聚类概念:
无监督问题:我们手里没有标签了
聚类:相似的东西分到一组
难点:如何评估,如何调参
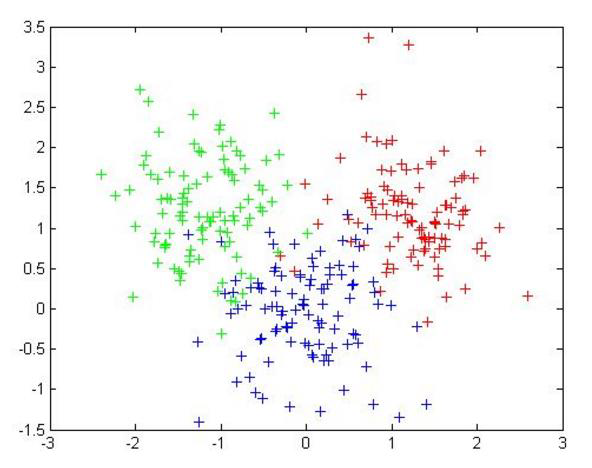
要得到簇的个数,需要指定K值
质心:均值,即向量各维取平均即可
距离的度量:常用欧几里得距离和余弦相似度(先标准化)
优化目标:

Ci是质心,x是数据,质心到数据的距离
工作流程:
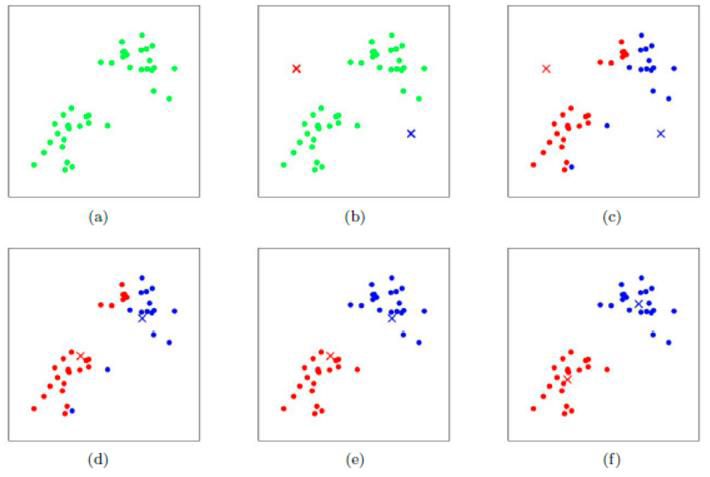
通过不断更新质心来确定类别。
例如c->d,红色质心和蓝色质心是在c聚类之后将质心更新为d,
再从d->e,d经过距离距离后得到了e,那么e的质心就不是e中的了,需要根据e的聚类结果,更新到f,
f,f无论如何更新质心,质心的位置都不会有太大的变化,就可以认为聚类工作完成。
优势:
简单,快速,适合常规数据集
劣势:
K值难确定
复杂度与样本呈线性关系
很难发现任意形状的簇
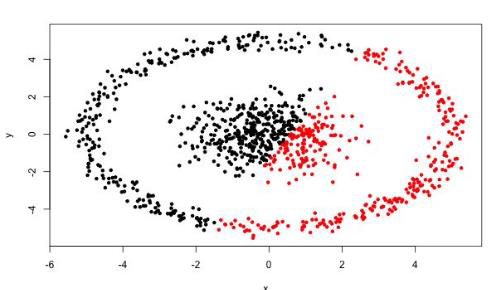
可视化聚类效果网站:
https://www.naftaliharris.com/blog/visualizing-k-means-clustering/

经过K-MEANS聚类的效果:
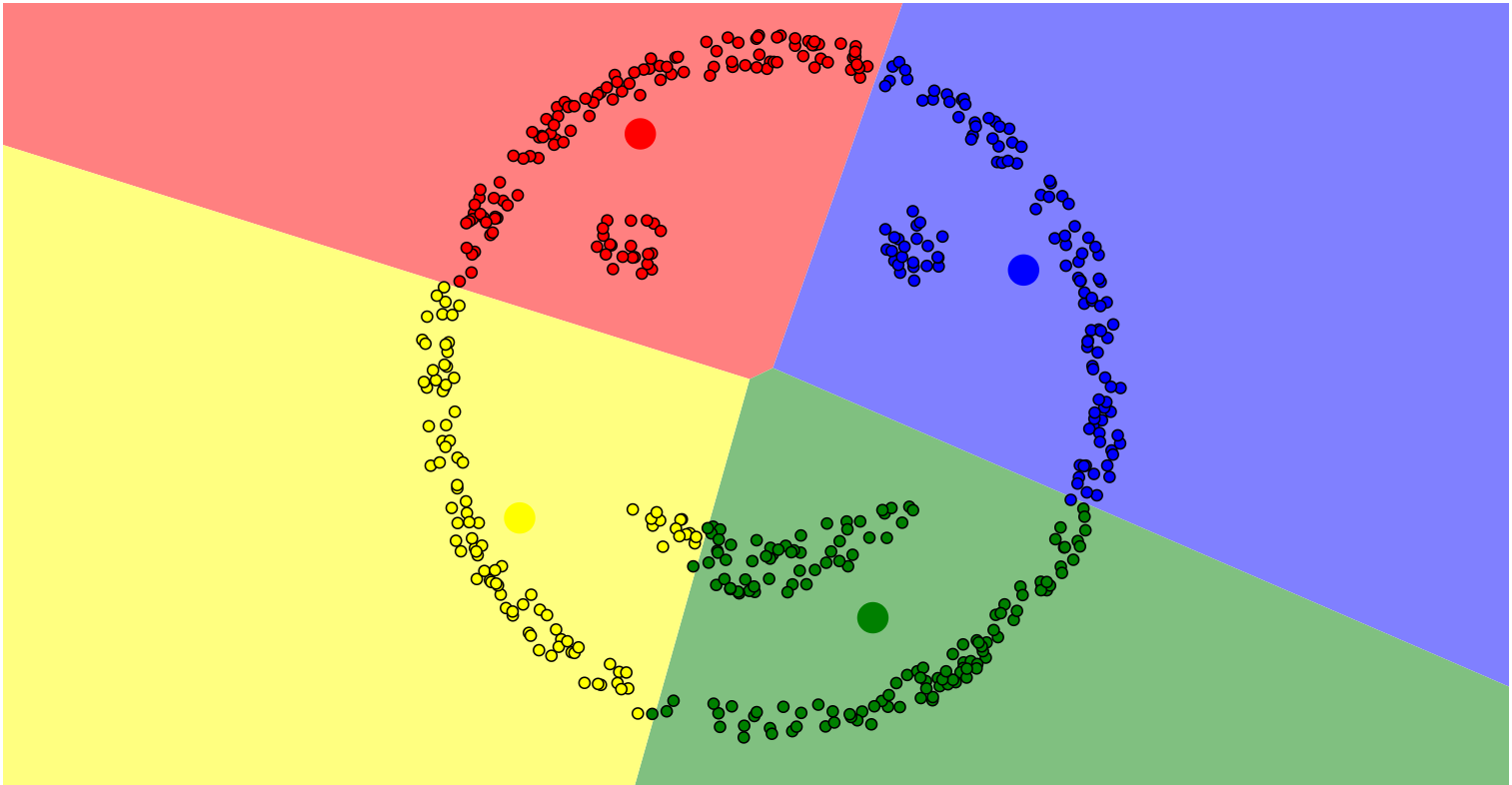
通过DBSCAN算法聚类的结果:
