centos shell基础知识 alias 变量单引号 双引号 history 错误重定向 2>&1 jobs 环境变量 .bash_history source配置文件 nohup & 后台运行 cut,sort,wc ,uniq ,tee ,tr ,split, paste cat> 2.txt <<EOF 通配符 glob模式 发邮件命令mail 2015-4-8 第十二节课
set unset export
上半节课
history:命令历史
alias :
alias a="b"
unalias a //取消alias
通配符 glob模式
输入输出重定向
作业控制
管道符
SHELL变量
下半节课
source和. 点使配置文件
/etc/profile
/etc/bashrc
~/.bash_profile
~/.bashrc
.bash_history
.bash_logout
shell中的特殊符号
常用命令cut,sort,wc ,uniq ,tee ,tr ,split ,paste
&& 和 ||和;
history:命令历史(~/.bash_history ) ,默认保存1000条命令历史
!!:上一条命令
!$:上一条命令的最后一个参数
!n:执行命令历史里的第n条命令
!字符:最近那个字符的命令
$?:返回命令是否执行成功,成功返回0
alias
注意: alias 空格 cp='cp -i' cp和等于号之间不能有空格! 因为看作是变量! 所有一切赋值的操作都不能有空格!按照shell的定义来写
# alias alias cp='cp -i' alias l.='ls -d .* --color=auto' alias ll='ls -l --color=auto' alias ls='ls --color=auto' alias mv='mv -i' alias rm='rm -i' alias which='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tild
alias a="b" unalias a //取消alias [root@sxx ~]# which rm alias rm='rm -i' /bin/rm [root@sxx ~]# alias rm alias rm='rm -i'
http://www.oschina.net/question/1588291_166511
实际上cp默认是会覆盖的,出现你这种情况是因为cp被alias成cp -i了,可以通过alias命令查看。
cp则是告诉shell不要去查alias,直接执行原本的cp
目前,我得知有四种方法:
1.在调用cp的时候加入绝对路径(可通过whereis cp命令得到),如
/bin/cp -f file dir
2.通过直接执行下面的语句调用系统原始的命令:
cp -f file dir
3.在~/.bashrc里面注释掉 Alias cp='cp -i'
4.unalias cp ,然后再使用cp,但使用后还原alias cp='cp -i'
通配符 glob模式 简化的正则
*匹配零个或多个字符
?匹配一个字符
[] 任意一个 [|]或者 [^]非
输入输出重定向 >, <, >>, <<, 2>, 2>>
//下面两个命令等价 反向重定向 [root@steven ~]# cat 123.txt sdf [root@steven ~]# cat < 123.txt sdf
//错误重定向 ls xx 2>error.log
echo "22" >>error.log 2>&1 //2>&1 能追加 即使开始没有error.log一样可以追加,这样后续的内容不会覆盖error.log原先的内容
管道符 |: ls |xargs //显示在一行
作业控制
ctrl+z:停止前台任务放到后台
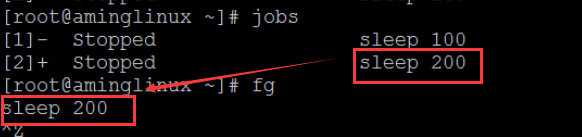
jobs:查看当前在运行的前/后台任务和ID号
# jobs [1]- Done nohup nc -z -w2 www.baidu.com 1-1024 >> /root/111.txt 2>&1 & [2]+ Running nohup nc -z -w2 www.baidu.com 2000-4000 >> /root/111.txt 2>&1 &
%n 作业号n
kill %1 //杀死作业
10400,10410是pid,1,2是作业号
# jobs -l [1]+ 10400 Stopped vim 123 [2]- 10410 Running sleep 200 &
fg: fg 3 //前台运行ID为3的命令 jobs显示的数字ID 或 fg %3
加号表示优先级高
bg: bg 3 //后台运行ID为3的命令 或 bg %3
发送邮件
echo 'sdf' #内容 |mail -s "te" #主题 linyonghua.hi@163.com
echo 'sdf' |mail -s "te" linyonghua.hi@163.com
top -bn 1 |mail -s 'hig $cc' abc@163.com
SHELL变量
系统变量名都是大写,自己定义变量小写
echo 可以查看变量名 $PATH ,$HOME, $LANG, $HOSTNAME
steven@VM~]$ echo $PATH /usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/steven/bin [steven@VM ~]$ echo $HOME /home/steven [steven@VM ~]$ echo $HOSTNAME VM [steven@VM~]$ echo $LANG C
set比env强,尽量用set
env 命令:可以列出当前用户的所有环境变量以及用户自定义全局变量 export
env |grep '^a' //查看一下是否有用户自定义a变量
# set |grep '^a' //查看一下是否有用户自定义a变量 a=1
set命令:可以把所有变量列出来包括系统的和自定义的全局变量以及当前shell自定义变量 export和非export
声明全局变量(子shell也可以用): export myname=Aming
[root@VM~]# export a=1 [root@VM ~]# bash [root@VM~]# echo $a 1 [root@VM ~]# exit
linux下设置自定义变量规则:
(1)格式为 “a=b”, 其中a为变量名,b为变量的内容,等号两边不能有空格;
(2)变量名只能由英文、数字以及下划线组成,而且不能以数字开头;
(3)当变量内容带有特殊字符(如空格)时,需要加上单引号 a='ll abc' ;
(4)如果变量内容中需要用到其他命令运行结果则可以使用反引号 a= `which vim` ; b=`echo $a`;echo $b
(5)变量内容可以累加其他变量的内容,需要加双引号;
//'',"",``的区别 ""有时候会解析结果,要慎用,最好用'' # a='sss' # b='echo $a' # echo $b echo $a # b=`echo $a` # echo $b sss # b="echo $a" # echo $b echo sss
//变量内容累加 b=$a"123" 或者 b=$a'123' c=$a$b echo $c 错误:b=$a123 [root@VM_9_115_centos ~]# c=$a$b [root@VM_9_115_centos ~]# echo $c ssssss123 # b=$a"123" [root@VM_9_115_centos ~]# echo $b sss123 [root@VM_9_115_centos ~]# b=$a'$a' [root@VM_9_115_centos ~]# echo $b sss$a [root@VM_9_115_centos ~]# b=$a"$a" [root@VM_9_115_centos ~]# echo $b ssssss
//变量内容累加 // $( ) 和${ } 和$(( )) 与差在哪 a=sss b=${a}123 echo $b sss123 c=$(wc -l /etc/passwd|awk '{print $1}') echo $c 38 y=$((5+c)) echo $y 43
unset :取消全局变量声明
////取消全局变量声明 # export a='22u' # set | grep '^a' a=22u # env |grep '^a' a=22u # unset a # env |grep '^a' # set | grep '^a'
下半节课
source和. 点使配置文件即时生效: source ~/.bashrc 或者 . ~/.bashrc //注意点后面有空格
系统所有用户使用变量: export myname=Aming 全局变量,加入/etc/profile并source /etc/profile永久生效
系统某个用户使用变量: export myname=Aming 加入当前用户家目录下的 .bashrc中 source .bashrc
export myname=Aming 全局变量,export 不加任何选项表示,声明所有的环境变量以及用户自定义变量
.系统和个人环境变量的配置文件
/etc/profile PATH, USER, LOGNAME, MAIL, INPUTRC, HOSTNAME, HISTSIZE, umask等 ,/etc/profile 包含了/etc/bashrc ,尽量将变量的设置放在/etc/profile里
/etc/bashrc $PS1([root@VM~]#) umask 以后如果设置umask修改放 /etc/profile 不要改这个/etc/bashrc文件
~/.bash_profile 用户自己的环境变量,用户登录的时候执行,tty1,ssh,su - ,不要犯那个腾讯工程师的错误
~/.bashrc 当用户登录以后每次打开新的shell(子shell)时,或者执行bash , 执行该文件
.bash_history 记录命令历史用的
.bash_logout :当退出shell时,会执行该文件。
http://www.apelearn.com/bbs/forum.php?mod=viewthread&tid=909&highlight=%2Fetc%2Fprofile
/etc/profile、/etc/bashrc、~/.bash_profile、~/.bashrc很容易混淆,他们之间有什么区别?它们的作用到底是什么?
/etc/profile: 用来设置系统环境参数,比如$PATH. 这里面的环境变量是对系统内所有用户生效的。
/etc/bashrc: 这个文件设置系统bash shell相关的东西,对系统内所有用户生效。只要用户运行bash命令,那么这里面的东西就在起作用。
~/.bash_profile: 用来设置一些环境变量,功能和/etc/profile 类似,但是这个是针对用户来设定的,也就是说,你在/home/user1/.bash_profile 中设定了环境变量,那么这个环境变量只针对 user1 这个用户生效.
~/.bashrc: 作用类似于/etc/bashrc, 只是针对用户自己而言,不对其他用户生效。
另外/etc/profile中设定的变量(全局)的可以作用于任何用户,而~/.bashrc等中设定的变量(局部)只能继承/etc/profile中的变量,他们是"父子"关系.
~/.bash_profile 是交互式、login 方式进入 bash 运行的,意思是只有用户登录时才会生效。
~/.bashrc 是交互式 non-login 方式进入 bash 运行的(例如用rsync的ssh方式),用户不一定登录,只要以该用户身份运行命令行就会读取该文件。
全局:/etc
用户:~/
shell中的特殊符号
* 匹配符号,零个或多个任意字符
? 匹配符号,1个任意的字符
# 注视说明用的,使后面的内容失去原本的意义
脱义字符,将特殊字符还原为普通字符,用在双引号里面 ,例如 grep 命令和find命令要脱义要用双引号 PS1="[u@h W]\$ "
|将符号前面命令的结果丢给符号后面的命令,一般针对文档操作的命令比较常用,例如cat, less, head, tail, grep, cut, sort, wc, uniq, tee, tr, split, sed, awk等等
$ 引用变量,还有 !$
; 分号,多条命令写一行时,分隔命令
~ 用户家目录 cd ~steven 到steven用户家目录
& 放到命令最后面,让命令在后台运行
让命令在后台运行的两种方法
nohup sleep 10000 & 或者 ctrl+z然后输入bg回车
# nohup sleep 10000 & [1] 19159 [root@VM_9_115_centos ~]# nohup: ignoring input and appending output to `nohup.out' [root@VM_9_115_centos ~]# jobs [1]+ Running nohup sleep 10000 &
常用命令:
1)cut -d 分隔符(不指定默认以空格为分隔符)跟awk一样 -f 区域
语法: cut -d ‘分隔字符’ [-cf] n 这里的n是正整数
-b :以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。
-n :取消分割多字节字符。仅和 -b 标志一起使用
-d 后面指定分隔符,用单引号引起来,-f 指定第几段 -f 1,2 或 -f 1-3: cut -d ':' -f 1 /etc/passwd |head -n 5
-f :与-d一起使用,指定显示哪个区域。
-c 后面只有一个数字表示截取每一行的第几个字符: head -n2 /etc/passwd|cut -c2
-c 后面跟一个数字区域,表示截取每一行从几到几的字符 : head -n2 /etc/passwd|cut -c2-5
cut的缺点,所以通常用awk
cut -d " - [" -f 1 1.log 报错
cut: 分界符必须是单个字符
2)sort
语法: sort [-t 分隔符] [-kn1,n2] [-nru] (n1<n2)
不加选项,从首字符向后,依次按ASCII码值进行升序排序(不管数字还是字母): sort /etc/passwd
-t 后指定分隔符
-kn1,n2表示在指定的区间中排序,-k后面只跟一个数字表示对第n列排序,
-n表示使用纯数字排序 : sort -t: -k3 -n /etc/passwd
-r 表示以降序的形式排序: sort -t: -k3,5 -r /etc/passwd
-u 去重(一般不用,用uniq命令): cut -d ':' -f 4 /etc/passwd |sort -n -u
top 按内存大小排序,从大到小 ,只取前十行 top -bn1|sed -n '7,$'p 1.txt |sort -rn -k6|head -10
3)wc
用于统计文档的行数、字符数、词数
不加任何选项,会显示行数、词数以及字符数
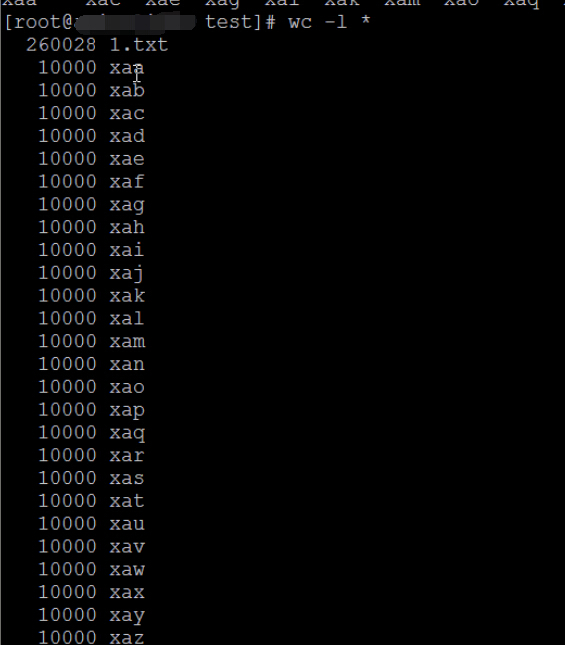
-l 统计行数 : wc -l 2.txt wc -l *.txt 统计多个文件
-m 统计字符数
-w 统计词数
wc命令后面不加文件则统计标准输入的内容,输入完内容之后,按ctrl+d则终止
4)uniq
sort和uniq是兄弟
uniq 去重复,最常用就一个 -c 用来统计重复的行数,去重前要先排序: sort testb.txt |uniq -c
5)tee
后跟文件名,类似于>,比重定向多了一个功能,在把文件写入后面所跟的文件中的同时,还显示在屏幕上
参数
-a或--append 附加到既有文件的后面,而非覆盖它
LAMP_Stack 2>&1 | tee -a /root/lnmp-install.log cat 2.txt |tee 2.log
6)tr 用来替换字符 可以用sed代替
tr -c -d -s ["string1_to_translate_from"] ["string2_to_translate_to"] < input-file
input-file是转换文件名。虽然可以使用其他格式输入,但这种格式最常用。
-c 用字符串1中字符集的补集替换此字符集,要求字符集为ASCII。
-d 删除字符串1中所有输入字符。
-s 删除所有重复出现字符序列,只保留第一个;即将重复出现字符串压缩为一个字符串。
最常用的就是大小写转换: head /etc/passwd |tr '[a-z]' '[A-Z]'
删除Windows文件“造成”的'
换行符 : cat file | tr -s "
" "
" > new_file
用空格符�40替换制表符�11: cat file | tr -s "�11" "�40" > new_file
删除Windows文件“造成”的'
换行符 : cat file | tr -s "
" "
" > new_file
用空格符�40替换制表符�11: cat file | tr -s "�11" "�40" > new_file
tr 替换一个字符也是可以的: cat 1.txt |tr 'r' 'R'
7)split 切割大文件用的 才哥说将数据库100w数据一次过导出到CSV,然后 split ,split为每个文件10w行,之前他split一个50G的日志文件 拉到Linux下面 非常快完成
两种:1、按大小(默认字节) 2、按行
-l : 按行数分隔: split -l 10 2.txt
-b : 按大小来分割,单位为byte: split -b 50 1.txt
切割到某个目录 : split -l 1 22.txt abcdir/
将分割的文件重新合并回去: cat xa* >223.txt
默认会以xaa, xab, …这样的形式定义分隔后的文件名,也可以指定文件名 : split -b 2m 1.txt blog blogaa、blogab、blogac、blogad、blogae
8)paste 将文件的行进行merge
paste [OPTION]… [FILE]…
-d: 指定两个文件的行合并后的分割符
-s: 将每个文件合并为一行,而不是按行进行合并
用法
paste file1 file2 #将两个文件的每行合并
paste -d: file1 file2 #将两个文件的每行合并,分隔符为:
paste -s file1 file2 #将file1的内容合并为一行,将file2的内容合并为一行
# paste xaa xab >11_total.txt
# cat 11_total.txt
2 k 5 dfe ii l 11 l
we 23 d i ll
cut -d 分隔符 -f 区域 sort -n 数字排序 -r 倒序 wc -l 2.txt sort testb.txt |uniq -c cat 2.txt |tee 2.log ls 2.txt |tr 't' 'T' split -l 10 2.txt
paste xaa xab >11_total.tx
cut -d ':' -f 1 /etc/passwd |sort |uniq -c |wc -l
批量文件名替换
ls blog*|xargs -i mv {} {}.txt
&& 和 ||和;
&& 和 ||都有逻辑关系
command1 ; command2 前面命令是否执行完成都会执行后面命令
command1 && command2 只有前面命令执行成功才会执行后面命令
command1 || command2 只有前面命令不成功再去执行后面命令
http://www.cnblogs.com/hnrainll/archive/2011/07/04/2097408.html
使用nohup命令:
nohup描述:Run COMMAND, ignoring hangup signals.(忽略任何中断/挂起信号,使命令继续执行)
但是当你尝试使用命令:
1
nohup command
时候却会遇到不大不小的麻烦……
delectate@delectate:~$ nohup vlc
nohup: ignoring input and appending output to `nohup.out'
是的,虽然它自动把debug信息记录到nohup.out文件,但是你却无法使用这个终端进行任何操作。
所以你需要和第一个方法混用,即
nohup command {option} &
混用后,它会自动把你执行的命令输出结果记录到权限为-rw——-(600),名为nohup.out的文件中。
但是你仍然需要
delectate@delectate:~$ nohup vlc &
[1] 9045
delectate@delectate:~$ nohup: ignoring input and appending output to `nohup.out'
//在这里按一下回车或以ctrl+C 以show a clean terminal
delectate@delectate:~$
与使用 “&” 性质相同,当前启动程序的终端如果没有被关闭,已经启动的程序附在pst上;如果终端被关闭,则自动附在tty。
如果当前目录的 nohup.out 文件不可写,输出重定向到 $HOME/nohup.out。默认状态下,nohup默认输出到nohup.out文件,你也可以利用重定向来指定输出文件:
nohup command {option} > myout.file 2>&1 &
只有当虚拟终端是 $ 或者 # 时候,才可以关闭此终端,否则可能导致已经启动的进程被关闭(按enter——如果程序持续输出信息而没有出现 $ 或 #)
cat > 2.txt <<EOF和echo的区别,实际上没有区别
echo -e '66
77
99
' >2.txt
cat 2.txt
66
77
99
有什么区别,而且我echo可以追加,EOF不行
[root@steven ~]# cat > 2.txt <<EOF
> 12
> 23
> 45
> 67
> 88
> EOF
[root@steven ~]# cat 2.txt
12
23
45
67
88
EOF也可以换成其他字符,例如A
> 1
> 2
> eof
-bash: 1.txt: command not found
ls <<eof
> 1
> 2
> eof
[root@banking tmp]# cd /tmp
[root@banking tmp]# ./ceshi.sh
2、绝对路径方式
[root@banking tmp]# /tmp/ceshi.sh
3、bash命令调用 使用所用脚本语言 比如 expect xx.expect python xx.py sh xx.sh bash xx.sh
[root@banking /]# bash /tmp/ceshi.sh
4、. (空格) 相对或绝对路径方式
[root@banking /]# . /tmp/ceshi.sh
一般用第三种和第四种
第一、二、三种需要赋予脚本执行权限
第一、二、三种都是开子shell,第四种在当前shell,注意环境变量继承
b=${a}123
echo $b
sss123
c=$(wc -l /etc/passwd|awk '{print $1}')
echo $c
38
y=$((5+c))
echo $y
43
$( ) 和${ } 和$(( )) 与差在哪 http://blog.chinaunix.net/uid-12380499-id-105461.html
2.8.2 环境变量
当登录系统后,你才有资格通过shell与Linux沟通。这时候shell启动,并从启动它的/bin/login程序中继承了多个变量、I/O流和进程特征。如果遇到需要后台处理、执行整组命令以及脚本的情况,父shell也会派生子shell应付这些工作,子shell从父亲那里继承环境。这里的环境包括进程的权限、工作目录、文件创建掩码、特殊变量、打开的文件和信号。变量包括局部变量和环境变量。局部变量是私有的,无法传递给子shell。与之相反,环境变量可由父shell传递给子shell,子shell传递给孙shell……子子孙孙,无穷尽也。
所谓的读入系统的环境变量包括PATH、HOME、LOGNAME、IFS和SHELL 等等,为了区别与自定义变量的不同,环境变量通常以大写字符来表示。可以通过set、env和export设置环境变量,使用unset命令来清除设置,使用readonly来设置只读属性。
请看例子:
export ENVTEST= "ENV1"
env | grep ENVTEST
结果:
ENVTEST= ENV1
unset $ENVTEST
env | grep $ENVTEST
结果?
2.8.3 bash的配置文件 登录shell和非登录shell
前面讲了在输入登录用户名和密码后shell才启动,这是login shell。还有一种non-login shell,不需要做重复的登录操作获取bash界面。例如在x-window环境下来启动终端,测试终端界面不需要再次输入账户与密码,这个bash环境就是non-login shell。login和non-login有什么区别呢?那得先从bash的配置文件说起。
1. 系统设置文件
只有login shell才会读取系统设置文件/etc/profile。它是系统整体的配置文件,该配置文件里包含很多重要的变量信息,每个用户登录取得bash后一定会读取这个配置文件。如果你想要所设置的环境变量对所有用户起作用,就要在这个地方设置。该文件主要有以下设置变量:
#PATH:会根据UID决定PATH变量要不要含有sbin的系统指令目录;
pathmunge () {
if !echo $PATH | /bin/egrep -q "(^|:)$1($|:)" ; then
if [ "$2" = "after" ] ; then
PATH=$PATH:$1
else
PATH=$1:$PATH
fi
fi
}
……
#USER:根据用户的账号设置此变量内容;
USER="`id -un`"
LOGNAME=$USER
#MAIL:根据账户设置/var/spool/mail/账号名称;
MAIL="/var/spool/mail/$USER"
#依据主机的hostname指令设置此变量的内容;
HOSTNAME=`/bin/hostname`
HISTSIZE=2000
#HISTSIZE:历史命令记录数。
HISTTIMEFORMAT='[%F %T] '
除了完成以上设置,/etc/profile还会调用如下的外部设置文件:
/etc/inputrc:用来设置bash的热键、[Tab]是否有声音等信息。
/etc/profile.d/*.sh:这个目录下的文件规定了bash的操作界面、语系以及一些公共的命令别名。
/etc/sysconfig/i18n:这个文件是供/etc/profile.d/lang.sh调用,决定bash默认使用何种语系。centos7是 /etc/locale.conf
grep i18n lang.sh # /etc/profile.d/lang.sh - set i18n stuff [ -f "$HOME/.i18n" ] && . "$HOME/.i18n" && sourced=1 for langfile in /etc/sysconfig/i18n "$HOME/.i18n" ; do
2. 用户的个性设置文件
login shell读完了/etc/profile配置文件后,接下来就会读取用户的个人配置文件。个人配置文件主要有三个隐藏文件,依次是:~/.bash_profile 、/.bash_login 和 ~/.profile。如果~/.bash_profile存在,那么bash就不会理睬其他两个文件。如果~/.bash_profile不存在,bash才会读取~/.bash_login。而前两个文件都不存在的话,bash才会读取~/.profile文件。个人设置文件主要是获取与用户有关的环境、别名和函数等。如果~/.bashrc存在的话,~/.bash_profile还会调用它,所以你可以把你的一些环境设置写到~/.bashrc这个文件中。在用户目录下,还有两个个人文件~/.bash_history和~/.bash_logout。默认情况下,历史命令就记录在bash_history中。每次登录bash后,bash读取这个文件,将所有的历史命令读入内存。 ~/.bash_logout告诉系统在离开“我”之前需要帮“我”做什么。默认情况下,该文件只让bash清掉屏幕的消息。你可以添加一些信息到在这个文件中,例如备份要求等。
3. 用户的通用设置
系统层的函数、别名和环境等设置一般在/etc/profile。但是对于非交互的non-login shell,我们也希望通过~./bashrc做一些的设置。如果/etc/bashrc存在的话,它会被~./bashrc调用。它的主要工作有:
(1)依据不同的UID给出umask值
(2)依据不同的UID给出PS1变量
(3)调用/etc/profile.d/*.sh的设置
图2.7和图2.8分别展示了login shell和non login shell的整个配置文件处理流程:
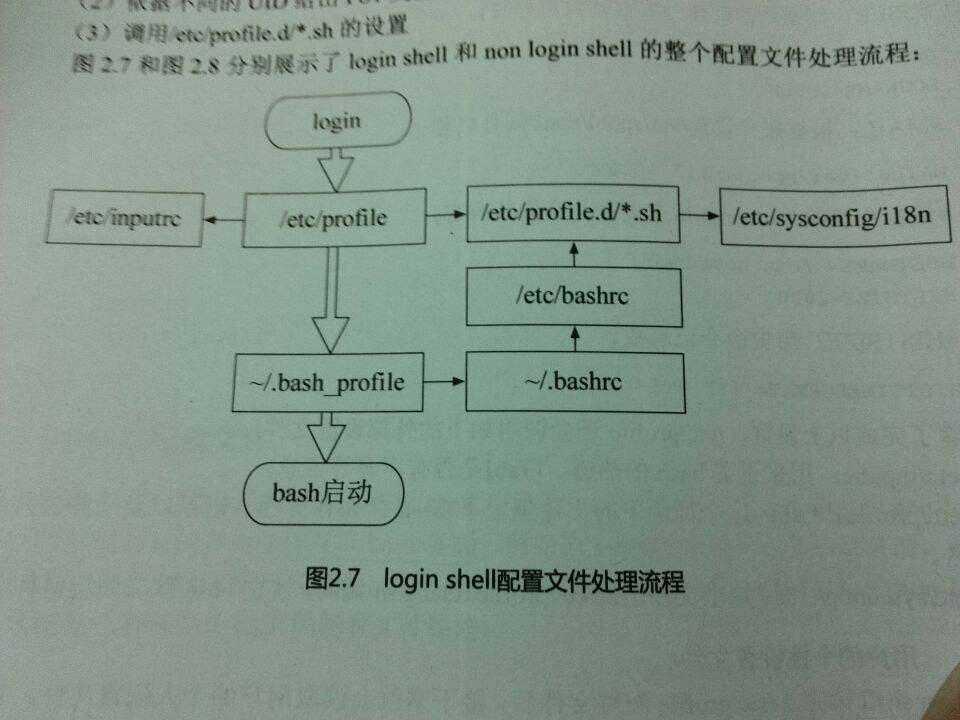
图2.7 login shell配置文件处理流程
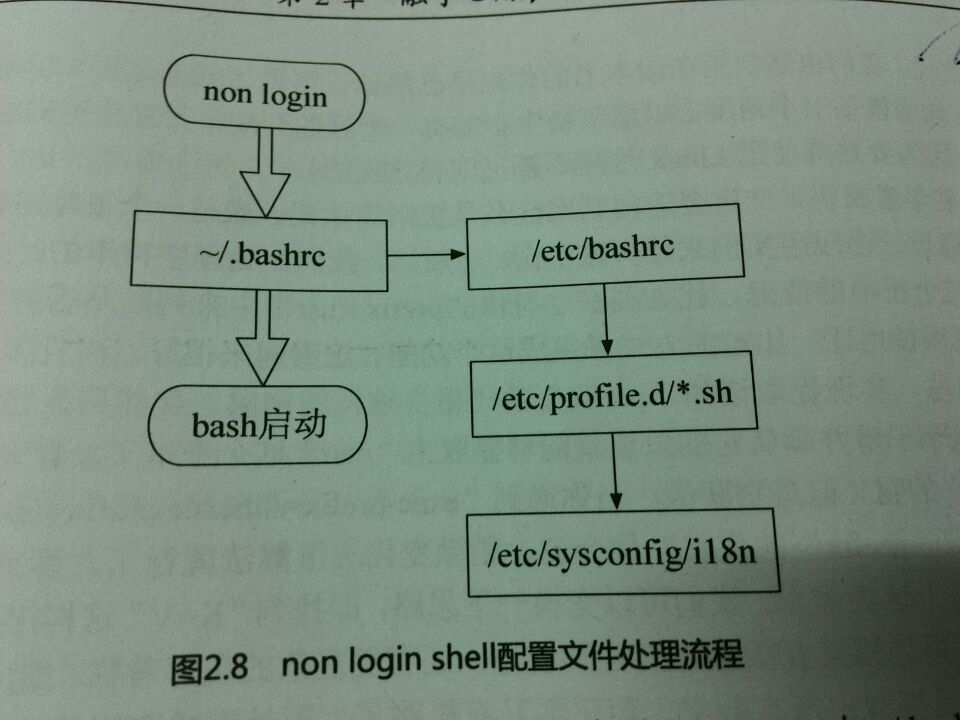
图2.8 non login shell配置文件处理流程
个人需要的设置写在“~./bashrc”文件中即可。由于/etc/profile与~/.bash_profile都是在取得login shell的时候才会读取配置文件,所以修改这两个文件中的设置后,需要再登录相应的配置才能生效。其他的配置可以通过source命令将配置文件的内容读入当前shell环境中。
http://timber.blog.51cto.com/7677013/1745550

2>&1
> include ld.so.conf.d/*.conf
> /usr/local/lib
> EOF
cat >> /etc/sysctl.conf <<eof
> net.ipv4.tcp_max_tw_buckets = 6000
> net.ipv4.ip_local_port_range = 1024 65
> eof
追加重定向
http://www.cnblogs.com/itech/archive/0001/01/01/1525590.html
1)command 2>errfile : command的错误重定向到文件errfile。
2)command 2>&1 | ...: command的错误重定向到标准输出,错误和标准输出都通过管道传给下个命令。
ls /ett 2>&1 | tee -a /tmp/23.txt
ls: cannot access /ett: No such file or directory
[root@testtest ~]# cat /tmp/23.txt
ls: cannot access /ett: No such file or directory
3)var=`command 2>&1`: command的错误重定向到标准输出,错误和标准输出都赋值给var。
var=`ls /ettt 2>&1`
[root@testtest ~]# echo $var
ls: cannot access /ettt: No such file or directory
4)command 3>&2 2>&1 1>&3 | ...:实现标准输出和错误输出的交换。
5)var=`command 3>&2 2>&1 1>&3`:实现标准输出和错误输出的交换。
6)command 2>&1 1>&2 | ... (wrong...) :这个不能实现标准输出和错误输出的交换。因为shell从左到右执行命令,当执行完2>&1后,错误输出已经和标准输出一样的,再执行1>&2也没有意义。
三 "2>&1 file"和 "> file 2>&1"区别
1)cat food 2>&1 >file :错误输出到终端,标准输出被重定向到文件file。
2)cat food >file 2>&1 :标准输出被重定向到文件file,然后错误输出也重定向到和标准输出一样,所以也错误输出到文件file。
cat food 2>&1 >file
cat: food: No such file or directory
[root@testtest ~]# cat food >file 2>&1
[root@testtest ~]#