第 3 章 初识 Elasticsearch
本章主要介绍 Elasticsearch 的基础知识,如 Elasticsearch 的安装、配置,另外,还会介绍 Elasticsearch 的相关术语及架构设计,以方便读者学习后续章节。
3.1 Elasticsearch 简介
Elasticsearch 是一个分布式、可扩展、近实时的高性能搜索与数据分析引擎。Elasticsearch 基于 Apache Lucene 构建,采用 Java 编写,并使用 Lucene 构建索引、提供搜索功能。Elasticsearch 的目标是让全文搜索功能的落地变得简单。
Elasticsearch 的特点和优势如下:
① 分布式实时文件存储。Elasticsearch 可将被索引文档中的每一个字段存入索引,以便字段可以被检索到。
② 实时分析的分布式搜索引擎。Elasticsearch 的索引分拆成多个分片,每个分片可以有零个或多个副本。集群中的每个数据节点都可承载一个或多个分片,并且协调和处理各种操作;负载再平衡和路由会自动完成。
③ 高可拓展性。大规模应用方面,Elasticsearch 可以扩展到上百台服务器,处理 PB 级别的结构化或非结构化数据。当然,Elasticsearch 也可以运行在单台 PC 上。
④ 可插拔插件支持。Elasticsearch 支持多种插件,如分词插件、同步插件、Hadoop 插件、可视化插件等。
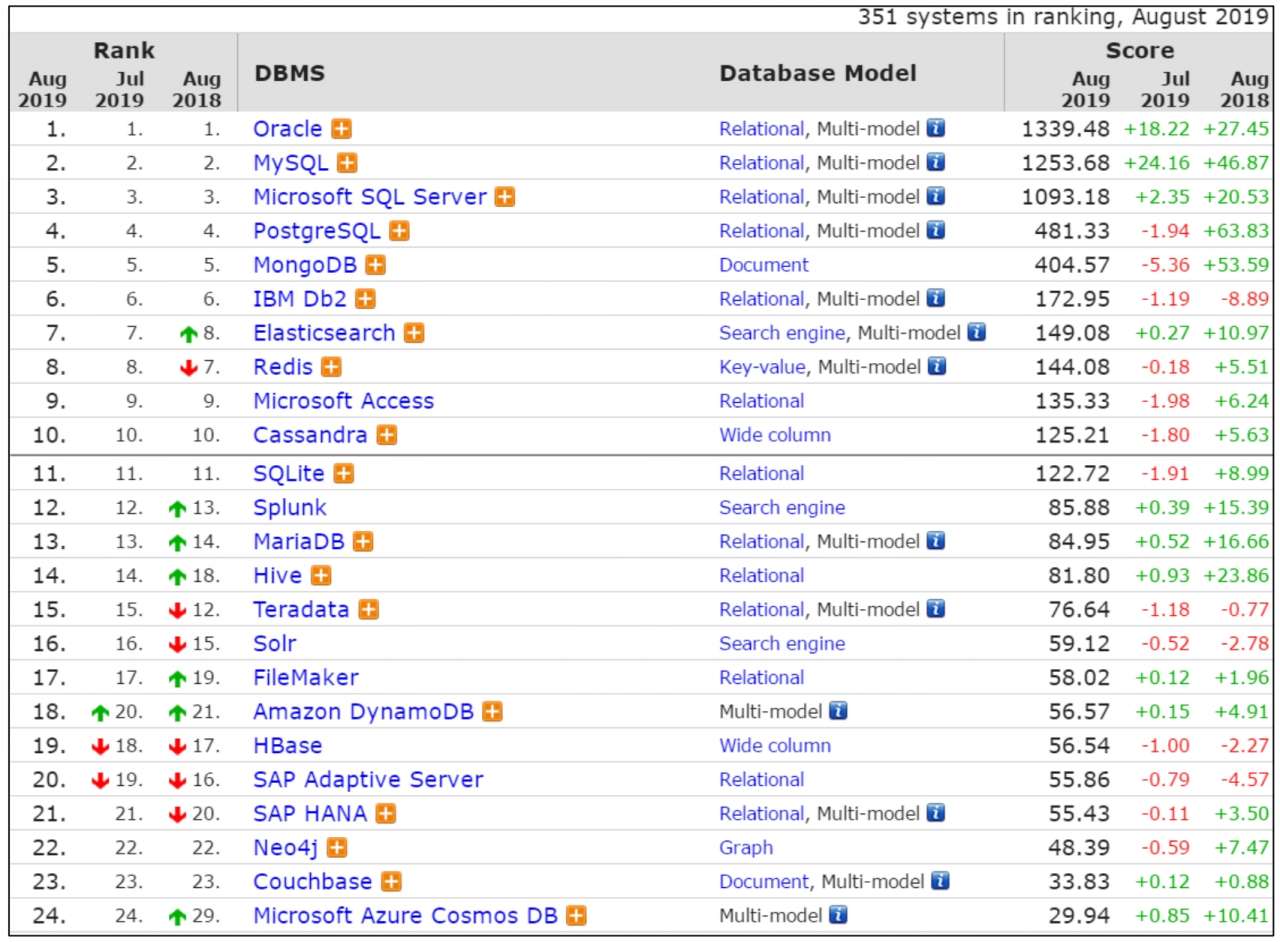
根据最新的数据库引擎排名显示,Elasticsearch、Splunk 和 Solr 分别占据了数据库搜索引擎的前三位,如图 3-1 所示。
3.2 Elasticsearch 的安装与配置
下面介绍 Elasticsearch 在 Windows 环境下和在 Linux 环境下的安装方法。由于 Elasticsearch 依赖 Java 环境,因此首先介绍 Java 环境的安装方法。
3.2.1 安装 Java 环境
首先下载并安装 JDK(JAVA Development Kit)。JDK 是整个 Java 开发的核心,它包含了 Java 的运行环境、Java 工具和 Java 基础类库。
推荐使用jdk11 (LTS)
1.在 Windows 环境下安装
(略)
2.在 Linux 环境下安装
第一要先卸载openjdk
java -version rpm -qa | grep java rpm -e --nodeps java-1.6.0-openjdk-1.6.0.41-1.13.13.1.el6_8.x86_64 rpm -e --nodeps java-1.7.0-openjdk-1.7.0.181-2.6.14.10.el6.x86_64
首先将 jdk-8u261-linux-x64.tar.gz 下载到本地。在本地打开 SecureCRT 软件,连接 Linux 服务器。
随后使用命令 tar-zxvf jdk-8u261-linux-x64.tar.gz 将压缩包解压缩到当前目录下。解压缩成功之后,使用 ll 命令查看文件列表。
最后配置环境变量,具体方法为使用 vim 命令修改/etc/profile 文件。在 profile 文件中添加如下环境变量:
#java jdk environment export JAVA_HOME=/usr/local/jdk1.8.0 export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar export PATH=$PATH:${JAVA_HOME}/bin
保存修改后,需重新加载/etc/profile 配置文件,具体命令为
. /etc/profile
命令执行成功后,检查 JDK 是否安装成功。
3.2.2 Elasticsearch 的安装
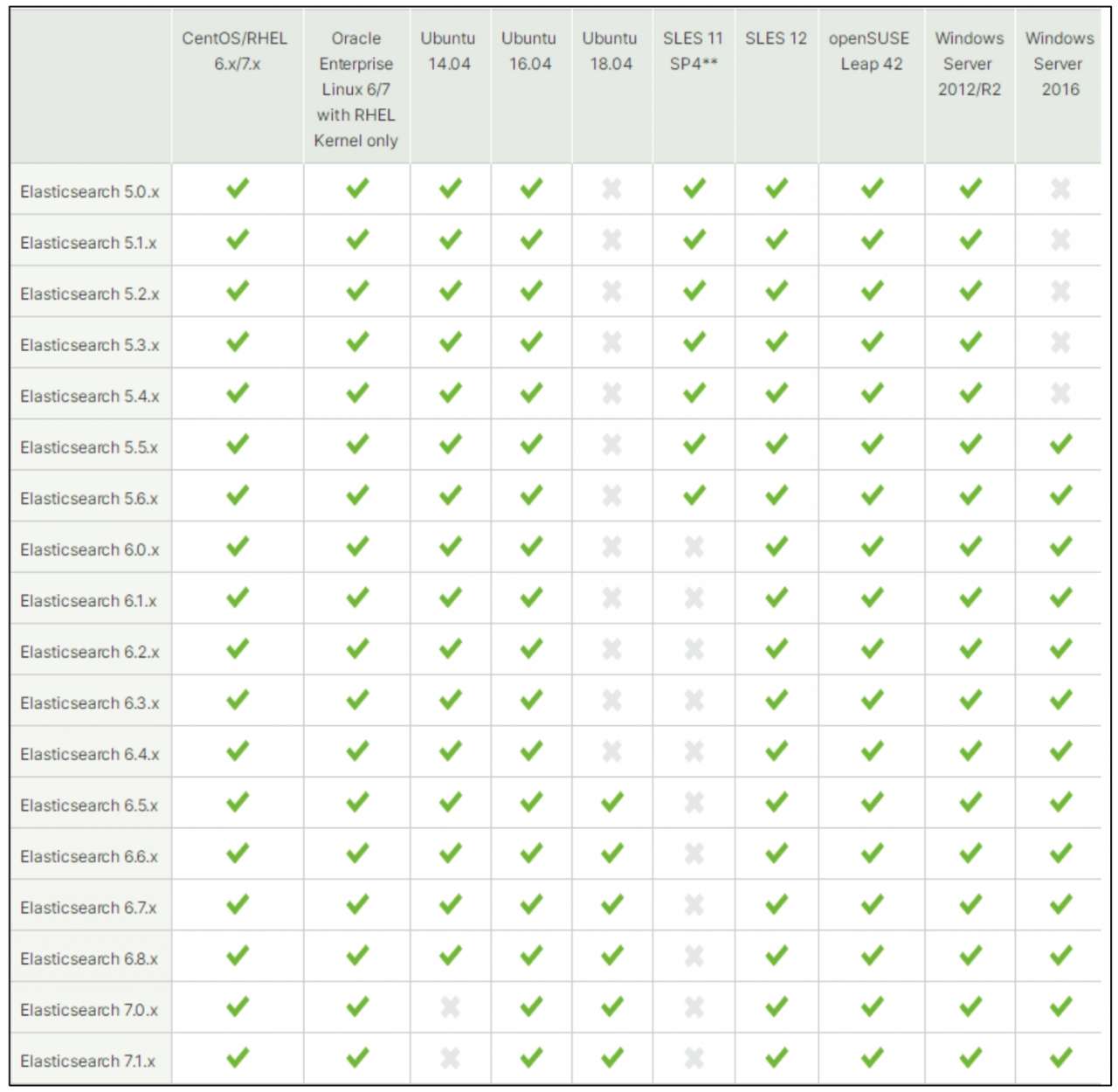
Elasticsearch 支持多平台,我们可以在 Elasticsearch 官网找到 Elasticsearch 官方支持的操作系统和 JVM 的矩阵
下载中心 - Elastic 中文社区 (elasticsearch.cn)
下面介绍如何安装 Elasticsearch,本书主要介绍在 Windows 系统和常用的 Linux 系统下的安装方法。
1.在 Windows 系统下安装 Elasticsearch
解压缩后,在同级目录下将创建一个名为 elasticsearch-7.2.0 的文件夹,我们称之为%ES_HOME%
在 elasticsearch-7.2.1 文件夹中有 bin、config、jdk、lib、logs、modules、plugins 和文件夹。
● bin 文件夹下存放的是二进制脚本,包括启动 Elasticsearch 节点和安装的 Elasticsearch 插件。
● config 文件夹下存放的是包含 elasticsearch.yml 在内的配置文件。
● jdk 文件夹下存放的是 Java 运行环境。
● lib 文件夹下存放的是 Elasticsearch 自身所需的 jar 文件。
● logs 文件夹下存放的是日志文件。
● modules 文件夹下存放的是 Elasticsearch 的各个模块。
● plugins 文件夹下存放的是配置插件,每个插件都包含在一个子目录中。
2.在 Linux 系统下安装 Elasticsearch
有 tar.gz 文件格式的安装包可以安装在CentOS 发行版上。
在 Linux 系统下,获取 Elasticsearch V7.2.1 版本安装包的命令如下所示。
获取安装包后,可以使用如下命令解压缩安装包:
tar -zxvf elasticsearch-7.2.1-no-jdk-linux-x86_64.tar.gz
删除残留压缩包
rm elasticsearch-7.2.1-no-jdk-linux-x86_64.tar.gz
移动到安装目录
mv elasticsearch-7.2.1 /usr/local
安装完在 elasticsearch-7.2.1 目录中,我们可以执行如下命令启动 Elasticsearch:
./bin/elasticsearch
在默认情况下,Elasticsearch 在前台运行,并将其日志打印到标准输出(stdout)。在运行过程中,如需停止服务,则可以通过按组合键 Ctrl+C 停止服务。
3.2.3 Linux系统报错异常can not run elasticsearch as root
问题:
es安装好之后,使用root启动会报错:can not run elasticsearch as root
原因:
为了安全不允许使用root用户启动
解决:
es5之后的都不能使用添加启动参数或者修改配置文件等方法启动了,必须要创建用户
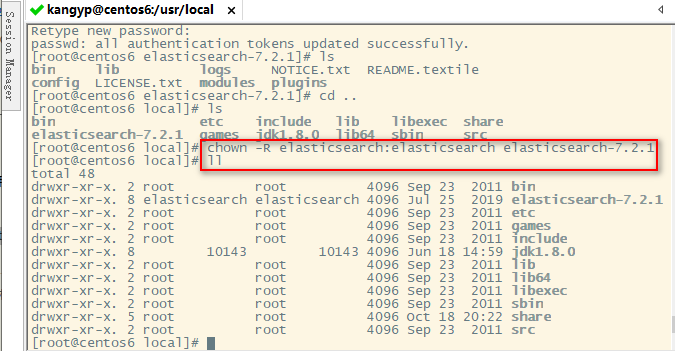
1、创建用户:elasticsearch
[root@iZbp1bb2egi7w0ueys548pZ bin]# adduser elasticsearch
2、创建用户密码,需要输入两次
[root@iZbp1bb2egi7w0ueys548pZ bin]# passwd elasticsearch
3、将对应的文件夹权限赋给该用户
[root@iZbp1bb2egi7w0ueys548pZ local]# chown -R elasticsearch:elasticsearch elasticsearch-7.2.1
4、切换至elasticsearch用户
[root@iZbp1bb2egi7w0ueys548pZ etc]# su elasticsearch
在 Elasticsearch 运行过程中,如果需要将 Elasticsearch 作为守护进程运行,则需要在命令行上指定命令参数「-d」,并使用 「-p」选项将 Elasticsearch 的进程 ID 记录在文件中,启动命令如下:
. /bin/elasticsearch -d -p pid
此时 Elasticsearch 的日志消息可以在 $es_home/logs/目录中找到。
在关闭 Elasticsearch 时,可以根据 PID 文件中记录的进程 ID 执行 pkill 命令,具体命令如下:
pkill -F pid
在启动 Elasticsearch 过程中,我们还可以通过命令行对 Elasticsearch 进行配置。一般来说,在默认情况下,Elasticsearch 会从 $es_home/config/elasticsearch.yml 文件加载其配置内容。我们还可以在命令行上指定配置,此时需要使用「-e」语法。当命令行配置 Elasticsearch 参数时,启动命令如下:
. /bin/elasticsearch -d -Ecluster.name=my_cluster -Enode.name=node_1
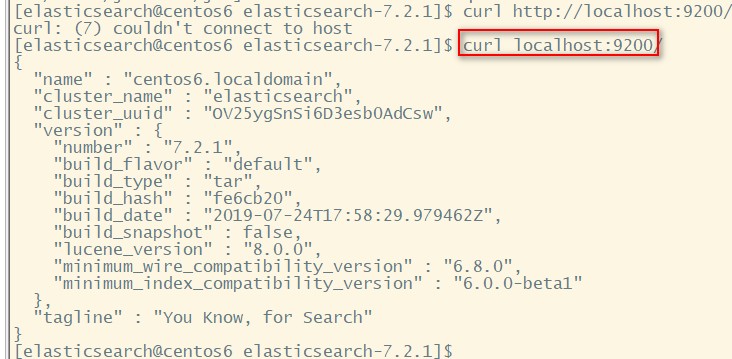
在 Elasticsearch 启动后,需要检查 Elasticsearch 是否能够运行。我们可以通过向本地主机上的端口 9200 发送 HTTP 请求来测试本地 Elasticsearch 节点是否正在运行,发送请求如下:
curl localhost:9200/
3.2.4 Elasticsearch 的配置
与近年来很多流行的框架和中间件一样,Elasticsearch 的配置同样遵循「约定大于配置」的设计原则。用户既可以使用群集更新设置 API 在正在运行的群集上更改大多数设置,也可以通过配置文件对 Elasticsearch 进行配置。
1.配置文件位置信息
在 Elasticsearch 中有三个配置文件,分别是 elasticsearch.yml、jvm.options 和 log4j2.properties,这些文件位于 config 目录下,如图 3-8 所示。
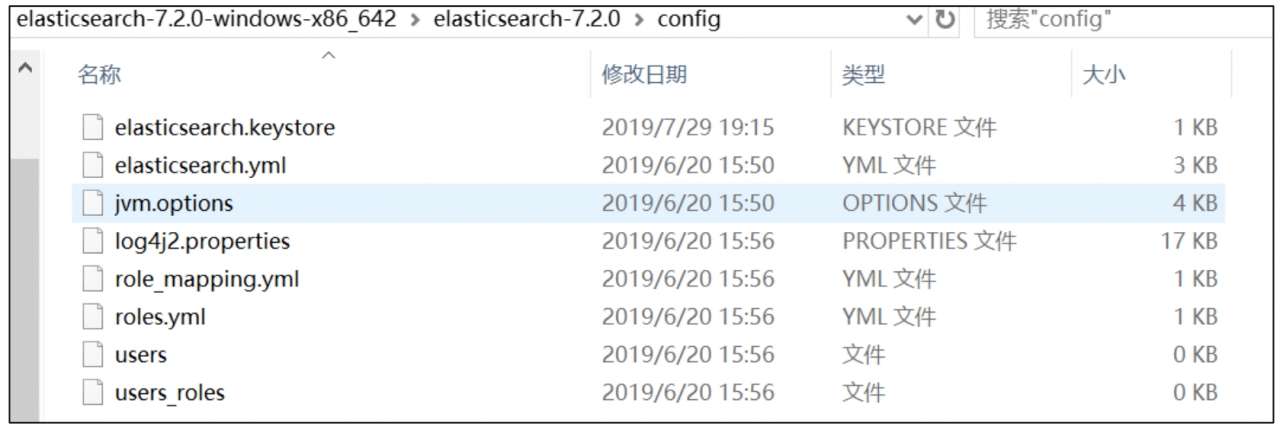
注:上述文件位于 config 目录下,这是默认位置。默认位置取决于我们安装 Elasticsearch 时是否基于下载的 tar.gz 包或 zip 包,如果是,则配置目录默认位置为 $es_home/config。
如果用户想自定义配置目录的位置,则可以通过 es_path_conf 环境变量进行更改,如下所示:

2.配置文件的格式
Elasticsearch 的配置文件格式为 yaml。下面展示一些更改数据和日志目录路径的示例:

除上述层级方式配制外,也可将层级路径参数整合为一条参数路径配置,如下所示:

如果需要在配置文件中引用环境变量的值,则可以在配置文件中使用 ${...}符号。引用的环境变量会替换环境变量原有的值,如下所示:

3.设置 JVM 选项
在 Elasticsearch 中,用户很少需要更改 Java 虚拟机(JVM)选项。一般来说,最可能的更改是设置堆大小。在默认情况下,Elasticsearch 设置 JVM 使用最小堆空间和最大堆空间的大小均为 1GB。
设置 JVM 选项(包括系统属性和 jvm 标志)的首选方法是通过 jvm.options 配置文件设置。此文件的默认位置为 config/jvm.options。
在 Elasticsearch 中,我们通过 xms(最小堆大小)和 xmx(最大堆大小)这两个参数设置 jvm.options 配置文件指定的整个堆大小,一般应将这两个参数设置为相等。
在 jvm.options 配置文件中,包含了以下特殊语法行来分隔 JVM 参数列表。
(1)忽略由空白组成的行。
(2)以「#」开头的行被视为注释并被忽略,如下所示:
# this is a comment
(3)以「-」开头的行被视为独立于本机 JVM 版本号的 JVM 选项,如下所示:
-Xmx2g
(4)以数字开头,且后面为「:」的行被视为一个 JVM 选项,该选项仅在本机 JVM 的版本号相互匹配时适用,如下所示:
8:-Xmx2g
(5)以数字开头,且后面为「-」的行被视为一个 JVM 选项,仅当本机 JVM 的版本号大于或等于该数字版本号时才适用,如下所示:
8-:-Xmx2g
(6)以数字开头,且后面为「-」,再后面为数字的行被视为一个 JVM 选项,仅当本机 JVM 的版本号在这两个数字版本号的范围内时才适用,如下所示:
8-9:-Xmx2g
(7)所有其他行都被拒绝解析。
此外,用户还可以通过 ES_JAVA_OPTS 环境变量来设置 Java 虚拟机选项,如下所示:

4.安全设置
在 Elasticsearch 中,有些设置信息是敏感且需要保密的,此时单纯依赖文件系统权限来保护这些信息是不够的,因此需要配置安全维度的信息。Elasticsearch 提供了一个密钥库和相应的密钥库工具来管理密钥库中的设置。这里的所有命令都适用于 Elasticsearch 用户。
需要指出的是,对密钥库所做的所有修改,都必须在重新启动 Elasticsearch 之后才会生效。
此外,在当前 Elasticsearch 密钥库中只提供模糊处理,以后会增加密码保护。
安全设置就像 elasticsearch.yml 配置文件中的常规设置一样,需要在集群中的每个节点上指定。当前,所有安全设置都是特定于节点的设置,每个节点上必须有相同的值。
安全设置的常规操作有创建密钥库、查看密钥库中的设置列表、添加字符串设置、添加文件设置、删除密钥设置和可重新加载的安全设置等,下面一一介绍。
4.1 创建密钥库
想要创建 elasticsearch.keystore,需要使用 create 命令,如下所示:
bin/elasticsearch-keystore create
命令执行后,将创建 2 个文件,文件名分别为 elasticsearch.keystore 和 elasticsearch.yml。
4.2 查看密钥库中的设置列表
使用 list 命令可以查看密钥库中的设置列表,如下所示:
bin/elasticsearch-keystore list
4.3 添加字符串设置
如果需要设置敏感的字符串,如云插件的身份验证凭据,则可以使用 add 命令添加,如下所示:
bin/elasticsearch-keystore add the.setting.name.to.set
命令执行后将提示输入设置值。
用户可以使用--stdin 标志在窗口 stdin 中输出待设置的目标值,如下所示:
cat /file/containing/setting/value | bin/elasticsearch-keystore add --stdin the.setting.name.to.set
4.4 添加文件设置
用户可以使用添加文件命令添加敏感信息文件,如云插件的身份验证密钥文件。配置时需确保将文件路径作为参数包含在设置名称之后,如下所示:
bin/elasticsearch-keystore add-file the.setting.name.to.set /path/example-file.json
4.5 删除密钥设置
如果需要从密钥库中删除设置,则使用 remove 命令,如下所示:
bin/elasticsearch-keystore remove the.setting.name.to.remove
可重新加载的安全设置
就像 elasticsearch.yml 中的设置值一样,对密钥库内容的更改不会自动应用于正在运行的 Elasticsearch 节点,因此需要重新启动节点才能重新读取设置。
对于某些安全设置,我们可以标记为可重新加载,这样设置后,就可以在正在运行的节点上重新读取和应用了。
需要指出的是,所有安全设置的值(不论是否可重新加载),在所有群集节点上必须相同。更改所需的安全设置后,使用 bin/elasticsearch keystore add 命令,调用:
POST _nodes/reload_secure_settings
该 API 接口将解密并重新读取每个集群节点上的整个密钥库,但只限于可重载的安全设置,对其他设置的更改将在下次重新启动之后生效。
该 API 接口调用返回后,重新加载就完成了,这意味着依赖于这些设置的所有内部数据结构都已更改,一切设置信息看起来好像从一开始就有了新的值。
当更改多个可重新加载的安全设置时,用户需要在每个群集节点上都修改所有设置,然后发出重新加载安全设置调用,而不是在每次修改后就重新加载。
5.日志记录配置
在 Elasticsearch 中,使用 log4j2 来记录日志。用户可以使用 log4j2.properties 文件配置 log4j2。
Elasticsearch 公开了三个属性信息,分别是 $sys:es.logs.base_path、$sys:es.logs.cluster_name 和 $sys:es.logs.node_name,用户可以在配置文件中引用这些属性来确定日志文件的位置。
属性 $sys:es.logs.base_path 将解析为日志文件目录地址,$sys:es.logs.cluster_name 将解析为群集名称(在默认配置中,用作日志文件名的前缀),$sys:es.logs.node_name_将解析为节点名称(如果显式地设置了节点名称)。
例如,假设用户的日志目录(path.logs)是/var/log/elasticsearch,集群命名为 production,那么 $sys:es.logs.base_path_将解析为/var/log/elasticsearch,$sys:es.logs.base_path/sys:file.Separator/$sys:es.logs.cluster_name.log 将解析为/var/log/elasticsearch/production.log。
下面我们结合 log4j2.properties 文件的主要配置信息来介绍各个属性的含义。log4j2.properties 文件的配置信息如下所示:
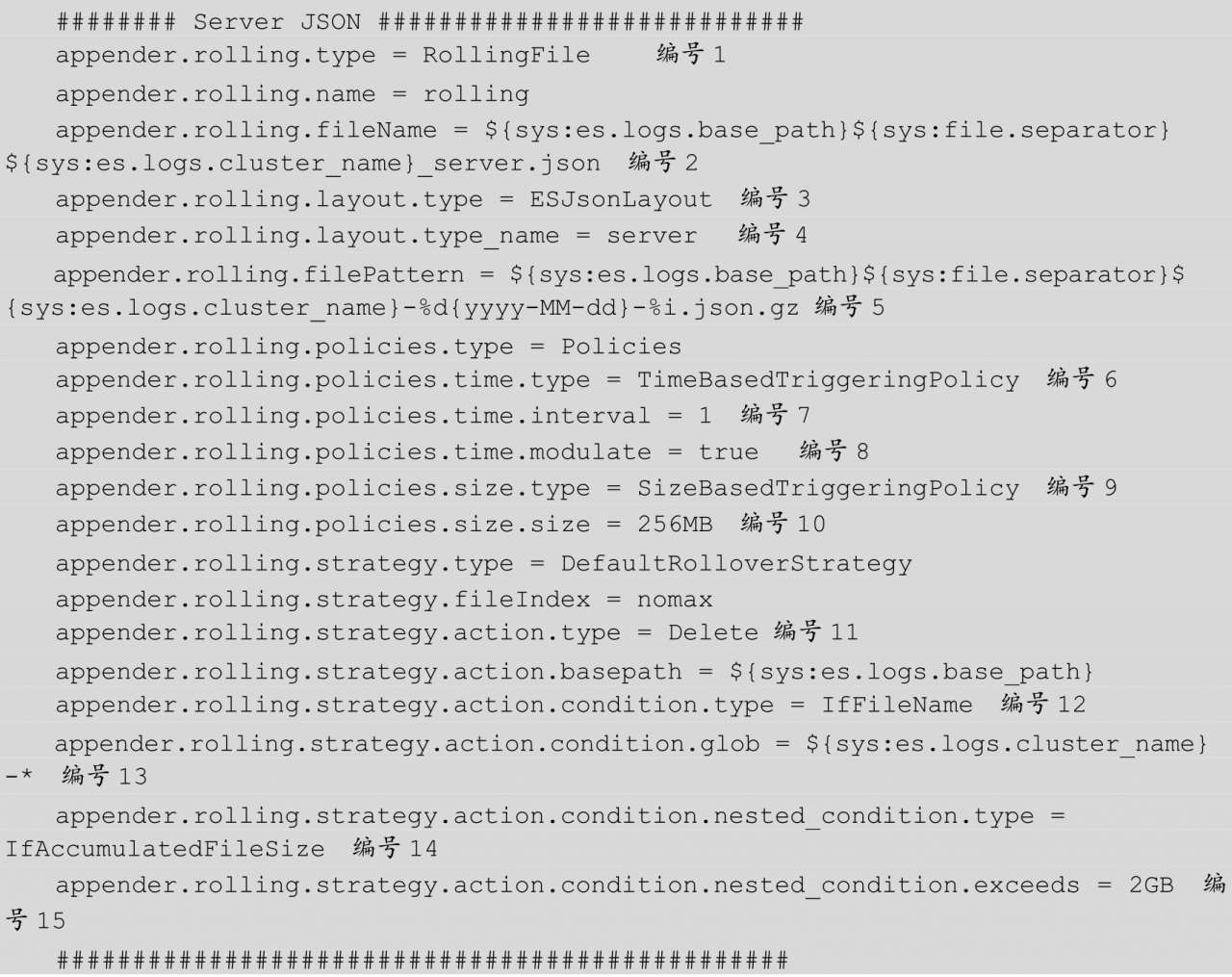
其中,上述被编号的配置属性含义如下所示。
编号 1:配置 RollingFile 的 appender 属性。
编号 2:日志信息将输出到/var/log/elasticsearch/production.json 中。
编号 3:使用 JSON 格式输出。
编号 4:type_name 是填充 ESJsonLayout 的类型字段的标志,该字段可以让我们在解析不同类型的日志时更加简单。
编号 5:将日志滚动输出到/var/log/elasticsearch/production-yyyy-MM-dd-i.json 文件。日志文件会被压缩处理,i 呈递增状态。
编号 6:使用基于时间戳的新增日志滚动策略。
编号 7:按天滚动新增日志。
编号 8:在日期时间上对齐标准,而不是按每 24 小时来新增一次滚动日志文件。
编号 9:按日志文件大小的策略来滚动新增日志文件。
编号 10:每生成 256MB 的日志文件,就滚动新增日志一次。
编号 11:每次新增滚动日志时执行删除日志文件动作。
编号 12:仅当文件匹配时才删除日志文件。
编号 13:该配置仅用于删除日志文件。
编号 14:只有当日志目录下积累了较多日志时才删除。
编号 15:压缩日志的条件是日志文件大小达到 2 GB。
在 log4j2.properties 文件中,我们还可以配置日志记录级别。配置日志记录级别有四种方法,每种方法都有适合使用的场景。这四种配置方法分别是通过命令行配置、通过 elasticsearch.yml 文件配置、通过集群配置和通过 log4j2.properties 配置。
(1)通过命令行配置。

适用场景:
当在单个节点上临时调试一个问题(如在后启动时或在开发过程中)时,这是最适合的方法。
(2)通过 elasticsearch.yml 文件配置。
所需要的配置属性如下所示:

如 logger.org.elasticsearch.transport:trace。
适用场景:
当临时调试一个问题,但没有通过命令行启动 Elasticsearch;或者希望在更持久的基础上调整日志级别时,这是最适合的方法。
(3)通过群集配置。
在集群中设置日志级别的方法如下所示:

示例如下所示:

适用场景:
当需要动态调整活动运行的集群上的日志级别时,这是最适合的方法。
(4)通过 log4j2.properties 配置。
在 log4j2.properties 中需要配置的属性如下所示:

示例如下所示:

适用场景:
当需要对日志程序进行细粒度的控制时(如将日志程序发送到另一个文件,或者以不同的方式管理日志程序),这是最适合的方法。
deprecation 日志
除常规日志记录外,Elasticsearch 还允许用户启用不推荐操作的日志记录。如果用户需要迁移某些功能,则可以提前确定这部分属性的配置。
在默认情况下,启动警告级别日志后,所有禁用日志均可输出到控制台和日志文件中。具体配置如下所示:
logger.deprecation.level = warn
该配置生效后,将在日志目录中创建每日滚动 deprecation 日志文件。用户需要定期检查此文件,尤其是准备升级到新的主要版本时。
默认日志记录配置已将取消 deprecation 日志的滚动策略设置为在 1GB 后滚动和压缩,并最多保留五个日志文件(四个滚动日志和一个活动日志)。
用户可以在 config/log4j2.properties 文件中通过将取消 deprecation 日志级别设置为 error 来禁用它。
6.JSON 日志格式
为了便于分析 Elasticsearch 的日志,日志默认以 JSON 格式打印。这是由 log4j 布局属性 appender.rolling.layout.type=esjsonlayout 配置的。此布局需要设置一个 type_name 属性,用于在分析时区分日志流,具体配置如下所示:

在配置生效后,日志的每一行就是一个 JSON 格式的字符串。
如果使用自定义布局,则需要用其他布局替换 appender.rolling.layout.type 行的配置,示例如下: