实验一、词法分析实验
专业:商业软件工程2班 姓名 别博文 学号201606110175
一、 实验目的
编制一个词法分析程序。
二、 实验内容和要求
对字符串表示的源程序,从左到右进行扫描和分解,根据词法规则,识别出一个一个具有独立意义的单词符号,以供语法分析之用 发现词法错误,则返回出错信息。。
三、 实验方法、步骤及结果测试
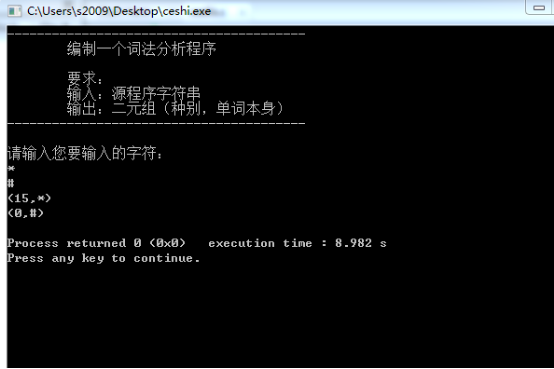
源程序名:压缩包文件(rar或zip)中源程序名 ceshi.c
可执行程序名:ceshi.exe
- 主要程序段及其解释:
实现主要功能的程序段,重要的是程序的注释解释。
#include<stdio.h>
#include<string.h>
char str[100];
char take[8];//存放单词符号的字符串
int sum;//存放整数型单词
char ch;
int zbm;//存放单词字符的种别码
int i,n,p,m=0;//p是缓冲区str的指针,m是take的指针
char *keyword[8]={"begin","if","then","while","do","end","l(l|d)*","dd*"};
void scanner()//词法扫描程序
{
/* for(i=0;i<8;i++)
{
take[i]=NULL;
}
ch=str[p++];*/
m=0;
sum=0;
for(m=0;m<8;m++)
take[m]=0;
ch=str[p++];
while(ch==' '||ch==' ')
{
ch=str[p++];
}
if((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z'))//可能是标识符或者是变量名
{
m=0;
while(ch>='0'&&ch<='9'||(ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z'))
{
take[m++]=ch;
ch=str[p++];
}
take[m++]='�';
p--;
zbm=10;
for(i=0;i<6;i++)//将识别出的字符和已定义的标符进行比较
if(strcmp(keyword[i],take==0))
{
zbm=i+1;
break;
}
}
else if(ch>='0'&&ch<='9')
{
while(ch>='0'&&ch<='9')
{
sum=sum*10+ch-'0';
ch=str[p++];
}
p--;
zbm=11;
}
else
{
switch(ch)
{
case '+':
zbm=13;
take[0]=ch;
ch=str[p++];
break;
case '-':
zbm=14;
take[0]=ch;
ch=str[p++];
break;
case '*':
zbm=15;
take[0]=ch;
ch=str[p++];
break;
case '/':
zbm=16;
take[0]=ch;
ch=str[p++];
break;
case '<':
take[m++]=ch;
ch=str[p++];
if(ch=='>')
{
zbm=21;
take[m++]=ch;
}
else if(ch=='=')
{
zbm=22;
take[m]=ch;
}
else{
zbm=20;
p--;
}
break;
case '>':
take[0]=ch;
ch=str[p++];
if(ch=='=')
{
zbm=24;
take[0]=ch;
}
else{
zbm=23;
p--;
}
break;
case ':':
take[0]=ch;
ch=str[p++];
if(ch=='=')
{
zbm=18;
take[m++]=ch;
ch=str[p++];
}
else{
zbm=17;
p--;
}
break;
case '=':
zbm=25;
take[0]=ch;
ch=str[p++];
break;
case ';':
zbm=26;
take[0]=ch;
ch=str[p++];
break;
case '(':
zbm=27;
take[0]=ch;
ch=str[p++];
break;
case ')':
zbm=28;
take[0]=ch;
ch=str[p++];
break;
case '#':
zbm=0;
take[0]=ch;
ch=str[p++];
break;
default:
zbm=-1;
}
}
}
main()
{
int n,i;
printf("---------------------------------------- ");
printf(" 编制一个词法分析程序 ");
printf(" 要求: ");
printf(" 输入:源程序字符串 ");
printf(" 输出:二元组(种别,单词本身) ");
printf("---------------------------------------- ");
printf("请输入您要输入的字符: ");
do//输入一段字符串
{
ch=getchar();
str[p++]=ch;
}while(ch!='#');
p=0;
ch=str[0];
if(ch>='0'&&ch<='9')
printf("错误! ");
else
{
do
{
scanner();
switch(zbm)
{
case 11:
printf("(%d,%d) ",11,sum);
break;
case -1:
printf("错误! ");
break;
default:
printf("(%d,%s) ",zbm,take);
}
}while(zbm!=0);
}
return 0;
}
运行结果及分析