENT '金币');
2)查询各自区组的money排名前十的账号(分组取前10)
select dist_id, account, gold, rank from ( select dist_id, account, gold, row_number() over(partition by dist_id order by gold desc) `rank` from account ) t1 where t1.rank <= 10
5.7.3.21 写出HQL
1)会员表(member),字段:memberid(会员id,主键)credits(积分)
2)销售表(sale),字段:memberid(会员id,外键)购买金额(MNAccount)
3)退货表(regoods),字段memberid(会员id,外键)退货金额(RMNAccount)
4)业务说明
(1)销售表中的销售记录可以是会员购买,也可以是非会员购买。(即销售表中的memberid可以为空)
(2)销售表中的一个会员可以有多条购买记录
(3)退货表中的退货记录可以是会员,也可是非会员
(4)一个会员可以有一条或多条退货记录
5)分组查出销售表中所有会员购买金额,同时分组查出退货表中所有会员的退货金额,把会员id相同的购买金额-退款金额得到的结果更新到表会员表中对应会员的积分字段(credits)
insert into table member ( select t1.memberid, (mnaccount - rmnaccount) `credits` from ( select memberid, sum(mnaccount) `mnaccount` from sale where memberid is not null group by memberid ) t1 join ( select memberid, sum(rmnaccount) `rmnaccount` from regoods where memberid is not null group by memberid ) t2 on t1.memberid = t2.memberid );
5.7.3.22 写出HQL
1)student表信息如下:
自动编号 学号 姓名 课程编号 课程名称 分数 1 2005001 张三 0001 数学 69 2 2005002 李四 0001 数学 89 3 2005001 张三 0001 数学 69
2)删除除了自动编号不同, 其他都相同的学生冗余信息
delete from student where 自动编号 not in ( select min(自动编号) from student group by 学号,姓名,课程编号,课程名称,分数 )
5.7.3.23 一个叫team的表,里面只有一个字段name,一共有4条纪录,分别是a,b,c,d,对应四个球队,现在四个球队进行比赛,用一条sql语句显示所有可能的比赛组合
select a.name, b.name from team a, team b where a.name < b.name
5.7.3.24 写出HQL
1)怎么把这样一个
year month amount 1991 1 1.1 1991 2 1.2 1991 3 1.3 1991 4 1.4 1992 1 2.1 1992 2 2.2 1992 3 2.3 1992 4 2.4
查成这样一个结果 year m1 m2 m3 m4 1991 1.1 1.2 1.3 1.4 1992 2.1 2.2 2.3 2.4
2)如下:
select year, (select amount from aa m where m.month = 1 and m.year = aa.year) `m1`, (select amount from aa m where m.month = 2 and m.year = aa.year) `m2`, (select amount from aa m where m.month = 3 and m.year = aa.year) `m3`, (select amount from aa m where m.month = 4 and m.year = aa.year) `m4`, from aa group by year
5.7.3.25 复制表(只复制结构,源表名:a,新表名:b)
select * into b from a where 1<>1 --where 1=1 表示拷贝表结构和数据内容
5.7.3.26 写出HQL
1)原表:
courseid coursename score
1 java 70
2 oracle 90
3 xml 40
4 jsp 30
5 servlet 80
2)想要的结果:
courseid coursename score mark 1 java 70 pass 2 oracle 90 pass 3 xml 40 fail 4 jsp 30 fail 5 servlet 80 pass
3)写出答案:
select courseid, coursename, score, (case when score >= 60 then "pass" else "fail" end) `mark` from score
select courseid, coursename, score, if(score >= 60,"pass","fail") `mark` from score
5.7.3.27 写出HQL
1)表名:购物信息
购物人 商品名称 数量 A 甲 2 B 乙 4 C 丙 1 A 丁 2 B 丙 5
2)求所有购入商品为两种或两种以上的购物人记录
select * from shoop s join ( select user from shoop group by user having count(*) > 2 ) t1 on s.suer = t1.user;
5.7.3.28 写出HQL
1)info 表
date result 2005-05-09 win 2005-05-09 lose 2005-05-09 lose 2005-05-09 lose 2005-05-10 win 2005-05-10 lose 2005-05-10 lose
2)如果要生成下列结果, 该如何写sql语句?
date win lose 2005-05-09 2 2 2005-05-10 1 2
3)答案
select date, sum(case when result = "win" then 1 else 0 end) `win` sum(case when result = "lose" then 1 else 0 end) `lose` from info group by date
5.7.3.29 订单表order,字段有:order_id(订单ID), user_id(用户ID),amount(金额), pay_datetime(付费时间),channel_id(渠道ID),dt(分区字段)
1)在Hive中创建这个表
create external table order( order_id int, user_id int, amount double, pay_datetime timestamp, channel_id int ) partitioned by (dt string) row format delimited fields terminated by '\t';
2)查询dt=‘2021-08-04‘里每个渠道的订单数,下单人数(去重),总金额
select channel_id, count(order_id) `订单数`, count(distinct user_id) `下单人数`, sum(amount) `总金额` from order where dt = '2021-08-04' group by channel_id
3)查询dt=‘2021-08-04‘里每个渠道的金额最大3笔订单
select channel_id, order_id, amount, rank from ( select channel_id, order_id, amount, rank() over(partition by channel_id order by amount desc) `rank` from order where dt = '2021-08-04' group by channel_id,order_id,amount ) t1 where t1.rank <= 3
4)有一天发现订单数据重复,请分析原因
订单属于业务数据,在关系型数据库中不会存在数据重复,hive建表时也不会导致数据重复,所以我推测是在数据迁移时,失败导致重复迁移,从而出现数据冗余的情况
5.7.3.30 写出SQL
1)t_order订单表
order_id,//订单id item_id, //商品id create_time,//下单时间 amount//下单金额
2)t_item商品表
item_id,//商品id item_name,//商品名称 category//品类
3)t_item商品表
item_id,//商品id item_name,//名称 category_1,//一级品类 category_2,//二级品类
4)最近一个月,销售数量最多的10个商品
select item_id, item_num, rank() over(partition by item_id order by item_num desc) `rank` from ( select item_id,count(*) `item_num` from t_order where date_sub('2021-08-06',30) <= 'create_time' group by item_id ) t1 where rank <= 10;
5)最近一个月,每个种类里销售数量最多的10个商品(一个订单对应一个商品 一个商品对应一个品类)
select category, item_id, item_sum, rank from ( select category, item_id, sum(item_num) `item_sum`, rank() over(partition by category order by item_num desc) `rank` from ( select t1.item_id, t1.item_num, t2.category from ( select item_id, count(*) `item_num` from t_order where date_sub('2021-08-06',30) <= 'create_time' group by item_id ) t1 join ( select item_id, item_name, category from t_item ) t2 on t1.item_id = t2.item_id ) t3 group by category,item_id ) t4 where rank <= 10;
5.7.3.31 计算平台的每一个用户发过多少日记、获得多少点赞数
5.7.3.32 处理产品版本号
1)需求A:找出T1表中最大的版本号
select v1,max(v2) from ( select t1.v_id `v1`, --版本号 tmp.v_id `v2` --主 from t1 lateral view explode(v2) tmp as v2 )
2)思路:列转行,切割版本号,一列变三列(主版本号 子版本号 阶段版本号)
select v_id, --版本号 max(split(v_id,".")[0]) v1, --主版本不会为空 max(if(split(v_id,".")[1]="",0,split(v_id,".")[1]))v2, --取出子版本并判断是否为空,并给默认值 max(if(split(v_id,".")[2]="",0,split(v_id,".")[2]))v3 --取出阶段版本并判断是否为空,并给默认值 from t1
3)需求B:计算出如下格式的所有版本号排序,要求对于相同的版本号,顺序号并列
select v_id, rank() over(partition by v_id order by v_id) `seq` from t1
5.8 Hive优化
5.8.1 MapJoin
在Reduce阶段完成Join,容易发生数据倾斜,可以在MapJoin阶段将小表全部加载到内存中进行Join
5.8.2 行列过滤
列处理:在select查询时,只拿需要的列,如果有,尽量使用分区过滤,少用select *
行处理:在分区裁剪中,当使用外关联时,若将副表的过滤条件写在where后面,则会先进行全表关联,之后再过滤
5.8.3 列式存储技术
5.8.4 分区技术
5.8.5 合理设置Map数
1)mapred.min.split.size:数据的最小切割单元,默认值是1B
2)mapred.min.split.size:数据的最大切割单元,默认256MB
3)通过调整max可以起到调整map数的作用,减少max可以增加map数,增加max可以减少map数
5.8.6合理设置Reduce数
1)过多的启动和初始化Reduce会消耗时间和资源
2)有多少个Reduce就会有多少个输出文件,若生产了很多个小文件,则若这些小文件作为下一个任务的输入,也会出现小文件过多的问题
3)两个原则
(1)处理大数据量利用合适的Reduce数
(2)单个Reduce任务处理数据量大小要合适
5.8.7 小文件如何产生?
1)动态分区插入数据,产生大量小文件,导致map数剧增
2)reduce数越多,小文件就越多
3)数据源本身就包含大量小文件
5.8.8 小文件解决?
1)使用CombineHiveInputFormat合并小文件
2)merge
SET hive.merge.mapfiles = true; -- 默认true,在map-only任务结束时合并小文件 SET hive.merge.mapredfiles = true; -- 默认false,在map-reduce任务结束时合并小文件 SET hive.merge.size.per.task = 268435456; -- 默认256M SET hive.merge.smallfiles.avgsize = 16777216; -- 当输出文件的平均大小小于16m该值时,启动一个独立的map-reduce任务进行文件merge
3)JVM重用
set mapreduce.job.jvm.numtasks=10
5.8.9 不影响最终的业务逻辑情况下,开启map端的combiner聚合
set hive.map.aggr=true;
5.8.10 文件压缩
set hive.exec.compress.intermediate=true --启用中间数据压缩 set mapreduce.map.output.compress=true --启用最终数据压缩 set mapreduce.map.outout.compress.codec=…; --设置压缩方式
5.8.11 采用tez引擎或Spark引擎
5.9 解决数据倾斜的方法
5.9.1 数据倾斜长啥样?
5.9.2 数据倾斜如何产生?
1)不同数据类型关联产生数据倾斜
(1)比如用户表中user_id字段为string,log表中user_id字段int类型。当按照user_id进行两个表的Join操作时,就会发生数据倾斜
(2)解决方法:把数字类型转为字符串类型
select * from users a left outer join logs b on a.usr_id = cast(b.user_id as string)
2)生产环境中会使用大量空值数据,这些数据进入到一个reduce中,导致数据倾斜
解决方法:自定义分区,将为空的key转变为字符串加随机数或纯随机数,将因空值而造成倾斜的数据分布到多个Reducer。对于异常值如果不需要的话,最好是提前在where条件里过滤掉,这样可以使计算量大大减少
5.9.3 解决数据倾斜的方法
1)采用sum() group by的方式来替换count(distinct)完成计算,group by 优于distinct group
2)在map阶段进行Join
3)开启数据倾斜时负载均衡
(1)先随机分发处理,再按照key值进行group by
(2)当选项设定为true,生成的查询计划会有两个MRJob。第一个MRJob中,Map的输出结果集合会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的GroupBy Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MRJob再根据预处理的数据结果按照GroupBy Key分布到Reduce中(这个过程可以保证相同的原始GroupBy Key被分布到同一个Reduce中),最后完成最终的聚合操作
(3)它使计算变成了两个mapreduce,先在第一个中在shuffle过程partition时随机给 key打标记,使每个key随机均匀分布到各个reduce上计算,但是这样只能完成部分计算,因为相同key没有分配到相同reduce上。所以需要第二次的mapreduce,这次就回归正常shuffle,但是数据分布不均匀的问题在第一次mapreduce已经有了很大的改善,因此基本解决数据倾斜。因为大量计算已经在第一次mr中随机分布到各个节点完成
4)设置多个reduce个数
reduce个数的设定极大影响任务执行效率,不指定reduce个数的情况下,Hive会猜测确定一个reduce个数,基于以下两个参数:
hive.exec.reducers.bytes.per.reducer(每个reduce任务处理的数据量,默认为1000^3=1G)
hive.exec.reducers.max(每个任务最大的reduce数,默认为999)
计算reducer数的公式很简单:N=min(参数2,总输入数据量/参数1) ,即如果reduce的输入(map的输出)总大小不超过1G,那么只会有一个reduce任务
5.10 Hive里字段的分隔符用的是什么?为什么用\t?有遇到字段里边有\t的情况吗,怎么处理的?
hive 默认的字段分隔符为ascii码的控制符\001(^A),建表的时候用fields terminated by '\001'。注意:如果采用\t或者\001等为分隔符,需要要求前端埋点和javaEE后台传递过来的数据必须不能出现该分隔符,通过代码规范约束。一旦传输过来的数据含有分隔符,需要在前一级数据中转义或者替换(ETL)
hive-drop-import-delims:导入到hive时删除 \n, \r, \001
hive-delims-replacement:导入到hive时用自定义的字符替换掉 \n, \r, \001
5.11 Tez引擎的优点
5.11.1 MR引擎
多job串联,基于磁盘,落盘的地方比较多。虽然慢,但一定能跑出结果。一般处理,周、月、年指标
5.11.2 Spark引擎
虽然在Shuffle过程中也落盘,但是并不是所有算子都需要Shuffle,尤其是多算子过程,中间过程不落盘 DAG有向无环图。 兼顾了可靠性和效率。一般处理天指标
5.11.3 Tez引擎
完全基于内存,如果数据量特别大,慎重使用。容易OOM。一般用于快速出结果,数据量比较小的场景
5.12 MySQL元数据备份
1)如数据损坏,可能整个集群无法运行,至少要保证每日零点之后备份到其它服务器两个复本,使用Keepalived或者mycat
2)MySQL utf8超过字节数问题
MySQL的utf8编码最多存储3个字节,当数据中存在表情号、特色符号时会占用超过3个字节数的字节,那么会出现错误 Incorrect string value: '\xF0\x9F\x91\x91\xE5\xB0...'
(1)解决办法:将utf8修改为utf8mb4
(2)首先修改库的基字符集和数据库排序规则为utf8mb4_unicode_ci
(3)再使用 SHOW VARIABLES LIKE '%char%'; 命令查看参数
5.13 Union和Union All 的区别
1)union会将联合的结果集去重,效率较union all差
2)union all不会对结果集去重,效率高