基本开发环境:
·Python3.6
·Pycharm
相关模块使用:
import requests import time
目标网页分析:
选择一个影视栏目,F12或者鼠标右键检查,打开开发者工具,选择network,下滑网页
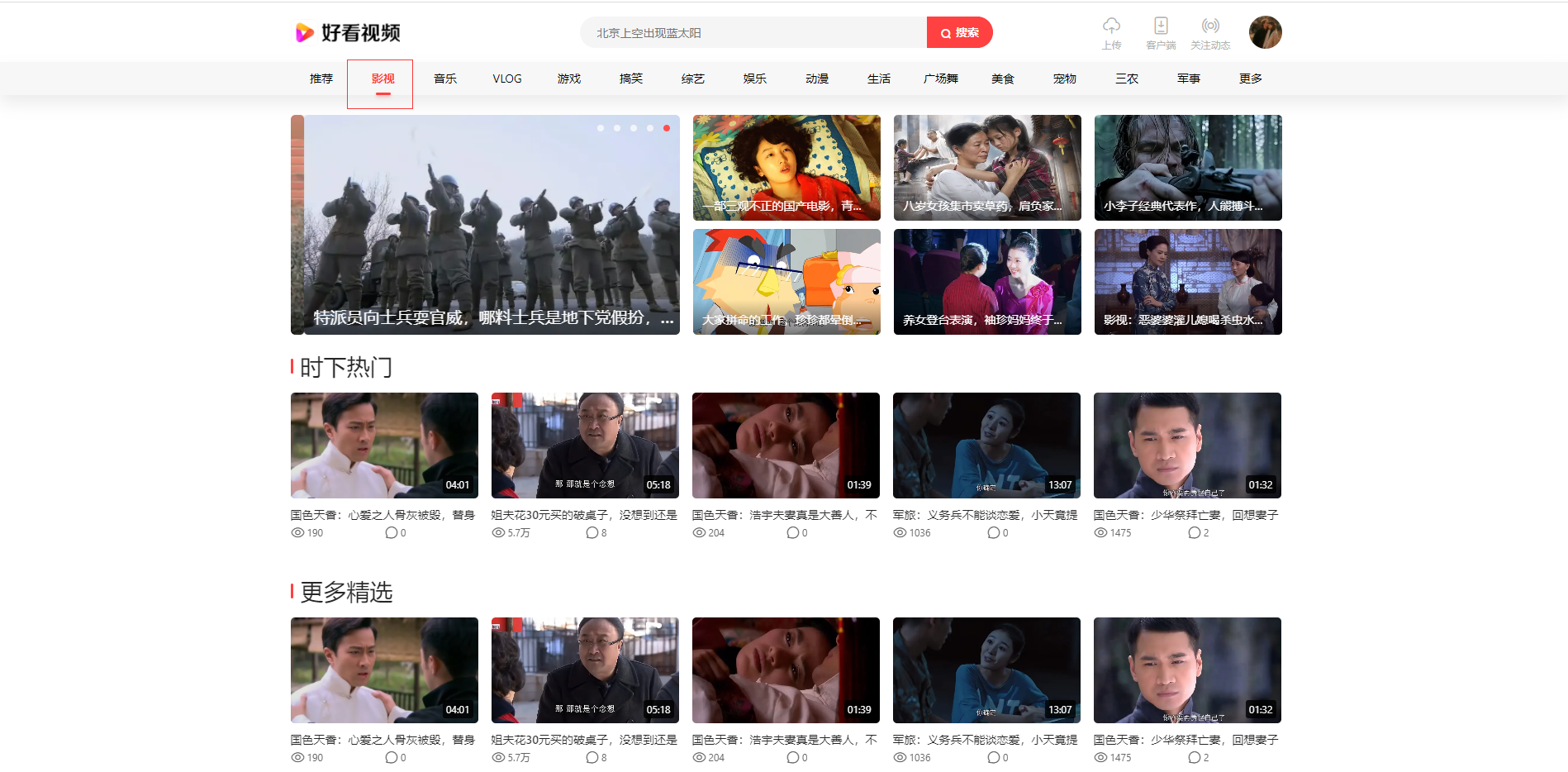

https://haokan.baidu.com/videoui/api/videorec?tab=yingshi&act=pcFeed&pd=pc&num=20&shuaxin_id=1608879736528
相关的数据都在这个链接里面。
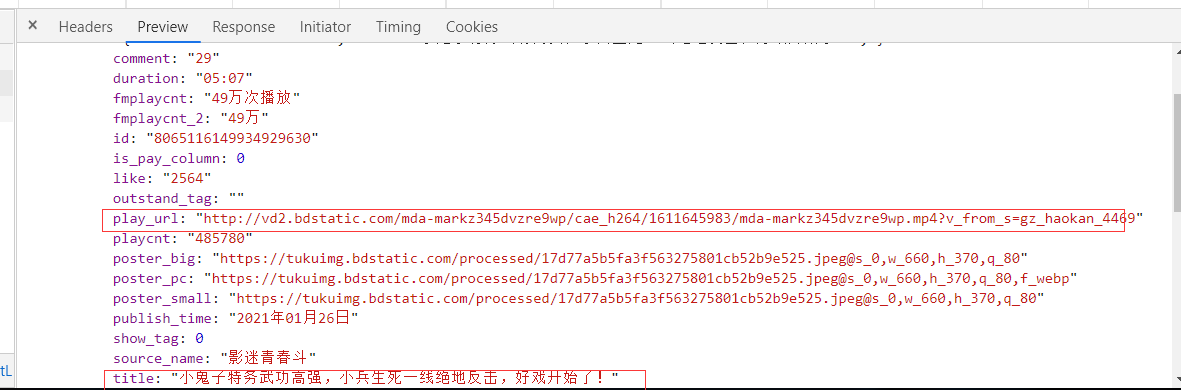
play_url:就是视频url地址
title:就是视频标题
根据键值对取值的方式,提取视频地址以及标题即可。

可以发现其实每个数据地址都是一样的,但是里面的内容不一样,如果想要多写爬取,写一个死循环即可。
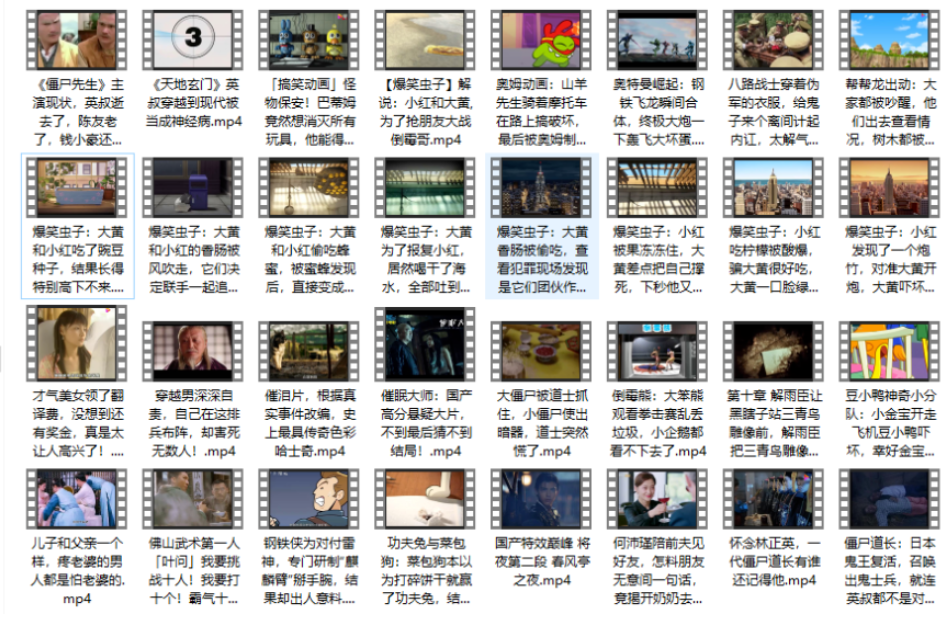
实现效果:
实现代码:
import pprint import requests import time while True: url = 'https://haokan.baidu.com/videoui/api/videorec' now_time = int(time.time() * 1000) params = { 'tab': 'yingshi', 'act': 'pcFeed', 'pd': 'pc', 'num': '20', 'shuaxin_id': now_time, } headers = { 'cookie': '添加自己的cookie', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36' } response = requests.get(url=url, params=params, headers=headers) html_data = response.json() videos = html_data['data']['response']['videos'] for i in videos: video_url = i['play_url'] video_title = i['title'] video_data = requests.get(url=video_url, headers=headers).content with open('video\' + video_title + '.mp4', mode='wb') as f: f.write(video_data) print('正在保存:', video_title)