1.所需jar包
<!--PDF转图片-->
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.20</version>
</dependency>
如果需要改变字体的话,还需要加上这个:
<!-- https://mvnrepository.com/artifact/org.apache.pdfbox/fontbox -->
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>fontbox</artifactId>
<version>2.0.9</version>
</dependency>
2.代码实现
通过Apache的pdfbox实现
/*
* PDF转图片
* @attention: 将整个PDF文件转图片(所有页)
* @date: 2021-05-12 10:46
* @param: imgPath
* 图片全路径
* @param: imgNamePrefix
* 图片名称前缀
* @param: pdfBytes
* PDF二进制流
* @return: boolean
*/
public static boolean toImageFromBytes(String imgPath, String imgNamePrefix, byte[] pdfBytes) {
return toImageFromBytes(imgPath, imgNamePrefix,"png", pdfBytes);
}
/*
* PDF转图片
* @attention:
* @date: 2021-06-21 14:46
* @param: imgPath
* @param: imgNamePrefix
* @param: pdfBytes
* @param: imgType
* @return: boolean
*/
public static boolean toImageFromBytes(String imgPath, String imgNamePrefix, String imgType, byte[] pdfBytes) {
return toImageFromBytes(imgPath, imgNamePrefix, imgType, pdfBytes, 0, -1);
}
/*
* PDF转图片
* @attention: 支持自主选择起始页和结束页
* @date: 2021-05-12 10:41
* @param: imgPath
* 图片全路径
* @param: imgNamePrefix
* 图片名称前缀
* @param: imgType
* 图片类型
* @param: pdfBytes
* PDF二进制流
* @param: pageStartIndex
* 开始页:开始转换的页码(第1页,页码为0)
* @param: pageEndIndex
* 结束页:结束转换的页码(最后1页,页码为-1)
* @return: boolean
* 只有PDF文件所有页数转换成功才返回true
*/
public static boolean toImageFromBytes(String imgPath, String imgNamePrefix, String imgType, byte[] pdfBytes, int pageStartIndex, int pageEndIndex) {
if (StringUtils.isEmpty(imgPath)) {
log.info("图片保存路径不能为空");
return false;
}
if (StringUtils.isEmpty(imgNamePrefix)) {
log.info("图片名称不能为空");
return false;
}
if (pdfBytes == null) {
log.info("pdf字节数组不能为空");
return false;
}
if (StringUtils.isEmpty(imgType)) {
log.info("图片格式不能为空");
return false;
}
if (pageStartIndex < -1 || pageEndIndex < -1) {
log.info("PDF转图片的起始页或结束页必须>=-1");
return false;
}
if (pageEndIndex != -1 && pageStartIndex > pageEndIndex) {
log.info("PDF转图片的起始页不能>结束页");
return false;
}
// 图片类型处理
if (!imgType.startsWith(".")) imgType = "." + imgType;
// 图片名称处理(注意文件名里不要有点,否则一律视为后缀名被抹掉)
if (imgNamePrefix.indexOf(".") > 0) imgNamePrefix = imgNamePrefix.substring(0, imgNamePrefix.indexOf(".") );
// 添加路径分隔符
if (!imgPath.endsWith("/") && !imgPath.endsWith("\")) imgPath += File.separator;
try {
// Date:2021-05-24
// 创建图片目录(确保图片的上级目录存在)
File directory = new File(imgPath);
// 目录不存在就创建
directory.mkdirs();
// 加载PDF
PDDocument doc = PDDocument.load(pdfBytes);
PDFRenderer renderer = new PDFRenderer(doc);
// pdf总页数
int pageCount = doc.getNumberOfPages();
log.info("该pdf文件共有" + pageCount + "页");
// 如果是起始页是末页的话,设置首页的下标索引(末页页码-1)
if (pageStartIndex == -1) {
pageStartIndex = pageCount - 1;
}
// 如果是结束页是末页的话,设置末页的下标索引(末页页码-1)
if (pageEndIndex == -1) {
pageEndIndex = pageCount - 1;
}
for (int i = pageStartIndex; i <= pageEndIndex; i++) {
// dpi越大转换后越清晰,相对转换速度越慢
BufferedImage image = renderer.renderImageWithDPI(i, 250); // Windows native DPI
// BufferedImage srcImage = resize(image, 240, 240);//产生缩略图
// 生成图片
// Date:2021-06-21
// ImageIO.write()第二个参数代表图片的类型,不能带".",否则图片生成失败
if (pageCount == 1)
ImageIO.write(image, imgType.substring(1), new File(imgPath + imgNamePrefix + imgType));
else
ImageIO.write(image, imgType.substring(1), new File(imgPath + imgNamePrefix + "_" + (i + 1) + imgType));
log.info("pdf第" + (i + 1) + "页转图片成功");
}
log.info("pdf-->图片成功(起始页:" + (pageStartIndex + 1) + ",结束页:" + (pageEndIndex + 1) + ")");
return true;
} catch (IOException e) {
e.printStackTrace();
log.error("pdf-->图片失败:" + e.getMessage());
return false;
}
}
3.调用
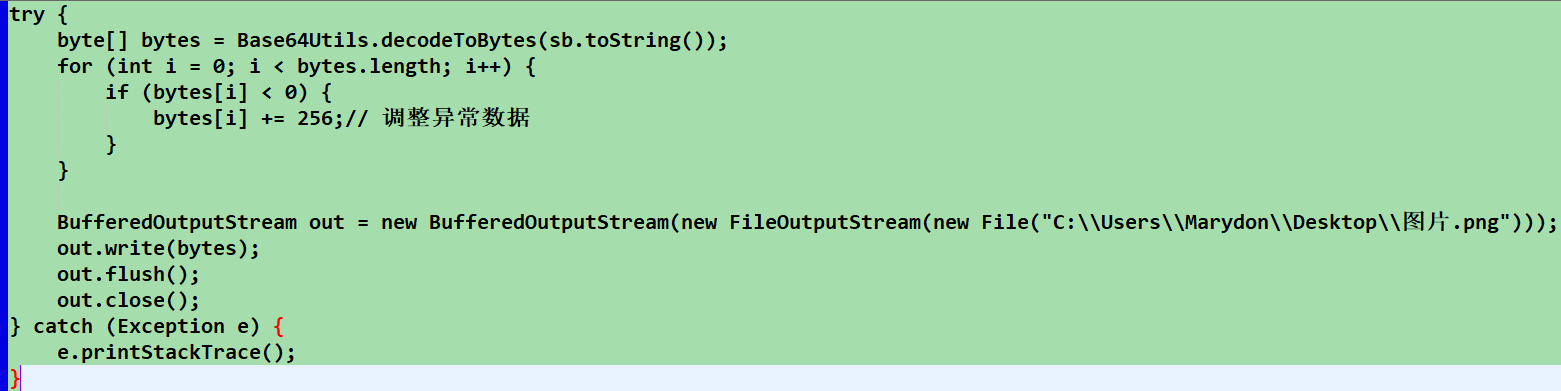
toImageFromBytes("C:\Users\Marydon\Desktop", "图片", Base64Utils.decodeToBytes(sb.toString()));
注意:
我曾尝试直接将PDF数据强制输出到图片文件中,结果发现这样是行不通的(生成的图片文件无法打开)
这,也就证明了PDF的数据流和图片的数据流,虽然都可以通过java转换成流,但两个本质还是不一样的。
2021-06-21
4.补充
增加PDF文件直接转图片的方法,其核心点在于:文件转bytes[]
/*
* pdf文件转img
* @attention:
* @date: 2021-06-21 16:38
* @param: pdfCompletePath
* @param: saveImgPath
* @param: imgName
* @return: boolean
*/
public static boolean toImageFromFile(String pdfCompletePath, String saveImgPath, String imgName) {
if (StringUtils.isEmpty(pdfCompletePath)) {
log.info("PDF文件所在完整路径不能为空");
return false;
}
// 设置图片路径
if (StringUtils.isEmpty(saveImgPath)) {
saveImgPath = "D:" + File.separator;
}
// 设置图片名称
if (StringUtils.isEmpty(imgName)) imgName = DateUtils.getSysdateStr("yyyyMMddHHmmssSSS");
return toImageFromFile(pdfCompletePath, saveImgPath, imgName, ".png");
}
/*
* pdf文件转img
* @attention:
* @date: 2021-06-21 16:38
* @param: pdfCompletePath
* @param: saveImgPath
* @param: imgName
* @param: imgType
* @return: boolean
*/
public static boolean toImageFromFile(String pdfCompletePath, String saveImgPath, String imgName, String imgType) {
return toImageFromFile(pdfCompletePath, saveImgPath, imgName, imgType,0, -1);
}
/*
* pdf文件转img
* @attention:
* @date: 2021-06-21 16:25
* @param: pdfCompletePath pdf完整路径
* @param: imgPath 图片路径
* @param: imgName 图片名称
* @param: imgType 图片类型
* @param: pageStartIndex PDF的起始页
* 开始转换的页码(第1页,页码为0)
* @param: pageEndIndex PDF的结束页
* 结束页:结束转换的页码(最后1页,页码为-1)
* @return: boolean
*/
public static boolean toImageFromFile(String pdfCompletePath, String imgPath, String imgName, String imgType, int pageStartIndex, int pageEndIndex) {
if (StringUtils.isEmpty(pdfCompletePath)) {
log.info("PDF文件所在完整路径不能为空");
return false;
}
if (StringUtils.isEmpty(imgPath)) {
log.info("图片保存路径不能为空");
return false;
}
if (StringUtils.isEmpty(imgName)) {
log.info("图片名称不能为空");
return false;
}
if (StringUtils.isEmpty(imgType)) {
log.info("图片类型不能为空");
return false;
}
byte[] pdfBytes = null;
try {
// 文件转文件流
pdfBytes = Files.readAllBytes(Paths.get(pdfCompletePath));
} catch (IOException e) {
log.error("PDF文件-->Bytes[]失败:" + e.getMessage());
e.printStackTrace();
return false;
}
return toImageFromBytes(imgPath, imgName, imgType, pdfBytes, pageStartIndex, pageEndIndex);
}
调用:
toImageFromFile("C:\Users\Marydon\Desktop\个人信用报告.pdf","C:\Users\Marydon\Desktop","cc", "png", -1, -1);