@article{he2016deep,
title={Deep Residual Learning for Image Recognition},
author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian},
pages={770--778},
year={2016}}
主要内容
深度一直是CNN很重要的一个点, 作者发现, 当仅仅增加层数不一定会带来优势, 甚至会误差会加大, 而且这个误差并非是过拟合导致的.
设输入为(x), 一般的网络的输出可以表示为(mathcal{H}(x)), 作者考虑的是
[ ag{1}
mathcal{F}(x):=mathcal{H}(x)-x.
]
实际上看到这里是有困惑的, 为什么(mathcal{H}(x)-x)是成立的? 这不就意味着网络的输出和输入是同样大小的? 那还怎么分类.
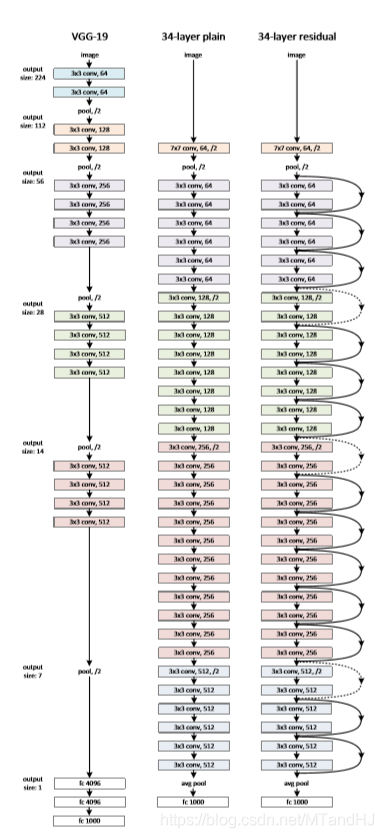
从上面的图中可以看到, 其实(mathcal{H}(x))并非是整个网络的输出, 而是某些层的输出,图中每俩个层就会进行一次残差的操作. 所以用网络去学习(mathcal{F}(x)), 能够把前者的信息更好的传递下去. 就像作者说的, 如果前面部分的层能够很好的完成任务, 后面的层只需要称为恒等映射就行了. 但是恒等映射不一定能够被很好的逼近, 这将导致网络加深反而误差变大, 但是如果改成学习残差就很容易了, 因为后面的层只需要将权重设置为0,那么后面每一块的输出都会是(x)(为某一层的输出), 这至少能够保证深度加深结果不会变坏.
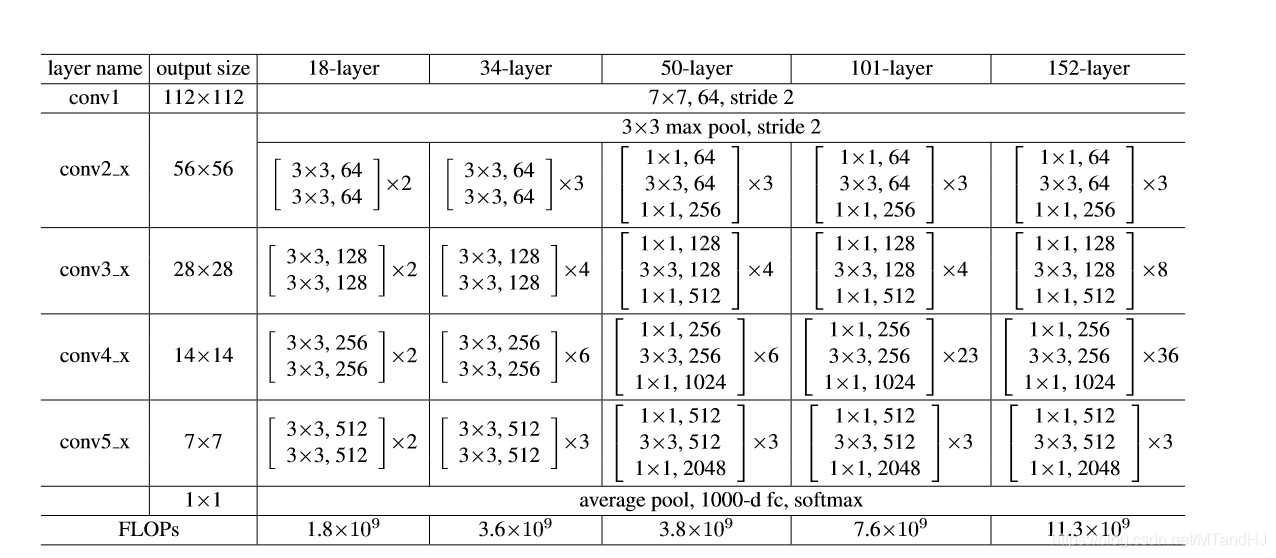
当然还有最后一个问题, (x)的大小终究是要变化的, 所以我们没法保证(mathcal{F}(x))和(x)的尺寸是一致的, 一种解决办法是增加一个线性映射
[ ag{2}
mathcal{F}(x)+W_s x,
]
代码里用的便是1x1的卷积核, 或者也可以通过补零来实现.
代码
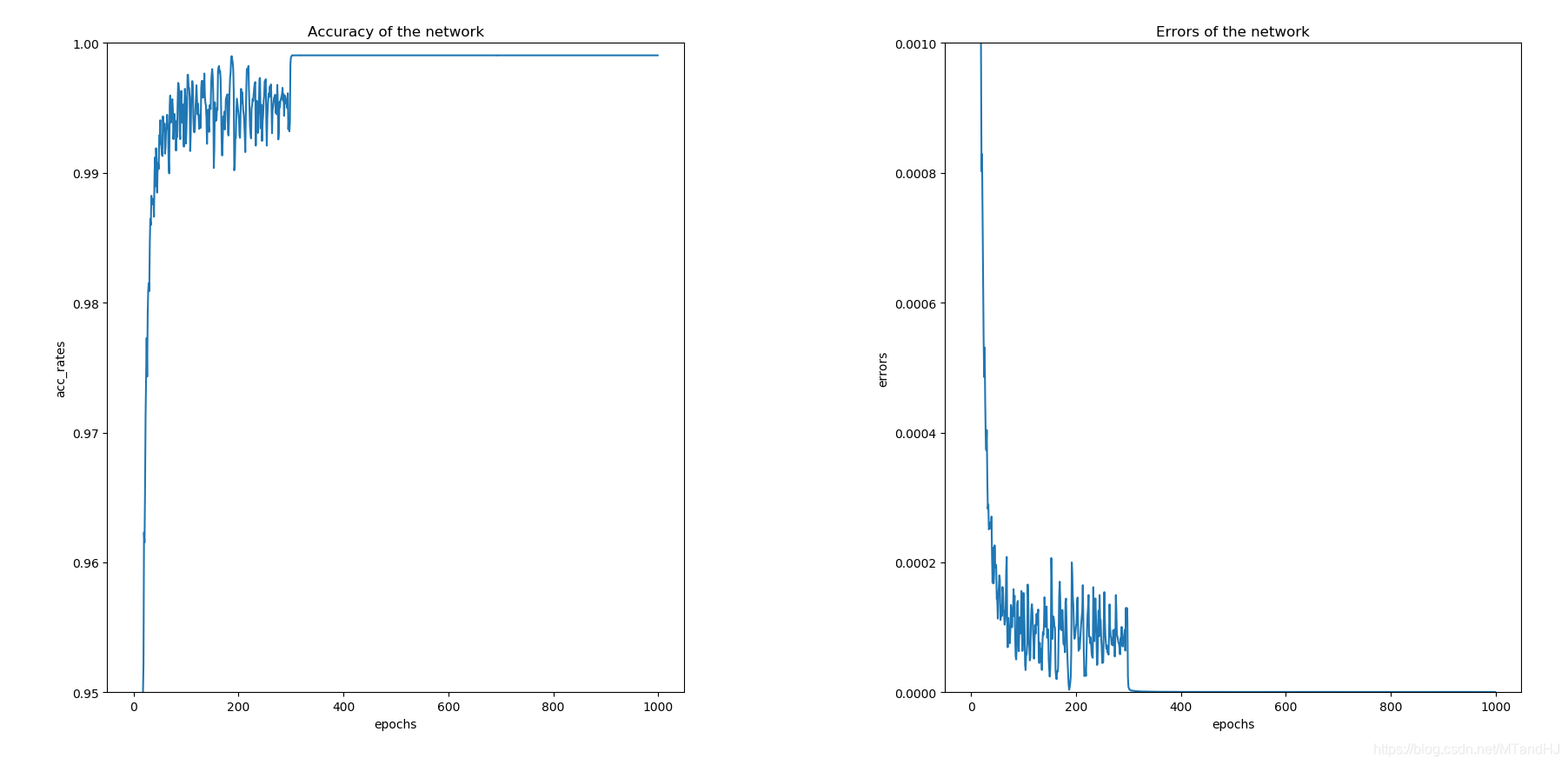
"""
Resnet34训练于CIFAR10
epoches=1000
lr=0.01 论文中0.1开始 试了以下梯度炸了 可能是网络结构的原因
momentum=0.9
weight_decay=0.0001
"""
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
import numpy as np
import os
class Residualblock(nn.Module):
def __init__(self, in_channels, out_channels,
stride=1, shortcut=None):
super(Residualblock, self).__init__()
self.longway = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, stride, 1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, 3, 1, 1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
self.shortway = shortcut
def forward(self, x):
residual = self.longway(x)
identity = x if self.shortway is None else self.shortway(x)
return nn.functional.relu(identity + residual)
class ResNet(nn.Module):
def __init__(self, out_size=10, layers=None):
"""
:param out_size: 输出的类的数量
:param layers: 每组有多少块 说不清 回看论文
"""
super(ResNet, self).__init__()
if layers is None:
layers = (2, 3, 5, 2)
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, 7, 2, 3),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2, 1)
)
self.layer1 = self._make_layer(64, 64, layers[0])
self.layer2 = self._make_layer(64, 128, layers[1], 2)
self.layer3 = self._make_layer(128, 256, layers[2], 2)
self.layer4 = self._make_layer(256, 512, layers[3], 2)
#ada_avg: 将输入(N, C, H, W) -> (N, C, H*, W*)
#下面H*, W* = 1, 1
self.avg_pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512, out_size)
#直接从pytorch源码中搬来的初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def _make_layer(self, in_channels, out_channels,
block_nums, stride=1):
shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, stride)
)
layer = [nn.Sequential(
Residualblock(in_channels, out_channels, stride, shortcut)
)]
for block in range(block_nums):
layer.append(
Residualblock(out_channels, out_channels, 1)
)
return nn.Sequential(*layer)
def forward(self, x):
x = self.conv1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avg_pool(x)
x = torch.flatten(x, 1) #展平 等价于.vier(x.size(0), -1)
out = self.fc(x)
return out
class Train:
def __init__(self, lr=0.01, momentum=0.9, weight_decay=0.0001):
self.net = ResNet()
self.criterion = nn.CrossEntropyLoss()
self.opti = torch.optim.SGD(self.net.parameters(),
lr=lr, momentum=momentum,
weight_decay=weight_decay)
self.gpu()
self.generate_path()
self.acc_rates = []
self.errors = []
def gpu(self):
self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
if torch.cuda.device_count() > 1:
print("Let'us use %d GPUs" % torch.cuda.device_count())
self.net = nn.DataParallel(self.net)
self.net = self.net.to(self.device)
def generate_path(self):
"""
生成保存数据的路径
:return:
"""
try:
os.makedirs('./paras')
os.makedirs('./logs')
os.makedirs('./infos')
except FileExistsError as e:
pass
name = self.net.__class__.__name__
paras = os.listdir('./paras')
logs = os.listdir('./logs')
infos = os.listdir('./infos')
number = max((len(paras), len(logs), len(infos)))
self.para_path = "./paras/{0}{1}.pt".format(
name,
number
)
self.log_path = "./logs/{0}{1}.txt".format(
name,
number
)
self.info_path = "./infos/{0}{1}.npy".format(
name,
number
)
def log(self, strings):
"""
运行日志
:param strings:
:return:
"""
# a 往后添加内容
with open(self.log_path, 'a', encoding='utf8') as f:
f.write(strings)
def save(self):
"""
保存网络参数
:return:
"""
torch.save(self.net.state_dict(), self.para_path)
def derease_lr(self, multi=10):
"""
降低学习率
:param multi:
:return:
"""
self.opti.param_groups()[0]['lr'] /= multi
def train(self, trainloder, epochs=50):
data_size = len(trainloder) * trainloder.batch_size
part = int(trainloder.batch_size / 2)
for epoch in range(epochs):
running_loss = 0.
total_loss = 0.
acc_count = 0.
if (epoch + 1) % int(epochs / 2) is 0:
self.derease_lr()
self.log(#日志记录
"learning rate change!!!
"
)
for i, data in enumerate(trainloder):
imgs, labels = data
imgs = imgs.to(self.device)
labels = labels.to(self.device)
out = self.net(imgs)
loss = self.criterion(out, labels)
_, pre = torch.max(out, 1) #判断是否判断正确
acc_count += (pre == labels).sum().item() #加总对的个数
self.opti.zero_grad()
loss.backward()
self.opti.step()
running_loss += loss.item()
if (i+1) % part is 0:
strings = "epoch {0:<3} part {1:<5} loss: {2:<.7f}
".format(
epoch, i, running_loss / part
)
self.log(strings)#日志记录
total_loss += running_loss
running_loss = 0.
self.acc_rates.append(acc_count / data_size)
self.errors.append(total_loss / data_size)
self.log( #日志记录
"Accuracy of the network on %d train images: %d %%
" %(
data_size, acc_count / data_size * 100
)
)
self.save() #保存网络参数
#保存一些信息画图用
np.save(self.info_path, {
'acc_rates': np.array(self.acc_rates),
'errors': np.array(self.errors)
})
if __name__ == "__main__":
root = "../../data"
trainset = torchvision.datasets.CIFAR10(root=root, train=True,
download=False,
transform=transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
))
train_loader = torch.utils.data.DataLoader(trainset, batch_size=128,
shuffle=True, num_workers=0)
dog = Train()
dog.train(train_loader, epochs=1000)