Linux的numactl
转载:https://www.cnblogs.com/tcicy/p/10191505.html#top
NUMA的取舍与优化设置
注意:numactl和numastat无法查看某个进程当前用的什么内存策略!!
在os层numa关闭时,打开bios层的numa会影响性能,QPS会下降15-30%;
在bios层面numa关闭时,无论os层面的numa是否打开,都不会影响性能。
默认系统没有自带numactl,需要安装numactl:
#yum install numactl -y#numastat 等同于 cat /sys/devices/system/node/node0/numastat ,numactl包里包含numastat
在/sys/devices/system/node/文件夹中记录系统中的所有内存节点的相关详细信息。
#numactl --hardware 列举系统上的NUMA节点
#numactl --show 查看绑定信息
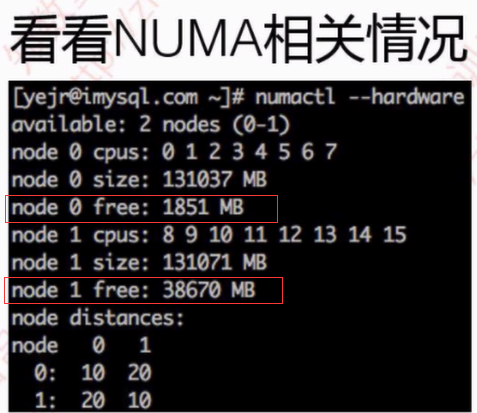

Redhat或者Centos系统中可以通过命令判断bios层是否开启numa
# grep -i numa /var/log/dmesg No NUMA configuration found
说明numa为disable,如果不是上面内容说明numa为enable,例如显示:
NUMA: Using 30 for the hash shift.
可以通过lscpu命令查看机器的NUMA拓扑结构。
root@mongo_mongo_16 tmp]# lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 2 On-line CPU(s) list: 0,1 Thread(s) per core: 1 Core(s) per socket: 2 Socket(s): 1 NUMA node(s): 1 Vendor ID: GenuineIntel CPU family: 6 Model: 45 Model name: Intel(R) Xeon(R) CPU E5-2680 0 @ 2.70GHz Stepping: 7 CPU MHz: 2699.148 BogoMIPS: 5400.00 Hypervisor vendor: VMware Virtualization type: full L1d cache: 32K L1i cache: 32K L2 cache: 256K L3 cache: 20480K NUMA node0 CPU(s): 0,1 Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts mmx fxsr sse sse2 ss ht syscall nx rdtscp lm constant_tsc arch_perfmon pebs bts nopl xtopology tsc_reliable nonstop_tsc pni pclmulqdq ssse3 cx16 pcid sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer aes xsave avx hypervisor lahf_lm arat tsc_adjust
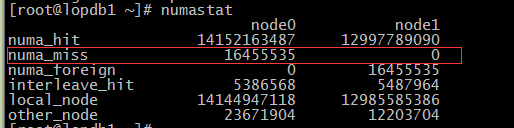
当发现numa_miss数值比较高时,说明需要对分配策略进行调整。例如将指定进程关联绑定到指定的CPU上,从而提高内存命中率。
---------------------------------------------
现在的机器上都是有多个CPU和多个内存块的。以前我们都是将内存块看成是一大块内存,所有CPU到这个共享内存的访问消息是一样的。这就是之前普遍使用的SMP模型。但是随着处理器的增加,共享内存可能会导致内存访问冲突越来越厉害,且如果内存访问达到瓶颈的时候,性能就不能随之增加。NUMA(Non-Uniform Memory Access)就是这样的环境下引入的一个模型。比如一台机器是有2个处理器,有4个内存块。我们将1个处理器和两个内存块合起来,称为一个NUMA node,这样这个机器就会有两个NUMA node。在物理分布上,NUMA node的处理器和内存块的物理距离更小,因此访问也更快。比如这台机器会分左右两个处理器(cpu1, cpu2),在每个处理器两边放两个内存块(memory1.1, memory1.2, memory2.1,memory2.2),这样NUMA node1的cpu1访问memory1.1和memory1.2就比访问memory2.1和memory2.2更快。所以使用NUMA的模式如果能尽量保证本node内的CPU只访问本node内的内存块,那这样的效率就是最高的。
在运行程序的时候使用numactl -m和-physcpubind就能制定将这个程序运行在哪个cpu和哪个memory中。玩转cpu-topology 给了一个表格,当程序只使用一个node资源和使用多个node资源的比较表(差不多是38s与28s的差距)。所以限定程序在numa node中运行是有实际意义的。
但是呢,话又说回来了,制定numa就一定好吗?--numa的陷阱。SWAP的罪与罚文章就说到了一个numa的陷阱的问题。
numa陷阱
现象是当你的服务器还有内存的时候,发现它已经在开始使用swap了,甚至已经导致机器出现停滞的现象。这个就有可能是由于numa的限制,如果一个进程限制它只能使用自己的numa节点的内存,那么当自身numa node内存使用光之后,就不会去使用其他numa node的内存了,会开始使用swap,甚至更糟的情况,机器没有设置swap的时候,可能会直接死机!所以你可以使用numactl --interleave=all来取消numa node的限制。
综上所述得出的结论就是,根据具体业务决定NUMA的使用。
如果你的程序是会占用大规模内存的,你大多应该选择关闭numa node的限制(或从硬件关闭numa)。因为这个时候你的程序很有几率会碰到numa陷阱。
另外,如果你的程序并不占用大内存,而是要求更快的程序运行时间。你大多应该选择限制只访问本numa node的方法来进行处理。
---------------------------------------------------------------------
内核参数overcommit_memory :
它是 内存分配策略
可选值:0、1、2。
0:表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程。
1:表示内核允许分配所有的物理内存,而不管当前的内存状态如何。
2:表示内核允许分配超过所有物理内存和交换空间总和的内存
内核参数zone_reclaim_mode:
可选值0、1
a、当某个节点可用内存不足时:
1、如果为0的话,那么系统会倾向于从其他节点分配内存
2、如果为1的话,那么系统会倾向于从本地节点回收Cache内存多数时候
b、Cache对性能很重要,所以0是一个更好的选择
----------------------------------------------------------------------
mongodb的NUMA问题
mongodb日志显示如下:
WARNING: You are running on a NUMA machine.
We suggest launching mongod like this to avoid performance problems:
numactl –interleave=all mongod [other options]
解决方案,临时修改numa内存分配策略为 interleave=all (在所有node节点进行交织分配的策略):
1.在原启动命令前面加numactl –interleave=all
如# numactl --interleave=all ${MONGODB_HOME}/bin/mongod --config conf/mongodb.conf
2.修改内核参数
echo 0 > /proc/sys/vm/zone_reclaim_mode ; echo "vm.zone_reclaim_mode = 0" >> /etc/sysctl.conf
----------------------------------------------------------------------
一、NUMA和SMP
NUMA和SMP是两种CPU相关的硬件架构。在SMP架构里面,所有的CPU争用一个总线来访问所有内存,优点是资源共享,而缺点是总线争用激烈。随着PC服务器上的CPU数量变多(不仅仅是CPU核数),总线争用的弊端慢慢越来越明显,于是Intel在Nehalem CPU上推出了NUMA架构,而AMD也推出了基于相同架构的Opteron CPU。
NUMA最大的特点是引入了node和distance的概念。对于CPU和内存这两种最宝贵的硬件资源,NUMA用近乎严格的方式划分了所属的资源组(node),而每个资源组内的CPU和内存是几乎相等。资源组的数量取决于物理CPU的个数(现有的PC server大多数有两个物理CPU,每个CPU有4个核);distance这个概念是用来定义各个node之间调用资源的开销,为资源调度优化算法提供数据支持。
二、NUMA相关的策略
1、每个进程(或线程)都会从父进程继承NUMA策略,并分配有一个优先node。如果NUMA策略允许的话,进程可以调用其他node上的资源。
2、NUMA的CPU分配策略有2种:cpunodebind、physcpubind。
(1)cpunodebind规定进程运行在某几个node之上
(2)physcpubind可以更加精细地规定运行在哪些核上。
3、NUMA的内存分配策略有4种:localalloc、preferred、membind、interleave。
(1)localalloc规定进程从当前node上请求分配内存;
(2)preferred比较宽松地指定了一个推荐的node来获取内存,如果被推荐的node上没有足够内存,进程可以尝试别的node。
(3)membind可以指定若干个node,进程只能从这些指定的node上请求分配内存。
(4)interleave规定进程从指定的若干个node上以RR(Round Robin 轮询调度)算法交织地请求分配内存。
因为NUMA默认的内存分配策略是优先在进程所在CPU的本地内存中分配,会导致CPU节点之间内存分配不均衡,当某个CPU节点的内存不足时,会导致swap产生,而不是从远程节点分配内存。这就是所谓的swap insanity 现象。
MySQL采用了线程模式,对于NUMA特性的支持并不好,如果单机只运行一个MySQL实例,我们可以选择关闭NUMA,关闭的方法有三种:
1.硬件层,在BIOS中设置关闭
2.OS内核,启动时设置numa=off;
3.可以用numactl命令将内存分配策略修改为interleave(交叉)。
如果单机运行多个MySQL实例,我们可以将MySQL绑定在不同的CPU节点上,并且采用绑定的内存分配策略,强制在本节点内分配内存,这样既可以充分利用硬件的NUMA特性,又避免了单实例MySQL对多核CPU利用率不高的问题
三、NUMA和swap的关系
可能大家已经发现了,NUMA的内存分配策略对于进程(或线程)之间来说,并不是公平的。在现有的Redhat Linux中,localalloc是默认的NUMA内存分配策略,这个配置选项导致资源独占程序很容易将某个node的内存用尽。而当某个node的内存耗尽时,Linux又刚好将这个node分配给了某个需要消耗大量内存的进程(或线程),swap就妥妥地产生了。尽管此时还有很多page cache可以释放,甚至还有很多的free内存。
四、解决swap问题
虽然NUMA的原理相对复杂,实际上解决swap却很简单:只要在启动MySQL之前使用numactl –interleave来修改NUMA策略即可。
值得注意的是,numactl这个命令不仅仅可以调整NUMA策略,也可以用来查看当前各个node的资源使用情况,是一个很值得研究的命令。
一、CPU
首先从CPU说起。
你仔细检查的话,有些服务器上会有的一个有趣的现象:你cat /proc/cpuinfo时,会发现CPU的频率竟然跟它标称的频率不一样:
#cat /proc/cpuinfo
processor : 5
model name : Intel(R) Xeon(R) CPU E5-2620 0 @2.00GHz
cpu MHz : 1200.000
这个是Intel E5-2620的CPU,他是2.00G * 24的CPU,但是,我们发现第5颗CPU的频率为1.2G。
这是什么原因呢?
这些其实都源于CPU最新的技术:节能模式。操作系统和CPU硬件配合,系统不繁忙的时候,为了节约电能和降低温度,它会将CPU降频。这对环保人士和抵制地球变暖来说是一个福音,但是对MySQL来说,可能是一个灾难。
为了保证MySQL能够充分利用CPU的资源,建议设置CPU为最大性能模式。这个设置可以在BIOS和操作系统中设置,当然,在BIOS中设置该选项更好,更彻底。由于各种BIOS类型的区别,设置为CPU为最大性能模式千差万别,我们这里就不具体展示怎么设置了。
然后我们看看内存方面,我们有哪些可以优化的。
i) 我们先看看numa
非一致存储访问结构 (NUMA : Non-Uniform Memory Access) 也是最新的内存管理技术。它和对称多处理器结构 (SMP : Symmetric Multi-Processor) 是对应的。简单的队别如下:
如图所示,详细的NUMA信息我们这里不介绍了。但是我们可以直观的看到:SMP访问内存的都是代价都是一样的;但是在NUMA架构下,本地内存的访问和非 本地内存的访问代价是不一样的。对应的根据这个特性,操作系统上,我们可以设置进程的内存分配方式。目前支持的方式包括:
--interleave=nodes
--membind=nodes
--cpunodebind=nodes
--physcpubind=cpus
--localalloc
--preferred=node
简而言之,就是说,你可以指定内存在本地分配,在某几个CPU节点分配或者轮询分配。除非 是设置为--interleave=nodes轮询分配方式,即内存可以在任意NUMA节点上分配这种方式以外。其他的方式就算其他NUMA节点上还有内 存剩余,Linux也不会把剩余的内存分配给这个进程,而是采用SWAP的方式来获得内存。有经验的系统管理员或者DBA都知道SWAP导致的数据库性能 下降有多么坑爹。
所以最简单的方法,还是关闭掉这个特性。
关闭特性的方法,分别有:可以从BIOS,操作系统,启动进程时临时关闭这个特性。
a) 由于各种BIOS类型的区别,如何关闭NUMA千差万别,我们这里就不具体展示怎么设置了。
b) 在操作系统中关闭,可以直接在/etc/grub.conf的kernel行最后添加numa=off,15%左右的性能损耗,如下所示:
kernel /vmlinuz-2.6.32-220.el6.x86_64 ro root=/dev/mapper/VolGroup-root rd_NO_LUKS LANG=en_US.UTF-8 rd_LVM_LV=VolGroup/root rd_NO_MD quiet SYSFONT=latarcyrheb-sun16 rhgb crashkernel=auto rd_LVMel=auto quiet KEYBOARDTYPE=pc KEYTABLE=us rd_NO_DM numa=off
另外可以设置 vm.zone_reclaim_mode=0尽量回收内存。
c) 启动MySQL的时候,关闭NUMA特性:
numactl --interleave=all mysqld
当然,最好的方式是在BIOS中关闭。
ii) 我们再看看vm.swappiness。
vm.swappiness是操作系统控制物理内存交换出去的策略。它允许的值是一个百分比的值,最小为0,最大运行100,该值默认为60。vm.swappiness设置为0表示尽量少swap,100表示尽量将inactive的内存页交换出去。
具体的说:当内存基本用满的时候,系统会根据这个参数来判断是把内存中很少用到的inactive 内存交换出去,还是释放数据的cache。cache中缓存着从磁盘读出来的数据,根据程序的局部性原理,这些数据有可能在接下来又要被读 取;inactive 内存顾名思义,就是那些被应用程序映射着,但是 长时间 不用的内存。
我们可以利用vmstat看到inactive的内存的数量:
#vmstat -an 1
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free inact active si so bi bo in cs us sy id wa st
1 0 0 27522384 326928 1704644 0 0 0 153 11 10 0 0 100 0 0
0 0 0 27523300 326936 1704164 0 0 0 74 784 590 0 0 100 0 0
0 0 0 27523656 326936 1704692 0 0 8 8 439 1686 0 0 100 0 0
0 0 0 27524300 326916 1703412 0 0 4 52 198 262 0 0 100 0 0
通过/proc/meminfo 你可以看到更详细的信息:
#cat /proc/meminfo | grep -i inact
Inactive: 326972 kB
Inactive(anon): 248 kB
Inactive(file): 326724 kB
这里我们对不活跃inactive内存进一步深入讨论。 Linux中,内存可能处于三种状态:free,active和inactive。众所周知,Linux Kernel在内部维护了很多LRU列表用来管理内存,比如LRU_INACTIVE_ANON, LRU_ACTIVE_ANON, LRU_INACTIVE_FILE , LRU_ACTIVE_FILE, LRU_UNEVICTABLE。其中LRU_INACTIVE_ANON, LRU_ACTIVE_ANON用来管理匿名页,LRU_INACTIVE_FILE , LRU_ACTIVE_FILE用来管理page caches页缓存。系统内核会根据内存页的访问情况,不定时的将活跃active内存被移到inactive列表中,这些inactive的内存可以被 交换到swap中去。
一般来说,MySQL,特别是InnoDB管理内存缓存,它占用的内存比较多,不经常访问的内存也会不少,这些内存如果被Linux错误的交换出去了,将浪费很多CPU和IO资源。 InnoDB自己管理缓存,cache的文件数据来说占用了内存,对InnoDB几乎没有任何好处。
所以,我们在MySQL的服务器上最好设置vm.swappiness=1或0
https://www.cnblogs.com/tcicy/p/10191505.html
numactl --help
numactl: unrecognized option '--help' usage: numactl [--all | -a] [--interleave= | -i <nodes>] [--preferred= | -p <node>] [--physcpubind= | -C <cpus>] [--cpunodebind= | -N <nodes>] [--membind= | -m <nodes>] [--localalloc 默认策略 | -l] command args ... numactl [--show | -s] numactl [--hardware | -H] numactl [--length | -l <length>] [--offset | -o <offset>] [--shmmode | -M <shmmode>] [--strict | -t] [--shmid | -I <id>] --shm | -S <shmkeyfile> [--shmid | -I <id>] --file | -f <tmpfsfile> [--huge | -u] [--touch | -T] memory policy | --dump | -d | --dump-nodes | -D memory policy is --interleave | -i, --preferred | -p, --membind | -m, --localalloc | -l <nodes> is a comma delimited list of node numbers or A-B ranges or all. Linux系统对于NUMA的CPU分配策略有cpunodebind、physcpubind。cpunodebind规定进程运行在某几个node之上,而physcpubind可以更加精细地规定运行在哪些核上。 Linux系统对于NUMA的内存分配策略有localalloc、preferred、membind、interleave。 Instead of a number a node can also be: netdev:DEV the node connected to network device DEV file:PATH the node the block device of path is connected to ip:HOST the node of the network device host routes through block:PATH the node of block device path pci:[seg:]bus:dev[:func] The node of a PCI device <cpus> is a comma delimited list of cpu numbers or A-B ranges or all all ranges can be inverted with ! all numbers and ranges can be made cpuset-relative with + the old --cpubind argument is deprecated. use --cpunodebind or --physcpubind instead <length> can have g (GB), m (MB) or k (KB) suffixes
f
