目录
@article{szegedy2015going,
title={Going deeper with convolutions},
author={Szegedy, Christian and Liu, Wei and Jia, Yangqing and Sermanet, Pierre and Reed, Scott and Anguelov, Dragomir and Erhan, Dumitru and Vanhoucke, Vincent and Rabinovich, Andrew},
pages={1--9},
year={2015}}
这里讲的很细, 不多赘诉了.
代码
"""
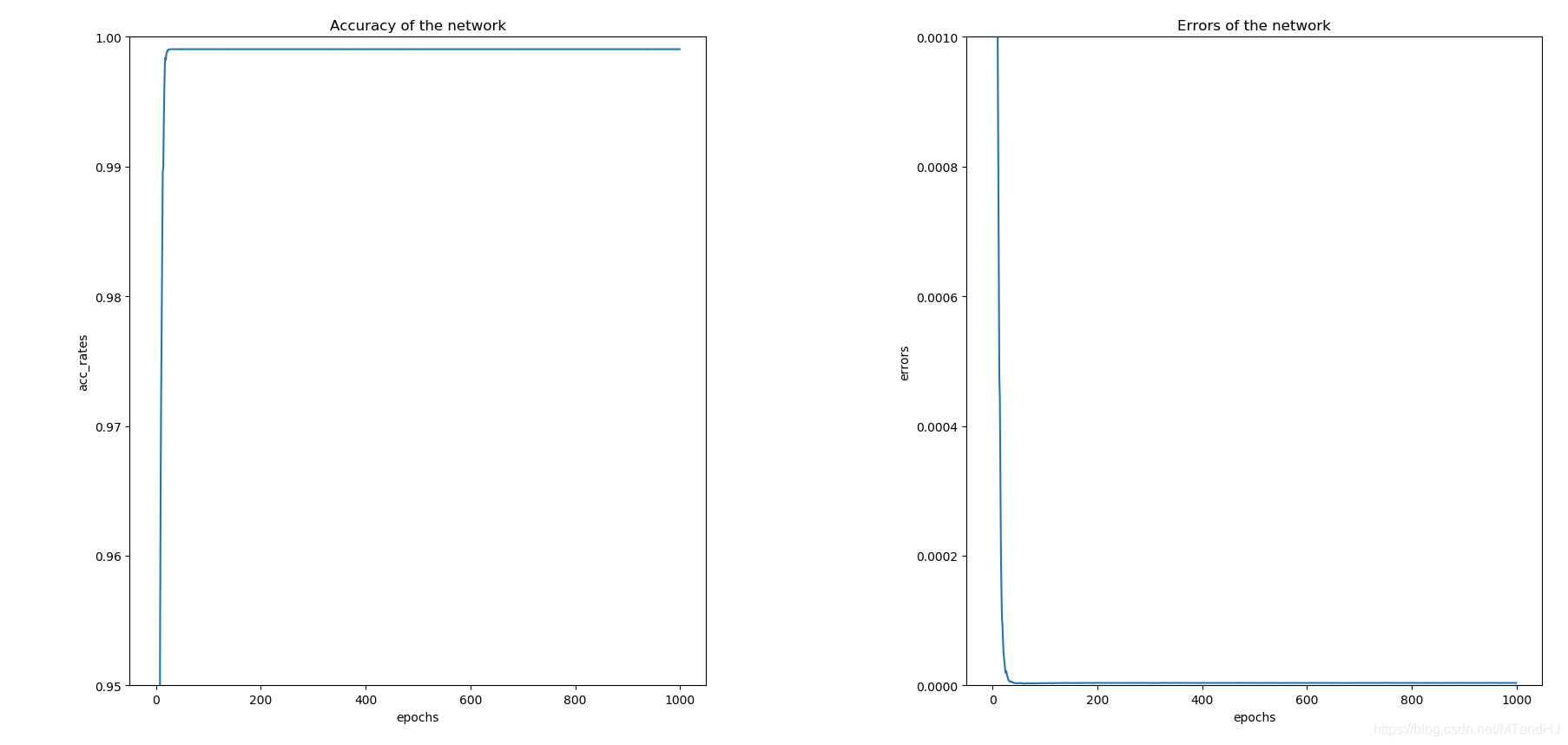
代码虽然是"copy"源代码, 但是收获不少.
虽然参数少, 但是训练得很慢, 是因为要传三次梯度?
测试集上正确率维0.8682
"""
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
import numpy as np
import os
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels,
bias=False, **kwargs) #不要偏置
#eps 为了数值稳定 默认是1e-5
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
out = self.relu(x)
return out
class Inception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3,
ch5x5red, ch5x5, pool_proj):
"""
:param in_channels: 输入的通道数
:param ch1x1: 1x1卷积核的输出通道数
:param ch3x3red: 3x3一开始的1x1部分的通道数
:param ch3x3: 3x3后半的3x3部分的通道数
:param ch5x5: ...
:param ch5x5red: ...
:param pool_proj: 池化层的通道数
"""
super(Inception, self).__init__()
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1)
)
#pytorch 这里用的3x3卷积核?
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch5x5red, kernel_size=1),
BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2)
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1, ceil_mode=True),
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
def forward(self, x):
x1 = self.branch1(x)
x2 = self.branch2(x)
x3 = self.branch3(x)
x4 = self.branch4(x)
out = (x1, x2, x3, x4)
return torch.cat(out, 1)
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.avgpool = nn.AdaptiveAvgPool2d((4, 4))
self.conv = BasicConv2d(in_channels, 128, kernel_size=1)
#N x 128 x 4 x 4
self.dense = nn.Sequential(
nn.Linear(2048, 1024),
nn.ReLU(inplace=True),
nn.Dropout(0.7),
nn.Linear(1024, num_classes)
)
def forward(self, x):
x = self.avgpool(x)
x = self.conv(x)
x = torch.flatten(x, 1)
out = self.dense(x)
return out
class GoogLeNet(nn.Module):
def __init__(self, num_classes=10, aux_logits=True):
"""
:param num_classes: 类别个数
:param aux_logits: 是否需要添加辅助训练器
"""
super(GoogLeNet, self).__init__()
self.aux_logits =aux_logits
# N x 3 x 224 x 224
self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)
# N x 64 x 112 x 112
self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
# N x 64 x 56 x 56
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
# N x 192 x 56 x 56
self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
# N x 192 x 28 x 28
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
#N x 256 x 28 x 28
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
#N x 480 x 28 x 28
self.maxpool3 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
#N x 480 x 14 x 14
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
#N x 512 x 14 x 14
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
#N x 512 x 14 x 14
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
#N x 512 x 14 x 14
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
#N x 528 x 14 x 14
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
#N x 832 x 14 x 14
self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
#N x 832 x 7 x 7
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
#N x 832 x 7 x 7
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
#N x 1024 x 7 x 7
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
#N x 1024 x 1 x 1
self.drop = nn.Dropout(0.4)
self.fc = nn.Linear(1024, num_classes)
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.maxpool2(x)
x = self.inception3a(x)
x = self.inception3b(x)
x = self.maxpool3(x)
x = self.inception4a(x)
if self.aux_logits and self.training:
aux1 = self.aux1(x)
x = self.inception4b(x)
x = self.inception4c(x)
x = self.inception4d(x)
if self.aux_logits and self.training:
aux2 = self.aux2(x)
x = self.inception4e(x)
x = self.maxpool4(x)
x = self.inception5a(x)
x = self.inception5b(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.drop(x)
out = self.fc(x)
if self.aux_logits and self.training:
return (out, aux1, aux2)
return out
class Train:
def __init__(self, lr=0.01, momentum=0.9, weight_decay=0.0001):
self.net = GoogLeNet()
self.criterion = nn.CrossEntropyLoss()
self.opti = torch.optim.SGD(self.net.parameters(),
lr=lr, momentum=momentum,
weight_decay=weight_decay)
self.gpu()
self.generate_path()
self.acc_rates = []
self.errors = []
def gpu(self):
self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
if torch.cuda.device_count() > 1:
print("Let'us use %d GPUs" % torch.cuda.device_count())
self.net = nn.DataParallel(self.net)
self.net = self.net.to(self.device)
def generate_path(self):
"""
生成保存数据的路径
:return:
"""
try:
os.makedirs('./paras')
os.makedirs('./logs')
os.makedirs('./infos')
except FileExistsError as e:
pass
name = self.net.__class__.__name__
paras = os.listdir('./paras')
logs = os.listdir('./logs')
infos = os.listdir('./infos')
number = max((len(paras), len(logs), len(infos)))
self.para_path = "./paras/{0}{1}.pt".format(
name,
number
)
self.log_path = "./logs/{0}{1}.txt".format(
name,
number
)
self.info_path = "./infos/{0}{1}.npy".format(
name,
number
)
def log(self, strings):
"""
运行日志
:param strings:
:return:
"""
# a 往后添加内容
with open(self.log_path, 'a', encoding='utf8') as f:
f.write(strings)
def save(self):
"""
保存网络参数
:return:
"""
torch.save(self.net.state_dict(), self.para_path)
def derease_lr(self, multi=0.96):
"""
降低学习率
:param multi:
:return:
"""
self.opti.param_groups[0]['lr'] *= multi
def train(self, trainloder, epochs=50):
data_size = len(trainloder) * trainloder.batch_size
part = int(trainloder.batch_size / 2)
for epoch in range(epochs):
running_loss = 0.
total_loss = 0.
acc_count = 0.
if (epoch + 1) % 8 is 0:
self.derease_lr()
self.log(#日志记录
"learning rate change!!!
"
)
for i, data in enumerate(trainloder):
imgs, labels = data
imgs = imgs.to(self.device)
labels = labels.to(self.device)
(out, aux1, aux2) = self.net(imgs)
loss1 = self.criterion(out, labels)
loss2 = self.criterion(aux1, labels)
loss3 = self.criterion(aux2, labels)
loss = 0.4 * loss1 + 0.3 * loss2 + 0.3 * loss3
_, pre = torch.max(out, 1) #判断是否判断正确
acc_count += (pre == labels).sum().item() #加总对的个数
self.opti.zero_grad()
loss.backward()
self.opti.step()
running_loss += loss.item()
if (i+1) % part is 0:
strings = "epoch {0:<3} part {1:<5} loss: {2:<.7f}
".format(
epoch, i, running_loss / part
)
self.log(strings)#日志记录
total_loss += running_loss
running_loss = 0.
self.acc_rates.append(acc_count / data_size)
self.errors.append(total_loss / data_size)
self.log( #日志记录
"Accuracy of the network on %d train images: %d %%
" %(
data_size, acc_count / data_size * 100
)
)
self.save() #保存网络参数
#保存一些信息画图用
np.save(self.info_path, {
'acc_rates': np.array(self.acc_rates),
'errors': np.array(self.errors)
})
if __name__ == "__main__":
root = "../../data"
trainset = torchvision.datasets.CIFAR10(root=root, train=True,
download=False,
transform=transforms.Compose(
[transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
))
train_loader = torch.utils.data.DataLoader(trainset, batch_size=128,
shuffle=True, num_workers=8,
pin_memory=True)
dog = Train()
dog.train(train_loader, epochs=1000)