版权声明:本文为博主原创文章,转载 请注明出处: https://blog.csdn.net/sc2079/article/details/82016583
10月18日更:MOOC课程信息D3.js动态可视化
9月2日更:中国大学MOOC课程信息之数据分析可视化二
9月1日更:关于MOOC的课程信息数据分析,参看:中国大学MOOC课程信息之数据分析可视化一
-
写在前面
暑假没事玩玩爬虫,看到中国大学MOOC便想爬取它所有课程信息。无奈,它不是静态网页,课程数据都是动态加载的。而爬取动态页面目前来说有两种方法:
- 分析页面Ajax请求
- selenium模拟浏览器行为
可能方法不正确,我尝试了前者发现行不通,便采用了后者。由于第一次写博客且自己编程能力有限,文中有不足或需要改进的地方请不吝赐教。
-
环境配置及模块安装
编译环境: Python3.6 、Spyder
依赖模块:pymysql,selenuim,bs4,re等
另外还要下载chromedriver并配置,参考这篇文章
-
简要分析流程
-
主页分析

主页上便有课程类别,可以将其保存为字典,通过不同课程类别便可到达相应课程类别界面。
subjects={'全部':'all_sub','计算机':'computer','经济管理':'management','心理学':'psychology',
'外语':'language','文学历史':'literary_history','艺术设计':'art','工学':'engineering',
'理学':'science','生命科学':'biomedicine','哲学':'philosophy','法学':'law',
'教育教学':'teaching_method','大学先修课':'advanced_placement','职业教育课程':'TAFE'}
for i,subject in enumerate(subjects):
subject_Eng=subjects[subject]
mooc_crawl(subject,subject_Eng)
每个页面都有都可找到多个这样的课程信息。

点击下一页可实现翻页。
2.网页解析
加载Chrome网页
url = 'http://www.icourse163.org/category/all'
driver = webdriver.Chrome()
driver.set_page_load_timeout(50)
driver.get(url)
driver.maximize_window() # 将浏览器最大化显示
driver.implicitly_wait(5) # 控制间隔时间,等待浏览器反应选择课程类别,模拟点击;获取网页源码,Beautifulsou解析
ele=driver.find_element_by_link_text(subject)
ele.click()
htm_const = driver.page_source
soup = BS(htm_const,'xml')
返回soup对象,便可看到动态加载好的网页源码。由于是txt文档,虽然不好查看,但并不妨碍我们找到需要的信息。从上面截图可以看到了一些课程的课程名、开课老师、网页链接、参与人数等。因此从这里入手,我们便可得到该页面的课程信息!
c_names=soup.find_all(name='img',attrs={'height':'150px'})
c_schools=soup.find_all(name='a',attrs={'class':'t21 f-fc9'})
c_teachers=soup.find_all(name='a',attrs={'class':'f-fc9'})
c_introductions=soup.find_all(name='span',attrs={'class':'p5 brief f-ib f-f0 f-cb'})
c_stunums=soup.find_all(name='span',attrs={'class':'hot'})
c_start_times=soup.find_all(name='span',attrs={'class':'txt'})
c_links=soup.find_all(name='span',attrs={'class':' u-course-name f-thide'})
for i in range(len(c_names)):
kc_names.append(c_names[i]['alt'])
kc_schools.append(c_schools[i].string)
kc_teachers.append(c_teachers[i].string)
if c_introductions[i].string ==None:
c_introduction=''
else:
c_introduction=c_introductions[i].string
kc_introductions.append(c_introduction)
c_stunum=re.compile('[0-9]+').findall(c_stunums[i].string)[0]
kc_stunums.append(int(c_stunum))
kc_start_times.append(c_start_times[i].string)
kc_links.append('http:'+c_links[i].parent['href'])
c_id_num=re.compile('[0-9]{4,}').findall(c_links[i].parent['href'])[0]
kc_id_nums.append(int(c_id_num))
kc_info=[kc_names,kc_schools,kc_teachers,kc_introductions,kc_stunums,kc_start_times,kc_links,kc_id_nums]如下:

接下来,便是数据存储啦。
-
数据存储
由于mysql功能强大,操作简便,python对其支持性较好,我就选用了mysql。不过其他数据库皆可,数据存储原理大同小异。在实现过程中,遇到了很多问题(SQL语句报错,主键的设置让每次插入数据都不重复,以变量为表单名的表单建立等等),好在花了一些功夫后,最终得以解决。下面是存入数据库函数:
def save_mysql(subject,kc_info):
db = pymysql.connect(host='localhost',user='root',passwd='root',db='mooc_courses',charset='utf8')
cur = db.cursor()
try:
cur.execute("select * from %s"% subject)
results=cur.fetchall()
ori_len=len(results)
except:
#建立新表
sql = "create table %s"% subject+"(order_num int(4) not null,
course varchar(50),
school varchar(20),
teacher varchar(20),
start_time varchar(20),
stu_num int(6),
introduction varchar(255),
link varchar(50),
id int(11) not null,
primary key(id)
)"
cur.execute(sql)
db.commit()
ori_len=0
print('已在mooc_course数据库中建立新表'+subject)
for i in range(len(kc_info[0])):
cur = db.cursor()
sql = "insert into %s"% subject+"(order_num,course,school,teacher,introduction,stu_num,start_time,link,id) VALUES ('%d','%s','%s','%s','%s','%d','%s','%s','%d')" %
(ori_len+i,kc_info[0][i],kc_info[1][i],kc_info[2][i],kc_info[3][i],kc_info[4][i],kc_info[5][i],kc_info[6][i],kc_info[7][i])#执行数据库插入操作
try:
# 使用 cursor() 方法创建一个游标对象 cursor
cur.execute(sql)
except Exception as e:
# 发生错误时回滚
db.rollback()
print('第'+str(i+1)+'数据存入数据库失败!'+str(e))
else:
db.commit() # 事务提交
print('第'+str(i+1)+'数据已存入数据库')
db.close()当当当!修成正果,部分数据展示如下:
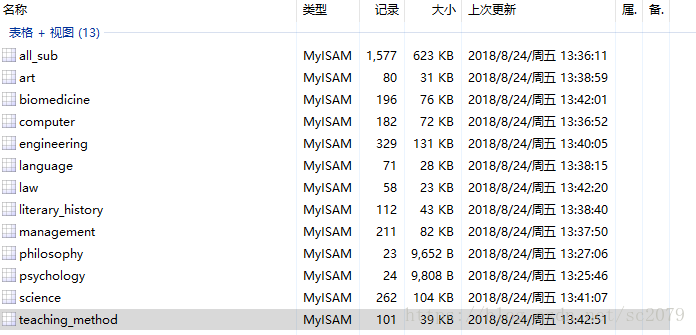
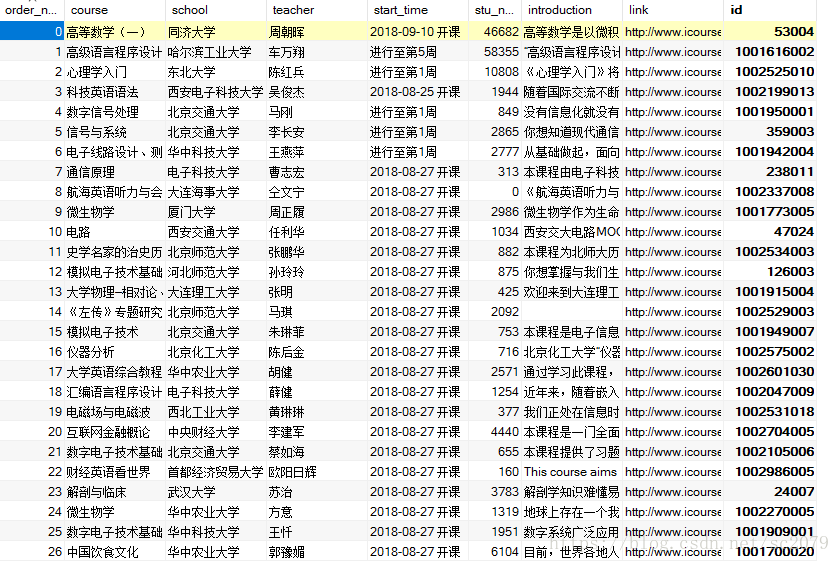
执行整个程序一共花了:726s,效率有待提高。不过对于我来说,还过得去。(实在不行,加多线程撒)。当然,数据爬取了,必须利用嘛,不然放在那里养老不?有空,我做做数据分析,看看什么课最受欢迎,哪些院校开课最多等等。。。。。。
Github传送门:https://github.com/SCHaoZhang/python/tree/master/mooc_courses