centos 正则,grep,egrep,流式编辑器 sed,awk -F 多个分隔符 通配符 特殊符号. * + ? 总结 问加星 cat -n nl 输出文件内容并加上行号 alias放~/.bash_profile 2015-4-10 第十三节课
第一节课
grep
. * + ? 特殊符号总结 问加星
egrep
第二节课
sed
第三节课
awk
nl命令和cat -n
grep命令只支持基本正则!
通配符glob模式和正则不一样,例如 find命令 只能使用通配符,grep命令用的是正则!
正则就是有一定规律的字符串,有几个特殊符号很关键(. ? + * | ),我们平时不仅可以用命令行工具grep/sed/awk去引用正则,
而且还可以把正则嵌入在nginx、apache、甚至php、python编程语言当中
正则表达式
单词边界
锚定 ^开始 $结束
分块 ()
逻辑或 |
范围(字符集) 任何字符 范围内[] 范围外[^]
数量 固定个数 {4} 范围{4,6}
重复(贪婪性和惰性) ? 0-1 + 1-无穷 * 0-无穷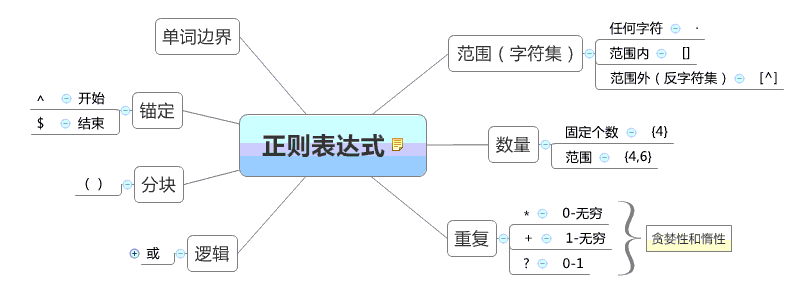
-----------------------------------------------
常用正则
. 点: 匹配除换行符以外的任意字符
? 问号: 重复0次或1次 ,? 等价于 {0,1}
+ 加号: 重复1次或更多次 ,+ 等价于 {1,}
* 星号: 重复0次或更多次 ,* 等价于 {0,}
d :匹配数字
^ : 匹配字符串的开始
$ : 匹配字符串的结尾
{n} : 重复n次
{n,} : 重复n次或更多次
[c] : 匹配单个字符c
[a-z] : 匹配a-z小写字母的任意一个
$1 : 表示正则捕捉到的内容
^/(.*)$ 中 ^/ 表示已 / 开头,.表示匹配除换行符以外的任意字符,*表示重复0次或更多次,$ 表示匹配字符串的结束,() 表示捕获(匹配)内容
小括号()之间匹配的内容,可以在后面通过$1来引用,$2表示的是前面第二个()里的内容 sed 123 分段
. 转义字符
+ 匹配除换行符以外的任意字符
以下字符在匹配其本身时,通常需要进行转义。在实际应用中,根据具体情况,需要转义的字符可能不止如下所列字符
. $ ^ { [ ( | ) * + ?
--------------------------------------------------------------------------------------------------------------------------
一、grep
1. 语法+选项
语法: grep [-cinvABC] 'word' filename
-w :全字匹配
-i :忽略大小写
-c :打印符合要求的行数
-n :在输出符合要求的行的同时连同行号一起输出
-v :打印不符合要求的行 取反
-A :后跟一个数字(有无空格都可以),例如 –A2则表示打印符合要求的行以及下面两行
-B :后跟一个数字,例如 –B2 则表示打印符合要求的行以及上面两行
-C :后跟一个数字,例如 –C2 则表示打印符合要求的行以及上下各两行
-q:不显示匹配到行,常用在shell脚本里, if echo $n|grep -q '[^0-9]';then xx
-r : 会把目录下面所有的文件全部遍历
-o : 统计出现次数,结合wc -l
-E : 自动转义 相当于egrep
--color:颜色 做个别名 alias grep='grep --color'
include=PATTERN:仅在搜索匹配 PATTERN 的文件时在目录中递归搜索 要配合-r选项,在当前目录中搜索有abc.com关键字的php文件 grep -r --include="*.php" 'abc.com' *
exclude=PATTERN:在目录中递归搜索,但是跳过匹配 PATTERN 的文件 grep -r --exclude="*.php" 'abc.com' *
将alias grep='grep --color' 放到自己家目录vim ~/.bash_profile 或 /etc/bash_profile
放在/etc/rc.local是不对的!
grep -v '^[0-9]' 2.txt 不等价 grep '^[^0-9]' 2.txt ^[^0-9]不是数字开头的 ^[0-9]数字开头的
grep '^[^0-9]' 2.txt不包含空格开头 ^$
2. 例子介绍
过滤出带有某个关键词的行并输出行号 grep -n 'root' 1.txt
过滤出不带有某个关键词的行并输出行号 grep -n -v 'root' 1.txt
过滤出所有包含数字的行 grep '[0-9]' 1.txt
过滤出所有不包含数字的行 grep -v '[0-9]' 1.txt
去除所有以'#'开头的行 grep -v '^#' 1.txt
去除所有不是以'n'结尾的行 grep -v 'n$' 1.txt
去除所有空行和以'#'开头的行 grep -v '^$' 1.txt|grep -v '^#'
过滤出以英文字母开头的行 grep '^[a-zA-Z]' 1.txt
过滤出含有root或者有xp的行 grep -E 'root|xp' 1.txt ; grep -E 'ClientAliveCountMax|ClientAliveInterval' /etc/ssh/sshd_config
过滤出含有root并且有xp的行 grep 'root' 1.txt | grep 'xp'
过滤出以非数字开头的行 grep '^[^0-9]' 1.txt !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
过滤任意一个或多个字符
grep 'ro*t' 1.txt(0个或多个o);
grep 'ro.t' 1.txt;(1个任意字符 包括空格);
grep -E 'ro?t' 1.txt;(0个或1个任意字符 );
grep 'r.*t' 1.txt(rt之间可以包括任意多个字符);
? 表示零个或一个
. 表示任意一个字符;
*表示零个或多个前面的字符 ;
.*表示零个或多个任意字符,空行也包含在内
指定过滤字符次数 grep 'o{2}' 1.txt
. ? + * 特殊符号总结
. 表示任意一个字符(包括特殊字符 例如空格. * ?)
* 表示零个或多个 *前面/后面的字符
.* 表示任意个任意字符(包含空行)
+ 表示1个或多个 +前面/后面的字符
? 表示0个或1个 ?前面/后面的字符
其中,+ ? grep不支持 加-E 才支持,egrep才支持。
* + ?都需要在前面/后面跟一个字符,否则无意义!
egrep
egrep工具 是grep工具的扩展
表示1个或1个以上前面字符: egrep 'o+' 1.txt
表示0个或者1个前面字符: egrep 'o?' 1.txt
匹配roo或者匹配body: egrep 'roo|body' 1.txt
用括号表示一个整体: egrep 'r(oo)|(at)o' 1.txt
表示1个或者多个 'oo': egrep '(oo)+' 1.txt
表示出现一次或两次 'oo' 用花括号: egrep '(oo){1,2}' 1.txt

第二节课
二、sed
注意:p写在单引号里面和单引号外面都可以!
[root@steven ~]# sed '10'p -n /etc/passwd uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin [root@steven ~]# sed '10p' -n /etc/passwd uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
d写在单引号里面和单引号外面都可以!
root@steven ~]# sed '1,30'd /etc/passwd user1:x:502:502::/home/user1:/bin/bash xp:x:503:503::/home/xp:/bin/bash wrg:x:504:504::/home/wrg:/bin/bash lct:x:505:505::/home/lct:/bin/bash apache:x:48:48:Apache:/var/www:/sbin/nologin hua:x:506:506::/home/hua:/bin/bash user3:x:507:507::/home/user3:/bin/bash user4:x:508:508::/home/user4:/bin/bash [root@steven ~]# sed '1,30d' /etc/passwd user1:x:502:502::/home/user1:/bin/bash xp:x:503:503::/home/xp:/bin/bash wrg:x:504:504::/home/wrg:/bin/bash lct:x:505:505::/home/lct:/bin/bash apache:x:48:48:Apache:/var/www:/sbin/nologin hua:x:506:506::/home/hua:/bin/bash user3:x:507:507::/home/user3:/bin/bash user4:x:508:508::/home/user4:/bin/bash
sed (用在 查找/替换 's///g' 和 删除 d -i , 如果单纯只是查找 完全可以用grep代替 ,sed无法用颜色标记)
p:print 打印,-n:只打印特定行 -n和p连用: sed '1,4'p -n 1.txt; sed '5,$'p -n 1.txt
d:退出sed,打印完第3行,退出sed: sed '3q' test.txt
sed -n '1p' file
sed -n '1p;1q' file
他们的作用一样,都是获取文件的第一行。但是第一条命令会读取整个文件,而第二条命令只读取第一行。当文件很大的时候,仅仅是这样一条命令不一样就会造成巨大的效率差异。
当然,这里只是为了举一个例子,这个例子真正正确的用法应该是使用head -n1 file命令。。。
打印包含某个字符串的行,可以使用 ^ . * $等特殊符号 sed -n '/ro*t/'p 1.txt ;o,|,t 三选一 没有特别意思 sed -r -n '/ro[o|t]/p' 1.txt
脱义 -r: sed -r -n '/ro?t/'p 1.txt
root或者mysql: sed -r -n '/root|mysql/p' 1.txt
-e 可以实现同时进行多个任务 并且,就像传送带: sed -e '/root/p' -e '/body/p' -n 1.txt 也可以用;实现 sed '/root/p; /body/p' -n 1.txt
删除行 : sed '/root/d' 1.txt ; sed '1d' 1.txt ; sed '10,$d' 1.txt
替换,其中s就是替换的意思,g为全局替换,否则只替换第一次的,/也可以为 #, @ 等: sed '1,2s/ot/to/g' 1.txt ; sed '1,$s/ot/to/g' 1.txt 等价于 sed 's/ot/to/g' 1.txt
大小写替换: 大写 sed -i 's/[a-z]/u&/g' 1.txt ;小写 sed -i 's/[a-z]/l&/g' 1.txt
删除所有数字: sed 's/[0-9]//g' 1.txt
删除所有非数字: sed 's/[^0-9]//g' 1.txt
1 代表第一个括号
调换两个字符串位置,123 分段,可以用aa:bb:cc做一下练习 : head -n2 1.txt |sed 's/(root)(.*)(bash)/321/'
在文件中某一行例如root行最后添加一个数字 sed -r 's/(^root.*)/1 12/' /etc/passwd 1表示(^a.*)
或者去除某个分段: echo aaa_bbb_ccc_01_022615.trig_02262015|sed "s/(aaa)(.*)($n)/12/"
直接修改文件内容 : sed -i 's/ot/to/g' 1.txt
替换多次: sed 's/ / /g; s/-1/0/g' aa.txt
查找之后再替换: 等价于 grep -Ei 'tty[2-6]' 22.txt|sed 's/^/#/'
sed -i '/tty[2-6]/s/^/#/' 22.txt sdf 12 oioioioo sd 12 #sdtty3lklk 12 #sdftty2sdf 13
跟vim的末行模式替换是一样的 :6,10s/iptables/IP/g 等同于 sed -i '6,10s/iptables/IP/g' 22.txt
替换的时候顺便进行备份 -i.bak : sed -i.bak 's/enabled/disabled/' /etc/selinux/config
修改selinux为disabled: sed -i 's/enabled/disabled/' /etc/selinux/config

sed练习题:
把/etc/passwd 复制到/root/test.txt,用sed打印所有行
打印test.txt的3到10行
打印test.txt 中包含 'root' 的行
删除test.txt 的15行以及以后所有行
删除test.txt中包含 'bash' 的行
替换test.txt 中 'root' 为 'toor'
替换test.txt中 '/sbin/nologin' 为 '/bin/login'
删除test.txt中5到10行中所有的数字
删除test.txt 中所有特殊字符(除了数字以及大小写字母)
把test.txt中第一个单词和最后一个单词调换位置
把test.txt中出现的第一个数字和最后一个单词替换位置
把test.txt 中第一个数字移动到行末尾
在test.txt 20行到末行最前面加注释 '#',& 表示的是要被替换的部分 : sed '20,$s/.*/#&/' test.txt
在test.txt 的每行后面加空格 aab,&表示被替换的部分 : sed 's/.*/& aab/' test.txt
比如大小写替换:大小写替换: 大写 sed -i 's/[a-z]/u&/g' 1.txt ;小写 sed -i 's/[a-z]/l&/g' 1.txt
使用sed 过滤一段时间范围内的nginx日志
sed -n '/01/Mar/2016:20:52/,/01/Mar/2016:21:14:2/'p www.log |wc -l
在/etc/passwd文件中在以第一个mail开头的行到以一个ftp开头的行的后面添加abc,并在abc前面加一个空格
sed '/^www>/,/^www1>/s/$/ abc/' /etc/passwd
提取table-name
xxxx table-name="tbname"> xxxx
sed -r 's/.*table-name="(.*)".*/1/g' file
sed -i 's#BASEDIR=/usr/local#&/zabbix#' /etc/init.d/zabbix_agentd
结果是BASEDIR=/usr/local/zabbix
4.删除前一时期的日志除了最后一个
第三节课
三、awk
(不需要加-E -r 就支持特殊符号? + ())
如果不是只打印某几个字段可以不用加{print $1,$3}
NR: number row 第几行
NF: number field 第几段/列
-F 分隔符(不指定默认以空格为分隔符)跟cut一样,可以多个分隔符 df -h |awk -F '[ %]+' '{print $5}'
截取文档中的某段,分隔符: 截取第一段: awk -F ':' '{print $1}' 1.txt
也可以使用自定义字符连接每个段,自定义显示的分隔符:
awk -F':' '{print $1":"$2":"$3":"$4}' /etc/passwd awk -F':' '{OFS =";" ; print $1,$2,$3,$4}' /etc/passwd awk -F':' 'OFS =";"{ print $1,$2,$3,$4}' /etc/passwd
匹配字符或字符串 : awk '/oo/' 1.txt
针对某个段/列匹配: awk -F ':' '$1 ~/oo/' 1.txt
多次模糊匹配,并且: awk -F ':' '/root/ {print $1,$3} && $1 ~/test/; $3 ~/20/' 1.txt ; awk '/123/ || /abc/ {print}' 11.txt ; awk '/123|abc/ {print}' 11.txt
多次精确匹配,或者: awk -F ':' ' $1=="test" || $3==20 {print $1,$3}' 1.txt
不等于,不等于#开头的 并且第二列是/开头的: awk '!/^#/ && $2 ~ /^// { print $2 }' /etc/fstab
条件操作符==, >,<,!=,>=;<=
awk -F ':' '$3=="0"' 1.txt awk -F ':' '$3>="500"' 1.txt awk -F ':' '$7!="/sbin/nologin"' 1.txt awk -F ':' '$3<$4' 1.txt awk -F ':' '$3>"5" && $3<"7"' 1.txt awk -F ':' ' NR>2 && NR<8' 1.txt awk -F ':' '$3>"5" || $7=="/bin/bash"' 1.txt awk -F ':' '$7 !~ "/bin/bash"' 1.txt 注意:字符串比较,下面两句的结果是不一样的,如果是数字没有必要加"" awk -F ':' '$3 >= 500' /etc/passwd > 1.txt #过滤大于等于500的行重定向到1.txt awk -F ':' '$3 >= "500"' /etc/passwd > 1.txt #一行都过滤不了整个/etc/passwd 文件重定向到1.txt
awk内置变量 NF(段数) NR(行数)
head -n3 1.txt | awk -F ':' '{print NF}' head -n3 1.txt | awk -F ':' '{print $NF}' head -n3 1.txt | awk -F ':' '{print NR}'
打印20行以后的行 awk 'NR>20' 1.txt
awk -F ':' 'NR>20 && $1 ~ /ssh/' 1.txt
更改某个段的值: awk -F ':' '$1="root"' 1.txt
只打印最后一列和倒数第二列: awk -F ':' '{print $(NF-1) ":" $(NF)}' /etc/passwd
数学计算, 把第三段和第四段值相加,并赋予第七段 ,$0表示原来整行: awk -F ':' '{$7=$3+$4; print $0}' 1.txt
计算第三段的总和,随便你用什么变量名,total,sum,count都可以: awk -F ':' '{(tot=tot+$3)}; END {print tot}' 1.txt 或者 awk -F ':' '{(sum=sum+$3)}; END {print sum}' 1.txt
相加只能是数字相加,如果是其他字符,awk看作是0

awk中也可以使用if关键词 : awk -F ':' '{if ($1=="root") print $0}' 1.txt
//关于print输出 下面三种写法等价 都是打印整行 awk -F':' '/root/' 1.txt awk -F':' '/root/ {print}' 1.txt awk -F':' '/root/ {print $0}' 1.txt # awk -F':' '/root/' 1.txt root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin # awk -F':' '/root/ {print}' 1.txt root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin # awk -F':' '/root/ {print $0}' 1.txt root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin
awk的脱衣字符
awk '{print "This is a '"'"' " $1}' filename
解释一下:在awk中使用脱义字符是起不到作用的,如果想打印特殊字符,只能使用'""' 这样的组合才可以。
这里自左至右为单引号 双引号 双引号 单引号其中两个单引号为一对,两个双引号为一对。想脱义$那就是'"$"' 脱义单引号那就是 '"'"'
awk的printf
awk -F':' '{printf """ $1 "", "}' /etc/passwd
printf:用printf不用print
""":左边加引号,要用软银行
"",
":右边加引号,然后再加逗号和换行
awk -F':' '{printf """ $1 "", "}' /etc/passwd "root", "bin", "daemon", "adm", "lp", "sync", "shutdown", "halt", "mail",
awk练习题
用awk 打印整个test.txt (以下操作都是用awk工具实现,针对test.txt)
查找所有包含 'bash' 的行
用 ':' 作为分隔符,查找第三段等于0的行
用 ':' 作为分隔符,查找第一段为 'root' 的行,并把该段的 'root' 换成 'toor' (可以连同sed一起使用)
用 ':' 作为分隔符,打印最后一段/列,最后一段$NF: awk -F ':' '{print $NF}' 1.txt
打印行数大于20的所有行
用 ':' 作为分隔符,打印所有第三段小于第四段的行
用 ':' 作为分隔符,打印第一段以及最后一段,并且中间用 '@' 连接 (例如,第一行应该是这样的形式 'root@/bin/bash' )
用 ':' 作为分隔符,把整个文档的第四段相加,求和
nl命令和cat -n
nl 输出文件内容并加上行号
# nl /etc/passwd
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
# cat -n /etc/passwd
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
nl命令和cat -n的区别
cat -n 计入空行 总行数
170 Add_LAMP_Startup
171 Check_LAMP_Install
172 }
173
174 case "${Stack}" in
175 lnmp)
nl 不计空行 看不到总行数
160 Check_LAMP_Install
161 }
162 case "${Stack}" in
163 lnmp)
164 Dispaly_Selection
对于特殊字符文件的处理
1用notepad++打开
2在Linux里vi一个txt文件
3拷贝notepad++里的东西进去Linux的txt文件
4进行分析 awk
http://files.cnblogs.com/files/MYSQLZOUQI/67676767676Operations.rar
深圳wms问题 Bas_ContainerDetail表
awk '/Bas_ContainerDetail/ {print $0}' 67.txt |wc -l
115
安装dos2unix/unixtodos
http://www.cnblogs.com/younes/archive/2010/06/05/1752123.html
yum list| grep -i dos2unix yum install -y dos2unix # dos2unix 67676767676Operations.dat dos2unix: converting file 67676767676Operations.dat to UNIX format ...
sed详细
https://mp.weixin.qq.com/s?__biz=MjM5ODYxMDA5OQ==&mid=403340380&idx=1&sn=9b4ced5a19f60b0cebf6fd582f1d52ae&scene=0&key=41ecb04b051110036a3bc979f4be9736f08a28851b7035dd196f076719f3a89c6e884c20f05ea4a703ce97d2ca201162&ascene=7&uin=MTY5MDMyNDgw&devicetype=android-19&version=26030848&nettype=cmnet&pass_ticket=6vknOqRs9nBpbpfDm5E%2Fs2vOrFfpxg26f0e0iurNfU8%3D
http://www.cnblogs.com/dong008259/archive/2011/12/07/2279897.html
sed是一个很好的文件处理工具,本身是一个管道命令,主要是以行为单位进行处理,可以将数据行进行替换、删除、新增、选取等特定工作,下面先了解一下sed的用法
sed命令行格式为:
sed [-nefri] ‘command’ 输入文本
常用选项:
-n∶使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN的资料一般都会被列出到萤幕上。但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来。
-e∶直接在指令列模式上进行 sed 的动作编辑;
-f∶直接将 sed 的动作写在一个档案内, -f filename 则可以执行 filename 内的sed 动作;
-r∶sed 的动作支援的是延伸型正规表示法的语法。(预设是基础正规表示法语法)
-i∶直接修改读取的档案内容,而不是由萤幕输出。
常用命令 58同城沈剑:
a ∶新增, a 的后面可以接字串,而这些字串会在新的一行出现(当前行的下一行)~ sed '/gggg/a999' sed.txt
i ∶插入, i 的后面可以接字串,而这些字串会在新的一行出现(当前行的上一行); sed '/gggg/i999' sed.txt
: 插入,跟i 有区别 sed -i '1s/^/firstline
/' 33.txt
c ∶取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
d ∶删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
p ∶列印,亦即将某个选择的资料印出。通常 p 会与参数 sed -n 一起运作~
s ∶取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦!
元字符集
^:匹配一行的开始
$:匹配一行的结束
.:匹配某个字符
[abc]:匹配指定范围字符
sed -i 's/^; extension_dir = "./"/extension_dir = /usr/local/php/lib/php/extensions/no-debug-non-zts-20090626/' /usr/local/etc/php.ini #找到第一行之后就不继续找
sed -i '/^[mysqld]$/adatadir = /data/mysql' /etc/my.cnf (http://www.cnblogs.com/MYSQLZOUQI/p/5164877.html lanmp一键安装脚本)
sed -i '8c\nextension = "memcache.so"
' /usr/local/etc/php.ini
sed -i '8c\nextension = "mssql.so"' /usr/local/etc/php.ini
sed -i '49c\n* soft nofile 65535
' /etc/security/limits.conf
sed -i '51c* hard nofile 65535
' /etc/security/limits.conf
sed -i '/skip-external-locking/iinnodb=OFF ignore-builtin-innodb skip-innodb default-storage-engine=MyISAM default-tmp-storage-engine=MyISAM' /etc/my.cnf
sed -i '$aaaaaaaaaa' /tmp/test.txt 在文件的末尾添加aaaaaaaaa
1、将#^; extension_dir = "./" 替换成extension_dir = /usr/local/php/lib/php/extensions/no-debug-non-zts-20090626/
2、在7行回车后,原来的第7行变成第八行,在原来的第7行插入extension = "memcache.so"后在回车一行
3、在7行回车后,原来的第7行变成第八行,在原来的第7行插入extension = "mssql.so"
4、在49行回车后,原来的第49行变成第50行再回车了,在原来的第49行插入* soft nofile 65535后在回车一行
5、在51行不回车和在上一行只回车一次,原来的第51行变成第52行再回车,在原来的第51行插入* hard nofile 65535后在回车一行
因为有-i参数,所以全部是即时生效
先sed出来验证一下,再加-i 选项
awk详解 Linux就这个范儿
awk拥有下面5个功能
注释
字符串函数
数值函数
变量
行为语句
现在的Linux发行版所附带的awk实际上很新,是GNU的重写版本,也叫GNU awk,程序名是gawk
awk微型语言的解释器是awk命令,在Linux中awk实际上是gawk的一个符号链接,为了兼容性,请在任何时候都使用awk这个命令
file $(which awk)
/bin/awk: symbolic link to `gawk'
ll /bin/awk
lrwxrwxrwx. 1 root root 4 Jul 10 2015 /bin/awk -> gawk
Linux就这个范儿
awk核心思想是pattern/action 对,也叫模式驱动编程。
行为的print命令就是select子句
模式一般是正则表达式或关系式
行为对模式匹配到的记录的处理方法,使用大括号{ }
可以缺少模式也可以缺少行为,但不能同时缺少两者
跟通用脚本语言一样,awk也有注释,就是#号
内置的字符串函数
|
gsub(r,s)
|
在整个$0中用s代替r
|
|
gsub(r,s,t)
|
在整个t中用s替代r
|
|
index(s,t)
|
返回s中字符串t的第一位置
|
|
length(s)
|
返回s长度
|
|
match(s,r)
|
测试s是否包含匹配r的字符串
|
|
split(s,a,fs)
|
在fs上将s分成序列a
|
|
sprint(fmt,exp)
|
返回经fmt格式化后的exp
|
|
sub(r,s)
|
用$0中最左边最长的子串代替s
|
|
substr(s,p)
|
返回字符串s中从p开始的后缀部分
|
|
substr(s,p,n)
|
返回字符串s中从p开始长度为n的后缀部分
|
awk内置变量
AWK的变量分两种:
1、保存单一值的变量叫标量
2、 保存多个值的变量叫数组,数组在awk中实际上是一个HASH表
awk的变量是区分大小写的
| ARGC | 命令行参数个数,是一个标量 |
| ARGV | 命令行参数排列,是一个数组,用于记录每个实际的参数,索引从0开始 |
| ENVIRON | 支持系统环境变量的使用,是一个数组 |
| FILENAME | 当前输入文件名,如果来自标准输入则为空 |
| FNR | 浏览文件的记录数 |
| FS | 设置输入域分隔符,等价于命令行 -F选项 |
| NF | 字段的个数 |
| NR | 已读的记录数 |
| OFS | 输出域分隔符 |
| ORS | 输出记录分隔符 |
| RS | 控制记录分隔符 |
| $1 、$2 、$3 。。。。$n | 行字段,最大是NF |
| $0 | 当前行内容 |
echo "abc def"|awk '/abc/ {print $0,0}; /def/{print $0,1}' #用分号分隔多个表达式
命令行会在执行写文件操作完毕后自动将这个文件关闭。但awk不行,需要手工关闭,如果不关闭就会出现内存泄漏
Linux中一个进程能打开的文件数量是有限的。
AWK还可以直接调用Linux命令,这样awk可以不像其他语言那样需要提供大量的日常编程需要的函数库,有助于程序保持最小规模
例如要排序,直接调用sort命令,它不需要提供内建的排序函数
f