一. WEB应用模式
在开发Web应用中,有两种应用模式:
1. 前后端不分离
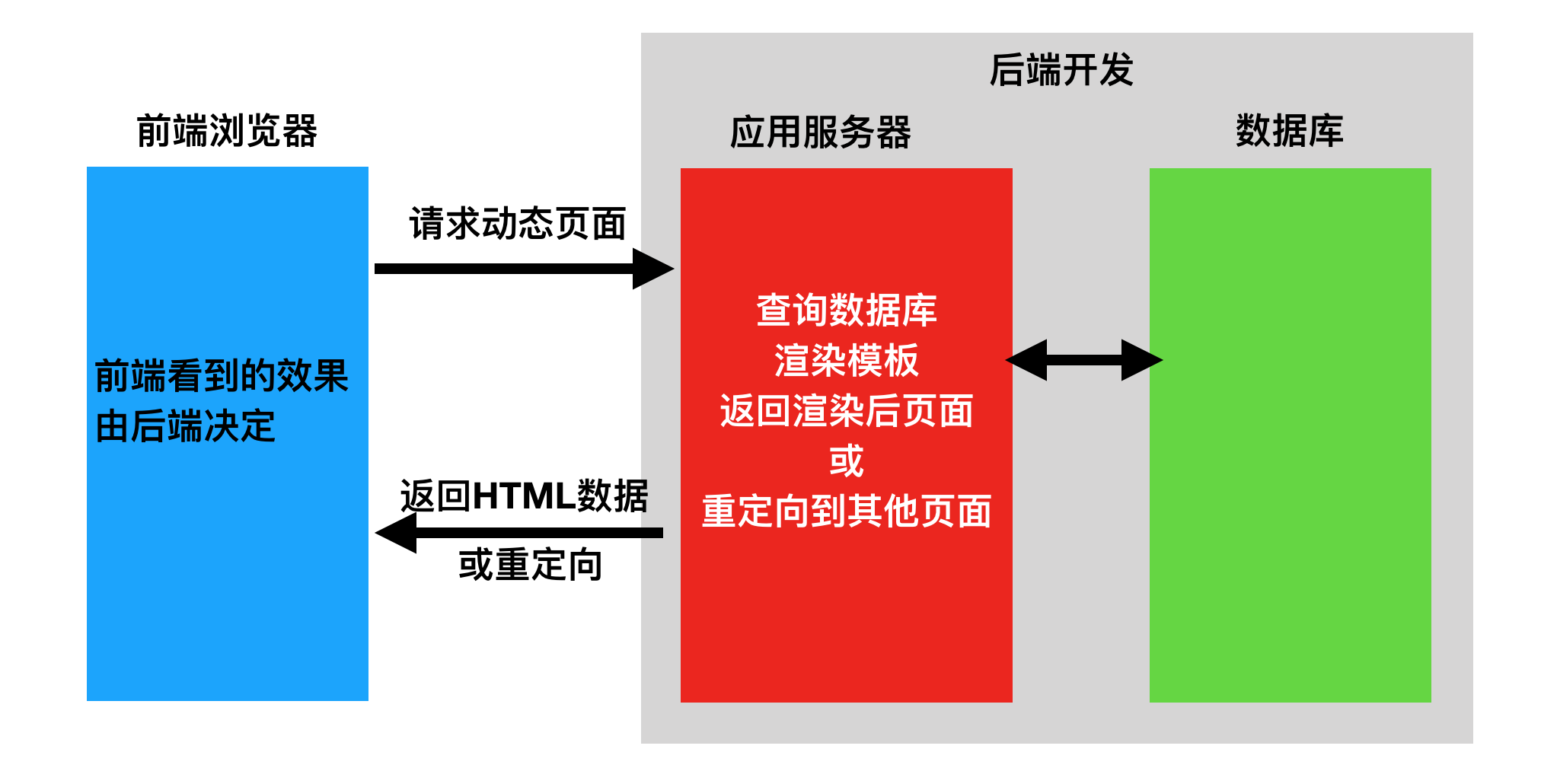
2. 前后端分离
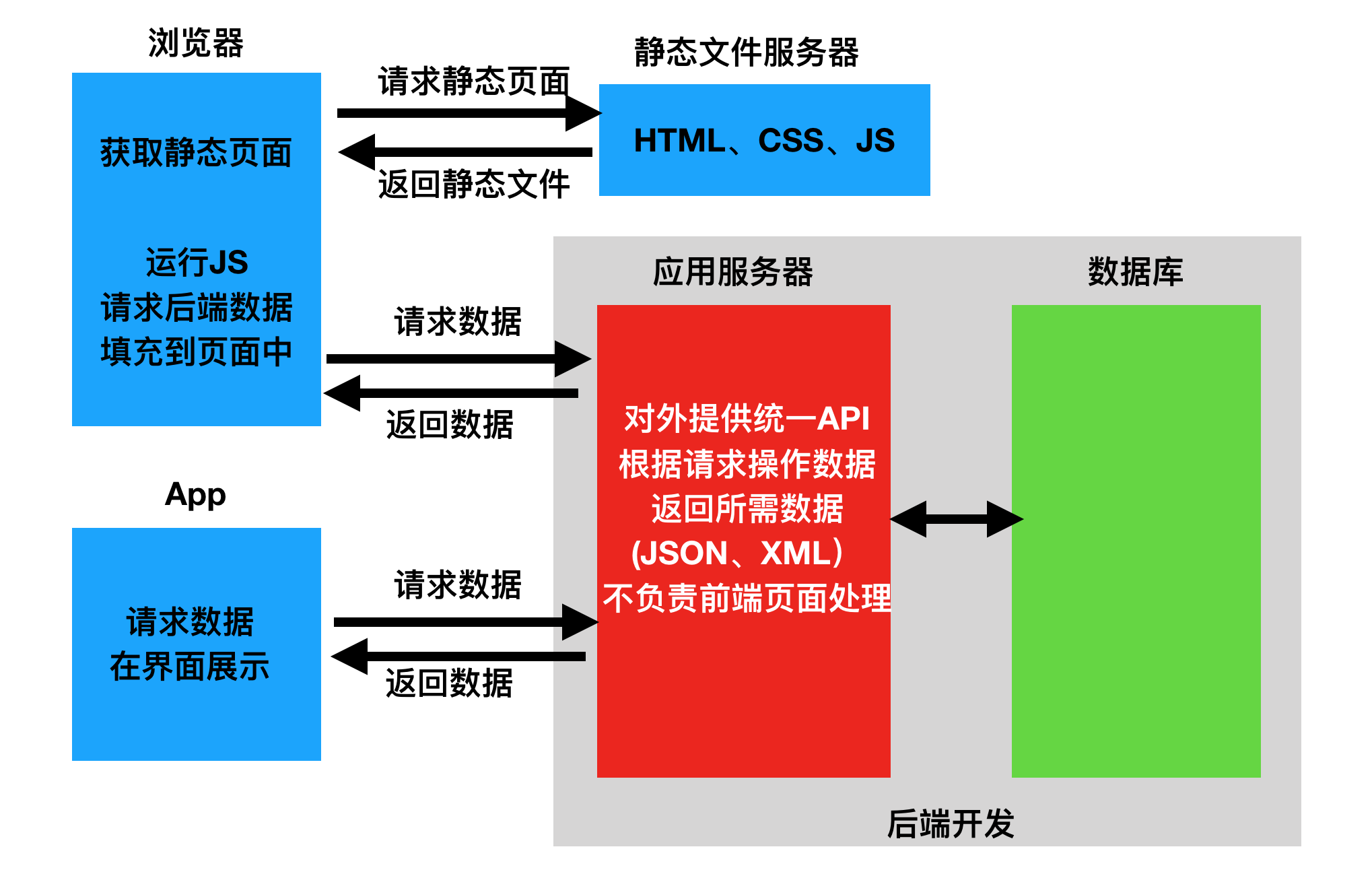
二. API接口
为了在团队内部形成共识、防止个人习惯差异引起的混乱,我们需要找到一种大家都觉得很好的接口实现规范,而且这种规范能够让后端写的接口,用途一目了然,减少双方之间的合作成本。
目前市面上大部分公司开发人员使用的接口服务架构主要有:restful、rpc。
1. rpc
rpc: 翻译成中文:远程过程调用[远程服务调用].
http://www.luffy.com/api
post请求
action=get_all_student¶ms=301&sex=1
接口多了,对应函数名和参数就多了,前端在请求api接口时,就会比较难找.容易出现重复的接口
2. restful
restful: 翻译成中文: 资源状态转换.
那么接口请求数据,本质上来说就是对资源的操作了.
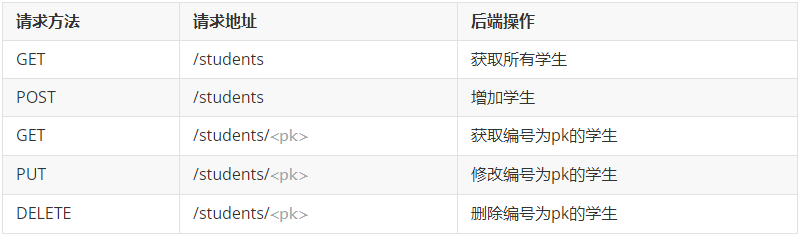
web项目中操作资源,无非就是增删查改.所以要求在地址栏中声明要操作的资源是什么,然后通过http请求动词来说明对资源进行哪一种操作.
POST http://www.luffy.com/api/students/ 添加学生数据
GET http://www.luffy.com/api/students/ 获取所有学生
DELETE http://www.luffy.com/api/students/<pk> 删除1个学生
三. RESTful API规范

REST全称是Representational State Transfer,中文意思是表述(编者注:通常译为表征)性状态转移。 它首次出现在2000年Roy Fielding的博士论文中。
RESTful是一种定义Web API接口的设计风格,尤其适用于前后端分离的应用模式中。
这种风格的理念认为后端开发任务就是提供数据的,对外提供的是数据资源的访问接口,所以在定义接口时,客户端访问的URL路径就表示这种要操作的数据资源。而对于数据资源分别使用POST、DELETE、GET、UPDATE等请求动作来表达对数据的增删查改。
事实上,我们可以使用任何一个框架都可以实现符合restful规范的API接口。
参考文档:http://www.runoob.com/w3cnote/restful-architecture.html
四. 序列化
api接口开发,最核心最常见的一个过程就是序列化,所谓序列化就是把数据转换格式。
序列化可以分两个阶段:
序列化
把我们识别的数据转换成指定的格式提供给别人。
例如:我们在django中获取到的数据默认是模型对象,但是模型对象数据无法直接提供给前端或别的平台使用,所以我们需要把数据进行序列化,变成字符串或者json数据,提供给别人。
反序列化
把别人提供的数据转换/还原成我们需要的格式。
例如:前端js提供过来的json数据,对于python而言就是字符串,我们需要进行反序列化换成模型类对象,这样我们才能把数据保存到数据库中。
五. Django Rest_Framework
核心思想: 缩减编写api接口的代码
Django REST framework是一个建立在Django基础之上的Web 应用开发框架,可以快速的开发REST API接口应用。
在REST framework中,提供了序列化器Serializer的定义,可以帮助我们简化序列化与反序列化的过程,不仅如此,还提供丰富的类视图、扩展类、视图集来简化视图的编写工作。
REST framework提供了认证、权限、限流、过滤、分页、接口文档等功能支持。
REST framework提供了一个API 的Web可视化界面来方便查看测试接口。

中文文档:https://q1mi.github.io/Django-REST-framework-documentation/#django-rest-framework
github: https://github.com/encode/django-rest-framework/tree/master
特点:
-
-
提供了定义序列化器Serializer的方法,可以快速根据 Django ORM 或者其它库自动序列化/反序列化;
-
提供了丰富的类视图、Mixin扩展类,简化视图的编写;
-
丰富的定制层级:函数视图、类视图、视图集合到自动生成 API,满足各种需要;
-
多种身份认证和权限认证方式的支持;[jwt]
-
内置了限流系统;
-
直观的 API web 界面;
-
可扩展性,插件丰富
-
六. 环境安装与配置
DRF需要以下依赖:
-
Python (2.7, 3.2, 3.3, 3.4, 3.5, 3.6)
-
Django (1.10, 1.11, 2.0)
DRF是以Django扩展应用的方式提供的,所以我们可以直接利用已有的Django环境而无需从新创建。(若没有Django环境,需要先创建环境安装Django)
1. 安装DRF
前提是已经安装了django,建议安装在虚拟环境。虚拟环境参考地址
# 注意:切换到对应目录下执行 # mkvirtualenv drfdemo -p python3 # pip install django pip install djangorestframework pip install pymysql
2. 创建一个Django项目
django-admin startproject drfdemo
使用pycharm打开项目,设置虚拟环境的解释器。
3. 添加rest_framework应用
INSTALLED_APPS = [
...
'rest_framework',
]
接下来就可以使用DRF提供的功能进行api接口开发了。在项目中如果使用rest_framework框架实现API接口,主要有以下三个步骤:
-
将请求的数据(如JSON格式)转换为模型类对象
-
操作数据库
-
接下来,我们快速体验下四天后我们学习完成drf以后的开发代码。接下来代码不需要理解,看步骤。
4. 体验DRF完全简写代码的过程
1. 创建模型类(此时项目还没有app,自行创建)
class Student(models.Model):
# 模型字段
name = models.CharField(max_length=100,verbose_name="姓名")
sex = models.BooleanField(default=1,verbose_name="性别")
age = models.IntegerField(verbose_name="年龄")
class_null = models.CharField(max_length=5,verbose_name="班级编号")
description = models.TextField(max_length=1000,verbose_name="个性签名")
class Meta:
db_table="tb_student"
verbose_name = "学生"
verbose_name_plural = verbose_name
回忆之前所学的Django使用MySQL数据库的步骤执行。
2. 创建序列化器
例如,我们在django项目中创建学生子应用。
python3 manage.py startapp students
在syudents应用目录中新建serializers.py用于保存该应用的序列化器。
创建一个StudentModelSerializer用于序列化与反序列化。
from rest_framework import serializers
from students.models import Student
# 创建序列化器类,回头会在视图中被调用
class StudentModelSerializer(serializers.ModelSerializer):
class Meta:
model = Student
fields = "__all__"
# fields = ("id", "name") # 也可指定字段
-
-
fields 指明该序列化器包含模型类中的哪些字段,'all'指明包含所有字段
3. 编写视图
在students应用的views.py中创建视图StudentViewSet,这是一个视图集合。
from rest_framework.viewsets import ModelViewSet
from students.models import Student
from students.serializers import StuentModelSerializer
class StuentAPIView(ModelViewSet):
queryset = Student.objects.all()
serializer_class = StuentModelSerializer
-
-
serializer_class 指明该视图在进行序列化或反序列化时使用的序列化器
4. 定义路由
在students应用的urls.py中定义路由信息。
from rest_framework.routers import DefaultRouter
from students import views
urlpatterns = [] # 路由列表
router = DefaultRouter() # 可以处理视图的路由器
router.register('student', views.StuentAPIView) # url进行注册
urlpatterns += router.urls # 将路由器中的所有路由信息追加到django的路由列表中
最后把students子应用中的路由文件加载到总路由文件中.
urlpatterns = [
path('admin/', admin.site.urls),
path('drf/', include("students.urls")),
]
5. 运行测试
运行当前程序(与运行Django一样)
python3 manage.py runserver
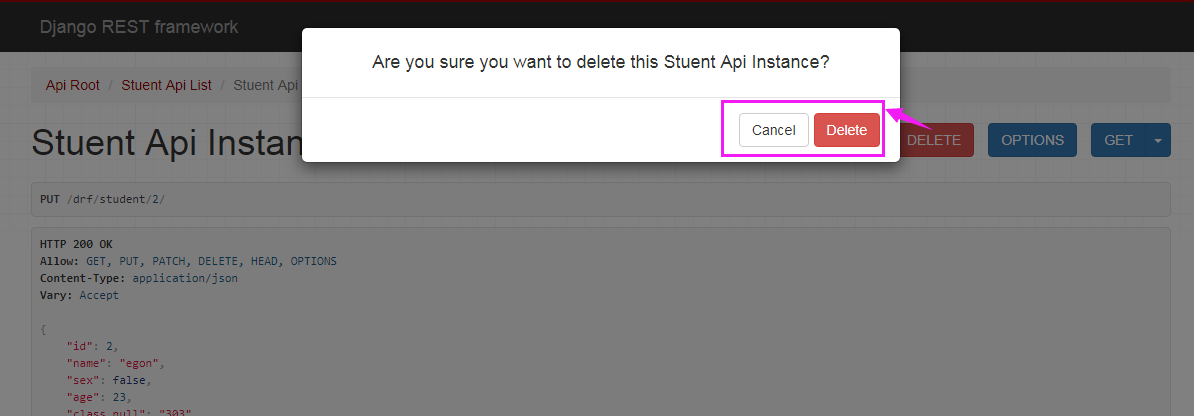
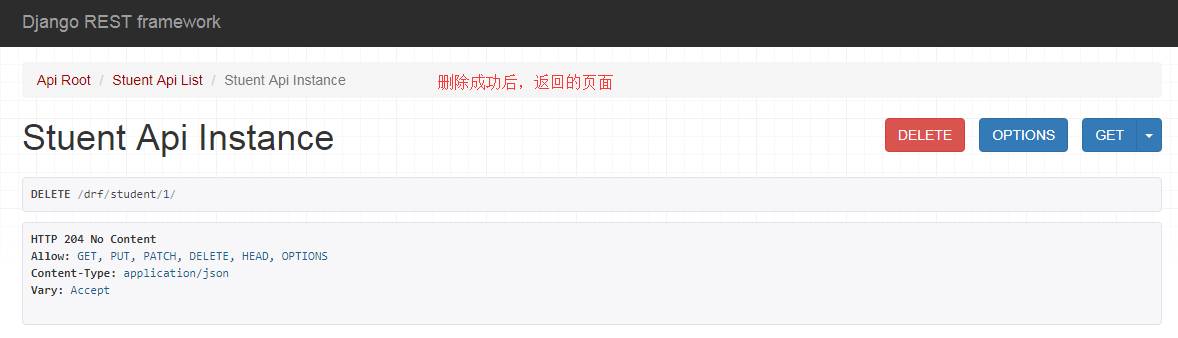
在浏览器中输入网址: 127.0.0.1:8000/drf/,可以看到DRF提供的API Web浏览页面:
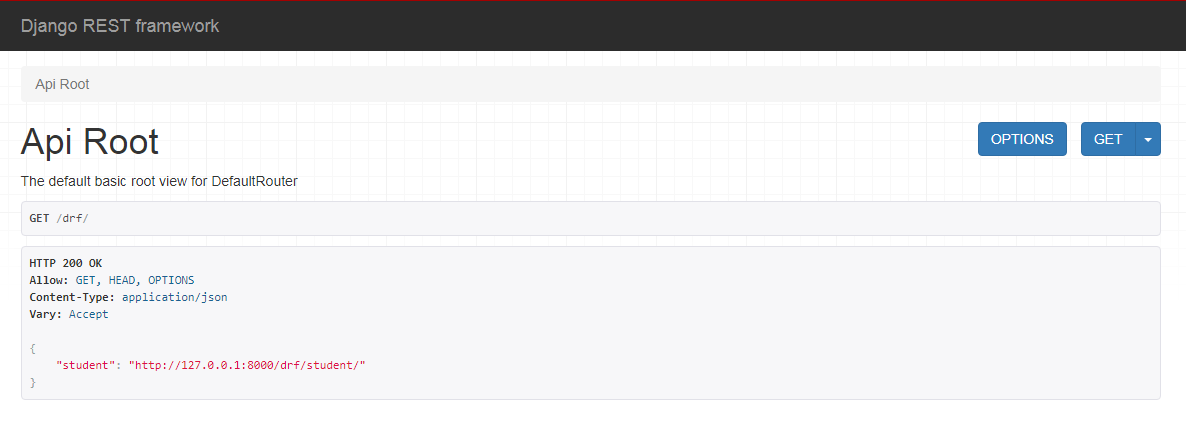
在浏览器中输入网址:
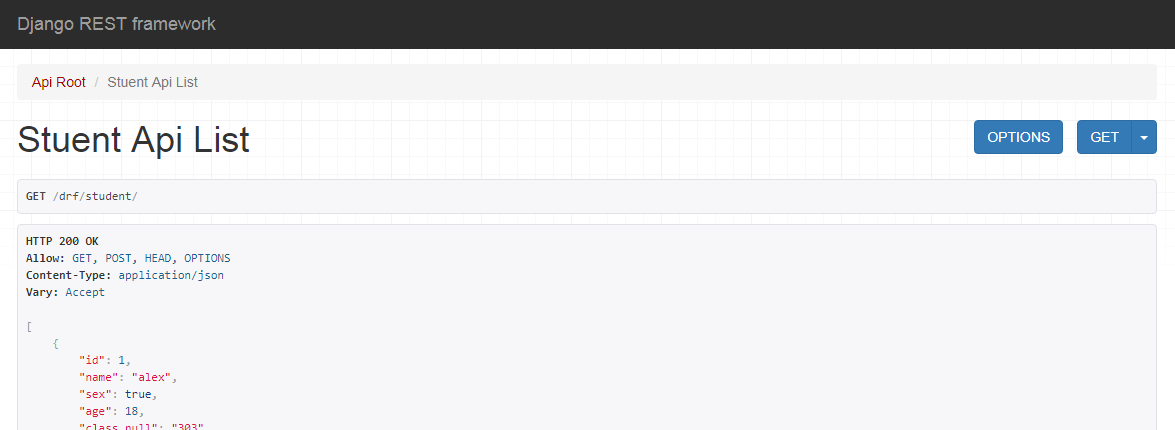
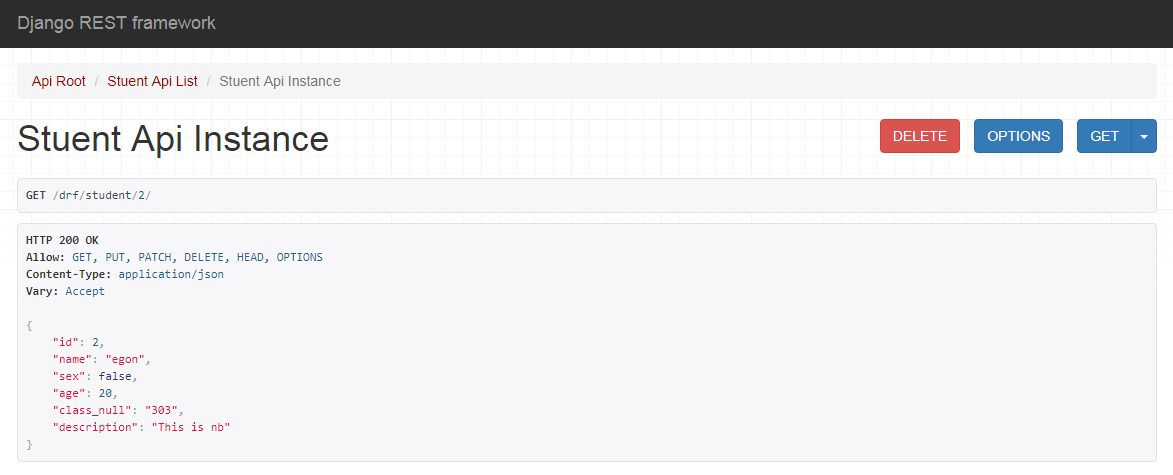
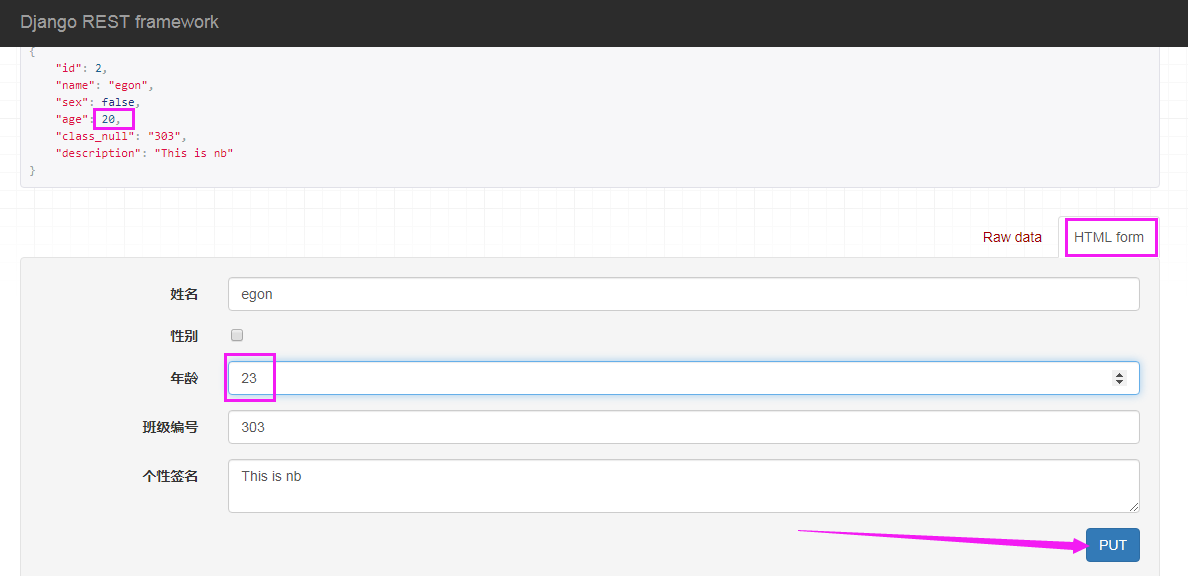
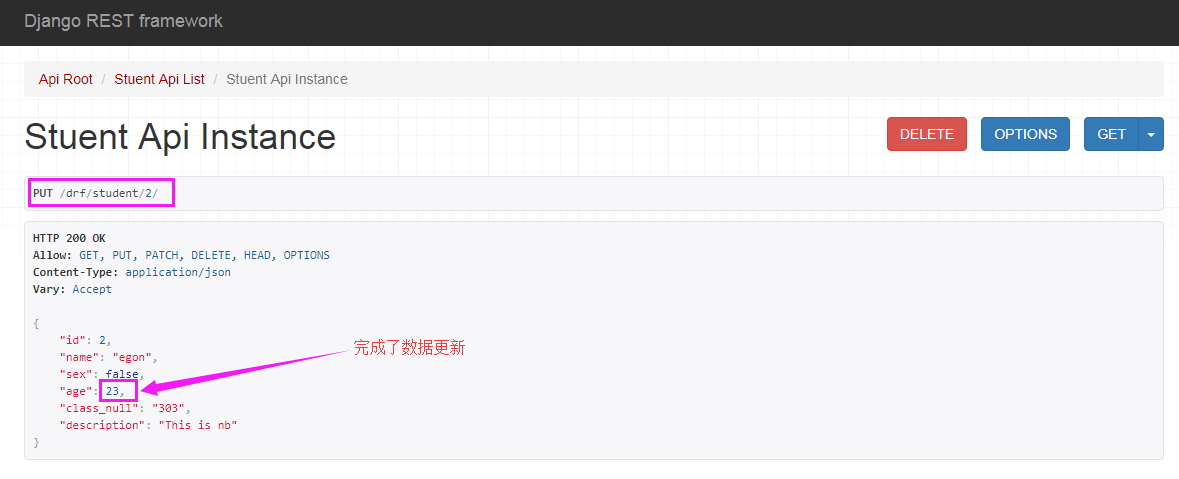
点击PUT,返回如下页面信息:
七. 序列化器-Serializer
作用:
1. 序列化,序列化器会把模型对象转换成字典,经过response以后变成json字符串
2. 反序列化,把客户端发送过来的数据,经过request以后变成字典,序列化器可以把字典转成模型
3. 反序列化,完成数据校验功能
1. 定义序列化器
Django REST framework中的Serializer使用类来定义,须继承自rest_framework.serializers.Serializer。
python manage.py startapp ser
我们还是继续使用student下的模型类。
下面我们为这个模型类提供一个序列化器,可以定义如下:
from rest_framework import serializers
# 所有的自定义序列化器必须直接或间接继承于 serializers.Serializer
class StudentSerializer(serializers.Serializer):
# 声明序列化器
# 1. 字段声明[ 要转换的字段,当然,如果写了第二部分代码,有时候也可以不用写字段声明 ]
id = serializers.IntegerField()
name = serializers.CharField()
sex = serializers.BooleanField()
age = serializers.IntegerField()
class_null = serializers.CharField()
description = serializers.CharField()
# 2. 可选[ 如果序列化器继承的是ModelSerializer,则需要声明对应的模型和字段, ModelSerializer是Serializer的子类 ]
# 3. 可选[ 用于对客户端提交的数据进行验证 ]
# 4. 可选[ 用于把通过验证的数据进行数据库操作,保存到数据库 ]
| 字段 | 字段构造方式 |
|---|---|
| BooleanField | BooleanField() |
| NullBooleanField | NullBooleanField() |
| CharField | CharField(max_length=None, min_length=None, allow_blank=False, trim_whitespace=True) |
| EmailField | EmailField(max_length=None, min_length=None, allow_blank=False) |
| RegexField | RegexField(regex, max_length=None, min_length=None, allow_blank=False) |
| SlugField | SlugField(maxlength=50, min_length=None, allow_blank=False) 正则字段,验证正则模式 [a-zA-Z0-9-]+ |
| URLField | URLField(max_length=200, min_length=None, allow_blank=False) |
| UUIDField |
UUIDField(format='hex_verbose') format: 1)'hex_verbose'如"5ce0e9a5-5ffa-654b-cee0-1238041fb31a" 2)'hex' 如 "5ce0e9a55ffa654bcee01238041fb31a" 3)'int' 如:"123456789012312313134124512351145145114" 4)'urn' 如:"urn:uuid:5ce0e9a5-5ffa-654b-cee0-1238041fb31a" |
| IPAddressField | IPAddressField(protocol='both', unpack_ipv4=False, **options) |
| IntegerField | IntegerField(max_value=None, min_value=None) |
| FloatField | FloatField(max_value=None, min_value=None) |
| DecimalField | DecimalField(max_digits, decimal_places, coerce_to_string=None, max_value=None, min_value=None) max_digits: 最多位数 decimal_palces: 小数点位置 |
| DateTimeField | DateTimeField(format=api_settings.DATETIME_FORMAT, input_formats=None) |
| DateField | DateField(format=api_settings.DATE_FORMAT, input_formats=None) |
| TimeField | TimeField(format=api_settings.TIME_FORMAT, input_formats=None) |
| DurationField | DurationField() |
| ChoiceField | ChoiceField(choices) choices与Django的用法相同 |
| MultipleChoiceField | MultipleChoiceField(choices) |
| FileField | FileField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL) |
| ImageField | ImageField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL) |
| ListField | ListField(child=, min_length=None, max_length=None) |
| DictField | DictField(child=) |
选项参数:
| 参数名称 | 作用 |
|---|---|
| max_length | 最大长度 |
| min_lenght | 最小长度 |
| allow_blank | 是否允许为空 |
| trim_whitespace | 是否截断空白字符 |
| max_value | 最大值 |
| min_value | 最小值 |
通用参数:
| 参数名称 | 说明 |
|---|---|
| read_only | 表明该字段仅用于序列化输出,默认False |
| write_only | 表明该字段仅用于反序列化输入,默认False |
| required | 表明该字段在反序列化时必须输入,默认True |
| default | 反序列化时使用的默认值 |
| allow_null | 表明该字段是否允许传入None,默认False |
| validators | 该字段使用的验证器 |
| error_messages | 包含错误编号与错误信息的字典 |
| label | 用于HTML展示API页面时,显示的字段名称 |
| help_text | 用于HTML展示API页面时,显示的字段帮助提示信息 |
2. 创建Serializer对象
定义好Serializer类后,就可以创建Serializer对象了。
Serializer(instance=None, data=empty, **kwarg)
说明:
1)用于序列化时,将模型类对象传入instance参数
2)用于反序列化时,将要被反序列化的数据传入data参数
3)除了instance和data参数外,在构造Serializer对象时,还可通过context参数额外添加数据,如
serializer = StudentSerializer(student, context={'request': request})
通过context参数附加的数据,可以通过Serializer对象的context属性获取。
声明:
-
-
序列化器无法直接接收数据,需要我们在视图中创建序列化器对象时把使用的数据传递过来。
-
序列化器的字段声明类似于我们前面使用过的表单系统。
-
开发restful api时,序列化器会帮我们把模型数据转换成字典.
-
drf提供的视图会帮我们把字典转换成json,或者把客户端发送过来的数据转换字典.
序列化器的使用分两个阶段:
-
在客户端请求时,使用序列化器可以完成对数据的反序列化。
-
3.1 序列化
总路由中的urls.py:
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('drf/', include("students.urls")),
path('ser/', include("ser.urls")),
]
ser应用下的urls.py文件:
from django.urls import path, re_path
from . import views
urlpatterns = [
re_path(r"^student/(?P<pk>d+)/$", views.Student1View.as_view()),
]
ser应用下的views.py文件:
from django.http import JsonResponse
from django.views import View
from students.models import Student
from .serializers import StudentSerializer
class Student1View(View):
"""使用序列化器进行数据的序列化操作"""
"""序列化器转换一条数据[模型转换成字典]"""
def get(self, request, pk):
# 接收客户端传过来的参数,进行过滤查询,先查出学生对象
student = Student.objects.get(pk=pk)
# 转换数据类型
# 1.实例化序列化器类
"""
StudentSerializer(instance=模型对象或者模型列表,客户端提交的数据,额外要传递到序列化器中使用的数据)
"""
serializer = StudentSerializer(instance=student)
# 2.查看序列化器的转换结果
print(serializer.data)
return JsonResponse(serializer.data)
from django.urls import path, re_path
from . import views
urlpatterns = [
path("students/", views.Student2View.as_view()),
re_path(r"^student/(?P<pk>d+)/$", views.Student1View.as_view()),
]
ser应用下的views.py文件:
class Student2View(View):
"""序列化器转换多条数据[模型转换成字典]"""
def get(self, request):
student_list = Student.objects.all()
# 序列化器转换多个数据
# many=True 表示本次序列化器转换如果有多个模型对象列参数,则必须声明 Many=True
serializer = StudentSerializer(instance=student_list, many=True)
print(serializer.data)
return JsonResponse(serializer.data)
3.2.1 反序列化-数据校验
使用序列化器进行反序列化时,需要对数据进行验证后,才能获取验证成功的数据或保存成模型类对象。
在获取反序列化的数据前,必须调用is_valid()方法进行验证,验证成功返回True,否则返回False。
-
- 验证成功,可以通过序列化器对象的validated_data属性获取数据。
在定义序列化器时,指明每个字段的序列化类型和选项参数,本身就是一种验证行为。
ser应用下的serializers.py文件:
""" 在drf中,对于客户端提供的数据,往往需要验证数据的有效性,这部分代码是写在序列化器中的。 在序列化器中,已经提供三个地方给我们针对客户端提交的数据进行验证。 1. 内置选项,字段声明的小圆括号中,以选项存在作为验证提交 2. 自定义方法,在序列化器中作为对象方法来提供验证[ 这部分验证的方法,必须以"validate_<字段>" 或者 "validate" 作为方法名 ] 3. 自定义函数,在序列化器外部,提前声明一个验证代码,然后在字段声明的小圆括号中,通过 "validators=[验证函数1,验证函数2...]" """ def check_user(data): if data == "oldboy": raise serializers.ValidationError("用户名不能为oldboy!") return data class Student3Serializer(serializers.Serializer): # 声明序列化器 # 1. 字段声明[ 要转换的字段,当然,如果写了第二部分代码,有时候也可以不用写字段声明 ] name = serializers.CharField(max_length=10, min_length=4, validators=[check_user]) sex = serializers.BooleanField(required=True) age = serializers.IntegerField(max_value=150, min_value=0) # 2. 可选[ 如果序列化器继承的是ModelSerializer,则需要声明对应的模型和字段, ModelSerializer是Serializer的子类 ] # 3. 可选[ 用于对客户端提交的数据进行验证 ] """验证单个字段值的合法性""" def validate_name(self, data): if data == "root": raise serializers.ValidationError("用户名不能为root!") return data def validate_age(self, data): if data < 18: raise serializers.ValidationError("年龄不能小于18") return data """验证多个字段值的合法性""" def validate(self, attrs): name = attrs.get('name') age = attrs.get('age') if name == "alex" and age == 22: raise serializers.ValidationError("alex在22时的故事。。。") return attrs
ser应用下的urls.py文件:
urlpatterns = [ path("students/", views.Student2View.as_view()), re_path(r"^student/(?P<pk>d+)/$", views.Student1View.as_view()), # 对数据提交时,进行校验 path('student3/', views.Student3View.as_view()), ]
ser应用下的views.py文件:
class Student3View(View): def post(self, request): data = request.body.decode() # 反序列化用户提交的数据 data_dict = json.loads(data) print(data_dict) # 调用序列化器进行实例化 serializer = Student3Serializer(data=data_dict) # is_valid在执行的时候,会自动先后调用 字段的内置选项,自定义验证方法,自定义验证函数 # 调用序列化器中写好的验证代码 # raise_exception=True 抛出验证错误信息,并阻止代码继续往后运行 # 验证结果 print(serializer.is_valid(raise_exception=True)) # 获取验证后的错误信息 print(serializer.errors) # 获取验证后的客户端提交的数据 print(serializer.validated_data) # return HttpResponse(serializer.validated_data) return JsonResponse(serializer.validated_data)
3.2.2 反序列化-保存数据
前面的验证数据成功后,我们可以使用序列化器来完成数据反序列化的过程.这个过程可以把数据转成模型类对象.
可以通过在序列化器中实现create()和update()两个方法来实现。
class Student3Serializer(serializers.Serializer): # 声明序列化器 # 1. 字段声明[ 要转换的字段,当然,如果写了第二部分代码,有时候也可以不用写字段声明 ] name = serializers.CharField(max_length=10, min_length=4, validators=[check_user]) sex = serializers.BooleanField(required=True) age = serializers.IntegerField(max_value=150, min_value=0) # 2. 可选[ 如果序列化器继承的是ModelSerializer,则需要声明对应的模型和字段, ModelSerializer是Serializer的子类 ] # 3. 可选[ 用于对客户端提交的数据进行验证 ] """验证单个字段值的合法性""" def validate_name(self, data): if data == "root": raise serializers.ValidationError("用户名不能为root!") return data def validate_age(self, data): if data < 18: raise serializers.ValidationError("年龄不能小于18") return data """验证多个字段值的合法性""" def validate(self, attrs): name = attrs.get('name') age = attrs.get('age') if name == "alex" and age == 22: raise serializers.ValidationError("alex在22时的故事。。。") return attrs # 4. 可选[ 用于把通过验证的数据进行数据库操作,保存到数据库 ] def create(self, validated_data): """接受客户端提交的新增数据""" name = validated_data.get('name') age = validated_data.get('age') sex = validated_data.get('sex') instance = Student.objects.create(name=name, age=age, sex=sex) # instance = Student.objects.create(**validated_data) print(instance) return instance def update(self, instance, validated_data): """用于在反序列化中对于验证完成的数据进行保存更新""" name = validated_data.get('name') age = validated_data.get('age') sex = validated_data.get('sex') instance.name = name instance.age = age instance.sex = sex instance.save() return instance
实现了上述两个方法后,在反序列化数据的时候,就可以通过save()方法返回一个数据对象实例了
ser应用下views.py文件:
class Student3View(View): def post(self, request): data = request.body.decode() # 反序列化用户提交的数据 data_dict = json.loads(data) print(data_dict) # 调用序列化器进行实例化 serializer = Student3Serializer(data=data_dict) # is_valid在执行的时候,会自动先后调用 字段的内置选项,自定义验证方法,自定义验证函数 # 调用序列化器中写好的验证代码 # raise_exception=True 抛出验证错误信息,并阻止代码继续往后运行 # 验证结果 print(serializer.is_valid(raise_exception=True)) # 获取验证后的错误信息 print(serializer.errors) # 获取验证后的客户端提交的数据 print(serializer.validated_data) # save 表示让序列化器开始执行反序列化代码。create和update的代码 serializer.save() # return HttpResponse(serializer.validated_data) return JsonResponse(serializer.validated_data)
如果创建序列化器对象的时候,没有传递instance实例,则调用save()方法的时候,create()被调用,相反,如果传递了instance实例,则调用save()方法的时候,update()被调用。
class Student4View(View): def put(self, request, pk): data = request.body.decode() import json data_dict = json.loads(data) student_obj = Student.objects.get(pk=pk) # 有instance参数,调用save方法,就会调用update方法。 serializer = Student3Serializer(instance=student_obj, data=data_dict) serializer.is_valid(raise_exception=True) serializer.save() # 触发序列器中的update方法 return JsonResponse(serializer.validated_data)
ser应用下的urls.py文件:
urlpatterns = [ path("students/", views.Student2View.as_view()), re_path(r"^student/(?P<pk>d+)/$", views.Student1View.as_view()), # 对数据提交时,进行校验 path('student3/', views.Student3View.as_view()), # 反序列化阶段 re_path(r'^student4/(?P<pk>d+)/$', views.Student4View.as_view()), ]
3.3 序列化与反序列化合并使用
""" 开发中往往一个资源的序列化和反序列化阶段都是写在一个序列化器中的 所以我们可以把上面的两个阶段合并起来,以后我们再次写序列化器,则直接按照以下风格编写即可。 """ class Student5Serializer(serializers.Serializer): id = serializers.IntegerField(read_only=True) name = serializers.CharField(max_length=10, min_length=4, validators=[check_user]) sex = serializers.BooleanField(required=True) age = serializers.IntegerField(max_value=150, min_value=0) class_null = serializers.CharField(read_only=True) description = serializers.CharField(read_only=True) # 2. 可选[ 如果序列化器继承的是ModelSerializer,则需要声明对应的模型和字段, ModelSerializer是Serializer的子类 ] # 3. 可选[ 用于对客户端提交的数据进行验证 ] """验证单个字段值的合法性""" def validate_name(self, data): if data == "root": raise serializers.ValidationError("用户名不能为root!") return data def validate_age(self, data): if data < 18: raise serializers.ValidationError("年龄不能小于18") return data """验证多个字段值的合法性""" def validate(self, attrs): name = attrs.get('name') age = attrs.get('age') if name == "alex" and age == 22: raise serializers.ValidationError("alex在22时的故事。。。") return attrs # 4. 可选[ 用于把通过验证的数据进行数据库操作,保存到数据库 ] def create(self, validated_data): """接受客户端提交的新增数据""" name = validated_data.get('name') age = validated_data.get('age') sex = validated_data.get('sex') instance = Student.objects.create(name=name, age=age, sex=sex) # instance = Student.objects.create(**validated_data) print(instance) return instance def update(self, instance, validated_data): """用于在反序列化中对于验证完成的数据进行保存更新""" name = validated_data.get('name') age = validated_data.get('age') sex = validated_data.get('sex') instance.name = name instance.age = age instance.sex = sex instance.save() return instance
在ser应用下urls.py文件:
urlpatterns = [ path("students/", views.Student2View.as_view()), re_path(r"^student/(?P<pk>d+)/$", views.Student1View.as_view()), # 对数据提交时,进行校验 path('student3/', views.Student3View.as_view()), # 反序列化阶段 re_path(r'^student4/(?P<pk>d+)/$', views.Student4View.as_view()), # 一个序列化器同时实现序列化和反序列化 path('student5/', views.Student5View.as_view()), ]
在ser应用下views.py文件:
class Student5View(View): def get(self, request): # 获取所有数据 student_list = Student.objects.all() serializer = Student5Serializer(instance=student_list, many=True) return JsonResponse(serializer.data, safe=False) def post(self, request): data = request.body.decode() data_dict = json.loads(data) serializer = Student5Serializer(data=data_dict) serializer.is_valid(raise_exception=True) instance = serializer.save() return JsonResponse(serializer.data)
3.4 模型类序列化器
如果我们想要使用序列化器对应的是Django的模型类,DRF为我们提供了ModelSerializer模型类序列化器来帮助我们快速创建一个Serializer类。
在ser应用下serializers.py文件定义模型类序列化器:
""" 我们可以使用ModelSerializer来完成模型类序列化器的声明 这种基于ModelSerializer声明序列化器的方式有三个优势: 1. 可以直接通过声明当前序列化器中指定的模型中把字段声明引用过来 2. ModelSerializer是继承了Serializer的所有功能和方法,同时还编写update和create 3. 模型中同一个字段中关于验证的选项,也会被引用到序列化器中一并作为选项参与验证 """ class StudentModelSerializer(serializers.ModelSerializer): class Meta: model = Student # fields = "__all__" # 表示引用所有字段 fields = ["id", "name", "age", "class_null", "is_18"] # is_18 为自定制字段,需要在models里自定义方法。 # exclude = ["age"] # 使用exclude可以明确排除掉哪些字段, 注意不能和fields同时使用。 # 传递额外的参数,为ModelSerializer添加或修改原有的选项参数 extra_kwargs = { "name": {"max_length": 10, "min_length": 4, "validators": [check_user]}, "age": {"max_value": 150, "min_value": 0}, } def validate_name(self, data): if data == "root": raise serializers.ValidationError("用户名不能为root!") return data def validate(self, attrs): name = attrs.get('name') age = attrs.get('age') if name == "alex" and age == 22: raise serializers.ValidationError("alex在22时的故事。。。") return attrs
在ser应用下的urls.py文件:
urlpatterns = [ path("students/", views.Student2View.as_view()), re_path(r"^student/(?P<pk>d+)/$", views.Student1View.as_view()), # 对数据提交时,进行校验 path('student3/', views.Student3View.as_view()), # 反序列化阶段 re_path(r'^student4/(?P<pk>d+)/$', views.Student4View.as_view()), # 一个序列化器同时实现序列化和反序列化 path('student5/', views.Student5View.as_view()), # 使用模型类序列化器 path('student6/', views.Student6View.as_view()), ]
在ser应用下views.py文件:
class Student6View(View): def get(self, request): # 获取所有数据 student_list = Student.objects.all() serializer = StudentModelSerializer(instance=student_list, many=True) return JsonResponse(serializer.data, safe=False) def post(self, request): data = request.body.decode() data_dict = json.loads(data) serializer = StudentModelSerializer(data=data_dict) serializer.is_valid(raise_exception=True) serializer.save() return JsonResponse(serializer.data)