在介绍自动化测试模型之前,我们先来了解库、框架和工具之间的区别。
5.1 基本概念
1.库
库的英文单词是 Library,库是由代码集合成的一个产品,可供程序员调用。面向对象的代码组织形成的库叫类库,面向过程的代码组织形成的库叫函数库。
从这个角度看,第 4 章介绍的 WebDriver 就属于库的范畴,因为它提供了一组操作 Web 页面的类与方法,所以可以称它为 Web 自动化测试库。
2.框架
框架的英文单词是 Framework,框架是为解决一个或一类问题而开发的产品,用户一般只需使用框架提供的类或函数,即可实现全部功能。
从这个角度看,unittest 框架(第 6 章)主要用于测试用例的组织和执行,以及测试结果的生成。因为它的主要任务就是帮助我们完成测试工作,所以通常称它为测试框架。
3.工具
工具的英文单词是 Tools,工具与框架所做的事情类似,只是工具提供了更高层次的封装,屏蔽了底层的代码,提供了单独的操作界面供用户使用。
例如,UFT(QTP)、Katalon 就属于自动化测试工具。
5.2 自动化测试模型
自动化测试模型可分为线性测试、模块化与类库、数据驱动测试和关键字驱动测试,下面分别介绍这几种自动化测试模型的特点。
1.线性测试
通过录制或编写对应用程序的操作步骤会产生相应的线性脚本,每个线性脚本相对独立,且不产生依赖与调用。这是早期自动化测试的一种形式,即单纯地模拟用户完整的操作场景。第 4 章中的自动化测试例子就属于线性测试。
2.模块化与类库
线性测试的缺点是不易维护,因此早期的自动化测试专家开始思考用新的自动化测试模型来代替线性测试。
做法很简单,借鉴了编程语言中的模块化思想,把重复的操作单独封装成公共模块。在测试用例执行过程中,当需要用到模块封装时对其进行调用,这样就最大限度地消除了重复,从而提高测试用例的可维护性。
3.数据驱动测试
虽然模块化测试很好地解决了脚本的重复问题,但是,自动化测试脚本在开发过程中还是发现了诸多不便。例如,在测试不同用户登录时,虽然登录的步骤是一样的,但是登录用的数据是不同的。模块化测试并不能解决这类问题。于是,数据驱动测试的概念被提出。
数据驱动测试的定义:数据的改变驱动自动化测试的执行,最终引起测试结果的改变。简单理解就是把数据驱动所需要的测试数据参数化,我们可以用多种方式来存储和管理这些参数化的数据。
4.关键字驱动测试
关键字驱动测试又被称为表驱动测试或基于动作字测试。这类框架会把自动化操作封装为「关键字」,避免测试人员直接接触代码,多以「填表格」的形式降低脚本的编写难度。
Robot Framework 是主流的关键字驱动测试框架之一,通过它自带的 Robot Framework RIDE 编写的自动化测试用例,如下图所示。
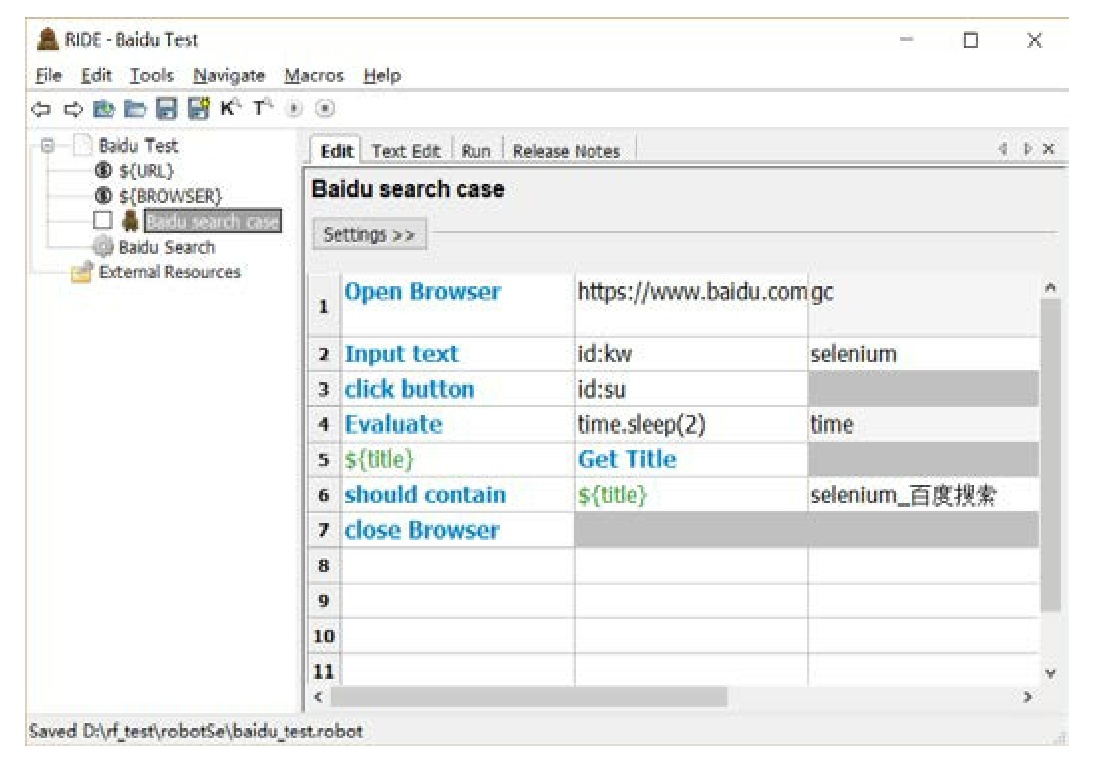
本节简单介绍了几种测试模型的特点。这几种测试模型并非后者淘汰前者的关系,在实际实施过程中,往往需要相互结合使用。
5.3 模块化与参数化
模块化与参数化一般需要配合使用,即在创建函数或类方法时为它们设置入参,从而使它们可以根据不同的参数执行相应的操作。
下面用一个简单的例子介绍它们的用法。创建一个邮箱测试脚本 test_mail.py。
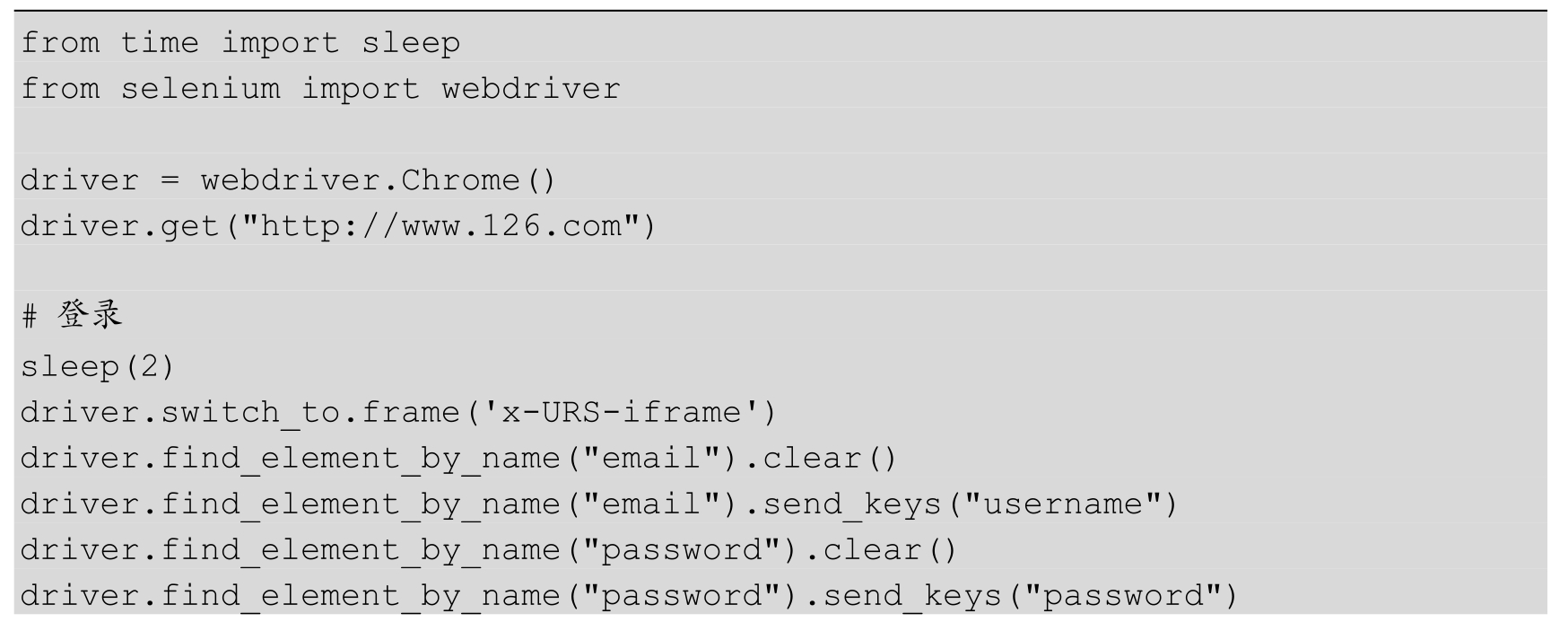

假设要实现一个关于邮箱的自动化测试项目,那么可能每条测试用例都需要有登录动作和退出动作。大部分测试用例都是在登录之后进行的,例如,发邮件,查看、删除、搜索邮件等。此时,需要创建一个新的 module.py 文件来存放登录动作和退出动作。



class Mail: def __init__(self, driver): self.driver = driver def login(self, username, password): """ 登录 """ self.driver.switch_to.frame('x-URS-iframe') self.driver.find_element_by_name("email").clear() self.driver.find_element_by_name("email").send_keys(username) self.driver.find_element_by_name("password").clear() self.driver.find_element_by_name("password").send_keys(password) self.driver.find_element_by_id("dologin").click() def logout(self): """ 退出 """ self.driver.find_element_by_link_text("退出").click()
首先创建一个 Mail 类,在__init__()初始化方法中接收 driver 驱动并赋值给 self.driver。在 login()和 logout()方法中分别使用 self.driver 实现邮箱的登录动作和退出动作。
接下来修改 test_mail.py,测试调用 Mail 类中的 login()和 logout()方法。
""" 126邮箱登录/退出 """ from time import sleep from selenium import webdriver from module import Mail driver = webdriver.Chrome() driver.get("http://www.126.com") # 调用Mail类并传入driver驱动 mail = Mail(driver) # 登录 mail.login("", "") # 登录之后的动作... sleep(5) # 退出 mail.logout() driver.quit()
在编写测试用例过程中,如果需要用到登录动作和退出动作,那么只需调用 Mail 类中的 login()方法和 logout()方法即可,这将大大提高测试代码的可复用性。
如果我们的需求是测试登录功能呢?虽然登录步骤是固定的,但是测试的数据(账号)不同,这时就需要把 login()方法参数化。修改 module.py 文件代码如下。
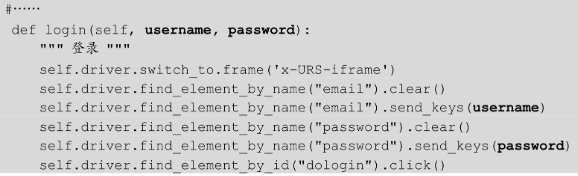
class Mail: def __init__(self, driver): self.driver = driver def login(self, username, password): """ 登录 """ self.driver.switch_to.frame('x-URS-iframe') self.driver.find_element_by_name("email").clear() self.driver.find_element_by_name("email").send_keys(username) self.driver.find_element_by_name("password").clear() self.driver.find_element_by_name("password").send_keys(password) self.driver.find_element_by_id("dologin").click() def logout(self): """ 退出 """ self.driver.find_element_by_link_text("退出").click()
这样就进一步提高了 login()方法的可复用性,它不再使用一个固定的账号登录,而是根据被调用者传来的用户名和密码执行登录动作。
在测试用例中,可以用不同的数据调用 login()方法。
""" 126邮箱登录/退出 """ from time import sleep from selenium import webdriver from module import Mail driver = webdriver.Chrome() driver.get("http://www.126.com") user_info = [ {"username": "", "password": ""}, {"username": "", "password": "123"}, {"username": "user", "password": ""}, {"username": "error", "password": "error"}, {"username": "admin", "password": "admin123"}, ] # 调用Mail类 mail = Mail(driver) # 登录账号为空 mail.login(user_info[0]["username"], user_info[0]["password"]) # 用户名为空 mail.login(user_info[1]["username"], user_info[1]["password"]) # 密码为空 mail.login(user_info[2]["username"], user_info[2]["password"]) # 用户名密码错误 mail.login(user_info[3]["username"], user_info[3]["password"]) # 管理员登录 mail.login(user_info[4]["username"], user_info[4]["password"]) # ……
5.4 读取数据文件
虽然前面的例子中用到了参数化,但大多数测试更倾向于把测试数据放到数据文件中。下面介绍几种常见的读取数据文件的方法。
5.4.1 读取 txt 文件
Python 提供了以下几种读取 txt 文件的方法。
● read():读取整个文件。
● readline():读取一行数据。
● readlines():读取所有行的数据。
回到前面登录的例子,现在把用户名和密码存放到 txt 文件,然后读取该 txt 文件中的数据作为测试用例的数据。创建./data_file/user_info.txt 文件。
:123
user:
error:error
admin:admin123
guest:guest123
这里将用户名和密码按行写入 txt 文件中,用户名和密码之间用冒号「:」隔开。创建 read_txt.py 文件,用于读取 txt 文件。
# 读取文件 with(open("./data_file/user_info.txt", "r")) as user_file: data = user_file.readlines() # 格式化处理 users = [] for line in data: user = line[:-1].split(":") users.append(user) # 打印users二维数组 print(users) """ # 调用Mail类 mail = Mail(driver) # 用户名为空 mail.login(users[0][0], users[0][1]) # 密码为空 mail.login(users[1][0], users[1][1]) # 用户名密码错误 mail.login(users[2][0], users[2][1]) # 管理员登录 admin mail.login(users[3][0], users[3][1]) """
首先通过 open()以读(“r”)的方式打开 user_info.txt 文件,readlines()可读取文件中的所有行并赋值给变量 data。
接下来循环 data 中的每一行数据,[:-1] 可对字符串进行切片,以省略最后一个字符,因为读取的每一行数据结尾都有一个换行符「
」。split()通过冒号(:)对每行数据进行拆分,会得到数组[『』,『123』]。
最后使用 append()把每一组用户名和密码追加到 users 数组中。
取 users 数组中的数据,将得到的数组用不同的用户名/密码进行登录,代码如下。
# 调用Mail类 mail = Mail(driver) # 用户名为空 mail.login(users[0][0], users[0][1]) # 密码为空 mail.login(users[1][0], users[1][1]) # 用户名密码错误 mail.login(users[2][0], users[2][1]) # 管理员登录 admin mail.login(users[3][0], users[3][1])
5.4.2 读取 CSV 文件
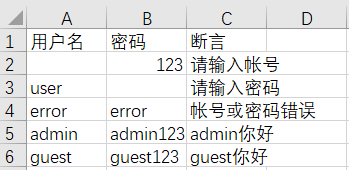
CSV 文件可用来存放固定字段的数据,下面我们把用户名、密码和断言保存到 CSV 文件中,如图 5-2 所示。
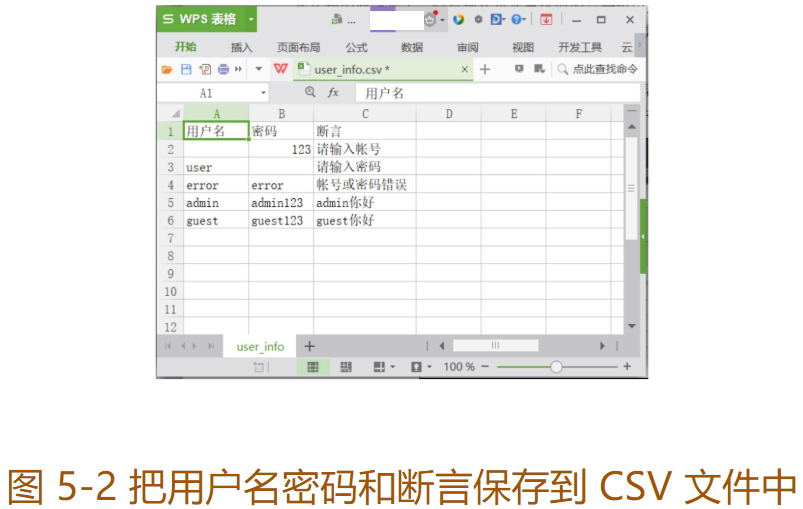
注意:可以把 WPS 表格或 Excel 表格通过文件「另存为」保存为 CSV 类型的文件,但不要直接修改文件的后缀名来创建 CSV 文件,因为这样的文件并非真正的 CSV 类型的文件。
下面编写 read_csv.py 文件进行循环读取。
# coding=utf-8 import csv import codecs from itertools import islice # 读取本地 CSV 文件 data = csv.reader(codecs.open('./data_file/user_info.csv', 'r', 'utf_8_sig')) # 用户存放用户数据 users = [] # 循环输出每行信息 for line in islice(data, 1, None): users.append(line) # 打印 print(users)
通过 Python 读取 CSV 文件比较简单,但会遇到两个问题。
(1)中文乱码问题。在数据文件中我们不可避免地会使用中文,codecs 是 Python 标准的模块编码和解码器。首先,通过 codecs 提供的 open()方法,在打开文件时可以指定编码类型,如 utf_8_sig;然后,导入 csv 模块,通过 reader()方法读取文件,即避免中文乱码问题。
(2)跳过 CSV 文件的第一行。因为我们一般会在第一行定义测试字段名,所以在读取数据时需要跳过。Python 的内建模块 itertools 提供了用于操作迭代对象的函数,即 islice()函数,它可以返回一个迭代器,第一个参数指定迭代对象,第二个参数指定开始迭代的位置,第三个参数表示结束位。
5.4.3 读取 XML 文件
有时我们需要读取的数据是不规则的。例如,我们需要用一个配置文件来配置当前自动化测试平台、浏览器、URL、登录的用户名和密码等,这时就可以使用 XML 文件来存放这些测试数据。
创建 config.xml 文件,代码如下。
<?xml version="1.0" encoding="utf-8"?> <config> <platform> <os>Windows</os> <os>Linux</os> <os>macOS</os> </platform> <browsers> <browser>Firefox</browser> <browser>Chrome</browser> <browser>Edge</browser> </browsers> <url>http://www.xxxx.com</url> <users> <login username="admin" password="123456"/> <login username="guest" password="654321"/> </users> </config>
通过代码可以看出,数据主要存放在标签对之间,如 <platform>Windows</platform>。或者是作为标签的属性存放,如 <login username=「admin」password=「123456」/>。
下面以 config.xml 文件为例,介绍读取 XML 文件的方法。
1.获得标签对之间的数据
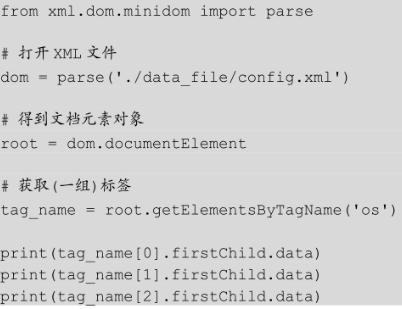

Python 自带读取 XML 文件的模块,通过 parse()方法可读取 XML 文件。documentElement()方法用于获取文档元素对象,getElementsByTagName()方法用于获取文件中的标签。我们不需要指定标签的层级关系,即获取的标签可以是任意层级的,之所以在定义 XML 文件时设置层级,仅仅是为了方便阅读。
接下来,获取标签数组中的某个元素。firstChild 属性可返回被选节点的第一个子节点,data 表示获取该节点的数据,它和 WebDriver 中的 text 语句作用相似。
2.获得标签的属性值


这里主要使用 getAttribute()方法获取元素的属性值,它和 WebDriver 中的 get_attribute()方法作用相似。
from xml.dom.minidom import parse # 打开xml文档 dom = parse('./data_file/config.xml') # 得到文档元素对象 root = dom.documentElement # 获取(一组)标签 tag_name = root.getElementsByTagName('os') print(tag_name[0].firstChild.data) print(tag_name[1].firstChild.data) print(tag_name[2].firstChild.data) login_info = root.getElementsByTagName('login') # 获得login标签的username属性值 username = login_info[0].getAttribute("username") print(username) # 获得login标签的password属性值 password = login_info[0].getAttribute("password") print(password) # 获得第二个login标签的username属性值 username = login_info[1].getAttribute("username") print(username) # 获得第二个login标签的password属性值 password = login_info[1].getAttribute("password") print(password)
5.4.4 读取 JSON 文件
JSON 是一种轻量级的数据交换格式,清晰的层次结构使得 JSON 文件被广泛使用。Python 同样可以读取 JSON 文件,下面创建 user_info.json 文件。
[ {"username":"", "password":""}, {"username":"", "password":"123"}, {"username":"user", "password":""}, {"username":"error", "password":"error"}, {"username":"admin", "password":"admin123"} ]
通过 open()方法即可读取 user_info.json 文件。因为测试数据本身是以列表和字典格式存放的,所以读取整个文件内容后,通过 JSON 提供的表将 str 类型转换为 list 类型即可。
创建 read_json.py 文件。
import json with open("./data_file/user_info.json", "r") as f: data = f.read() user_list = json.loads(data) print(user_list)
注意:本节仅简单介绍了几种常见的读取数据文件的方法。在自动化测试中,数据驱动必须和单元测试框架一起讨论才有意义,所以我们在介绍完 unittest 单元测试框架之后再来讨论数据驱动。