Spark底层逻辑
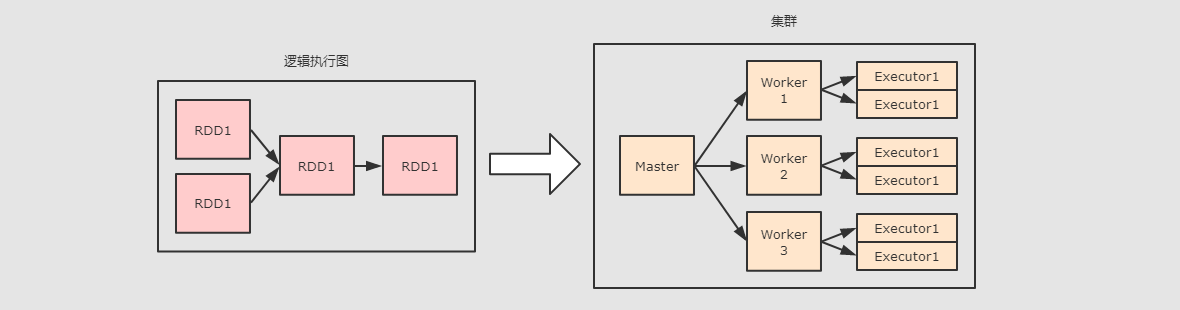
Spark部署

针对于上图, 可以看到整体上在集群中运行的角色有如下几个:
-
Master Daemon负责管理
Master节点, 协调资源的获取, 以及连接Worker节点来运行Executor, 是 Spark 集群中的协调节点 -
Worker Daemon当一个
Spark Job提交后, 会创建SparkContext, 后Worker会启动对应的Executor. -
Executor Backend上面有提到
Worker用于控制Executor的启停, 其实Worker是通过Executor Backend来进行控制的,Executor Backend是一个进程(是一个JVM实例), 持有一个Executor对象
另外在启动程序的时候, 有三种程序需要运行在集群上:
-
DriverDriver是一个JVM实例, 是一个进程, 是Spark Application运行时候的领导者, 其中运行了SparkContext.Driver控制Job和Task, 并且提供WebUI. -
ExecutorExecutor对象中通过线程池来运行Task, 一个Executor中只会运行一个Spark Application的Task, 不同的Spark Application的Task会由不同的Executor来运行
逻辑执行图
RDD 的逻辑图本质上是对于计算过程的表达, 例如数据从哪来, 经历了哪些步骤的计算

对于 RDD 的逻辑执行图, 起始于第一个入口 RDD 的创建, 结束于 Action 算子执行之前, 主要的过程就是生成一组互相有依赖关系的 RDD, 其并不会真的执行, 只是表示 RDD 之间的关系, 数据的流转过程.
RDD间的依赖关系
说明:RDD之间的依赖关系不是指RDD 之间的关系.而是分区之间的关系
窄依赖
判断依据:分区间一对一,多对一(需要判断是否有数据分发,shuffle)
例子:
- 一对一窄依赖 map算子

- Range窄依赖 union算子

- 多对一窄依赖 coalesce算子

宽依赖
判断依据:多对一且有数据分发,shuffle
例子:reduceByKey算子

总结
宽窄依赖的核心区别是: 窄依赖的 RDD 可以放在一个 Task中运行
物理执行图
意义:
谁来计算RDD?
应该由一个线程来执行 RDD 的计算任务, 而 Executor 作为执行这个任务的容器, 也就是一个进程, 用于创建和执行线程, 这个执行具体计算任务的线程叫做 Task
Task设计:划分区段
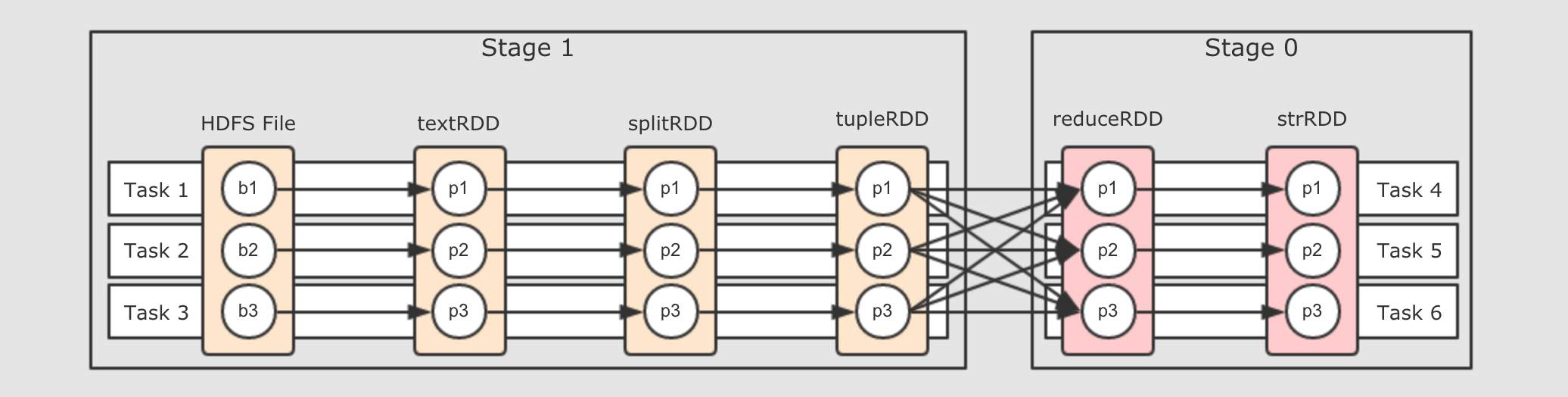
划分阶段的本身就是设置断开点的规则
-
-
第二步, 遇到
ShuffleDependency(宽依赖)断开Stage, 从下一个RDD开始创建新的Stage, 为Stage1 -
第三步, 新的
Stage按照同样的规则继续滑动, 直到包裹所有的RDD
总结来看, 就是针对于宽窄依赖来判断, 一个 Stage 中只有窄依赖, 因为只有窄依赖才能形成数据的 Pipeline.如果要进行 Shuffle 的话, 数据是流不过去的, 必须要拷贝和拉取. 所以遇到 RDD 宽依赖的两个 RDD 时, 要切断这两个 RDD 的 Stage.
数据流动

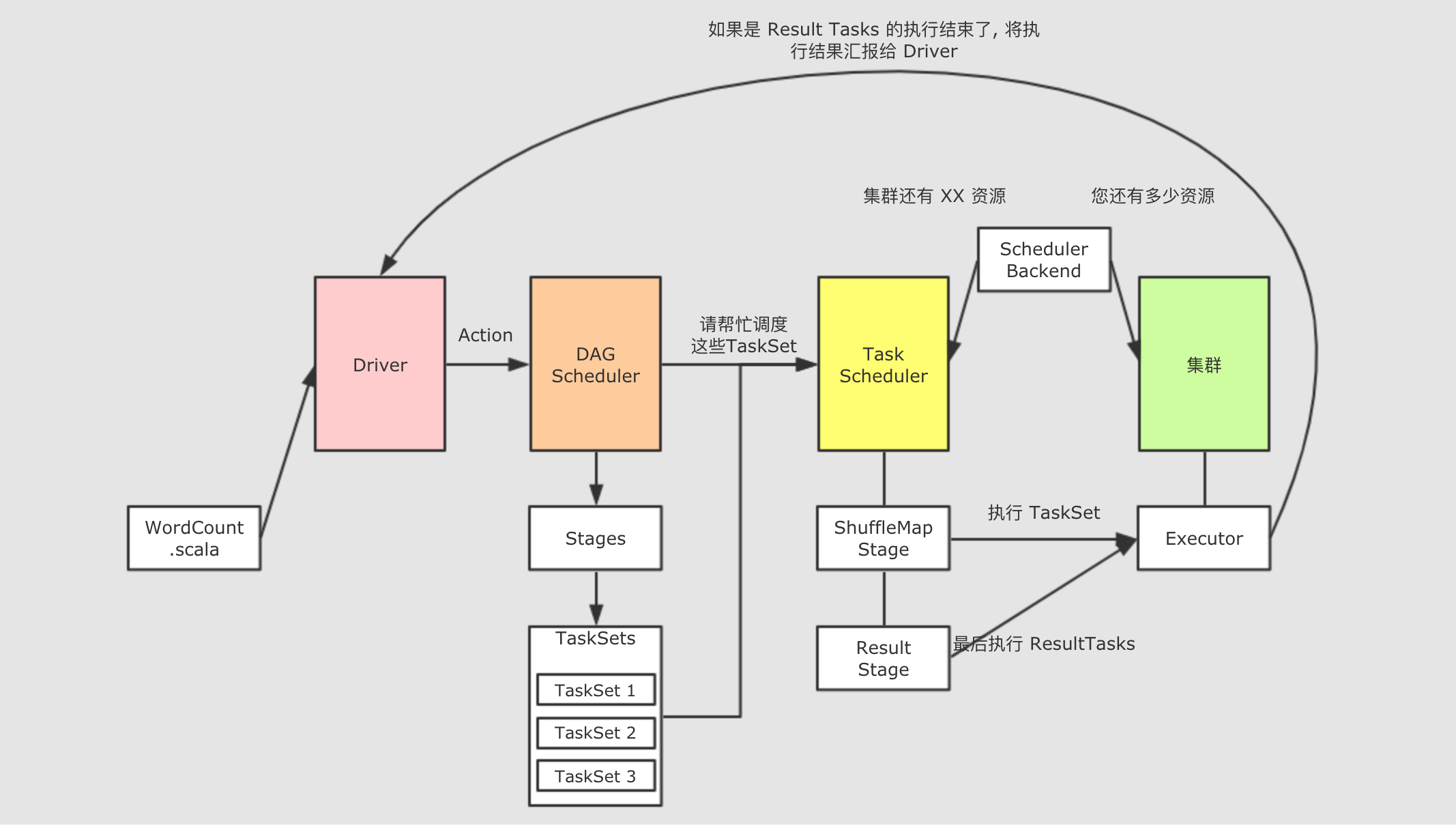
Job 什么时候生成 ?
当一个 RDD 调用了 Action 算子的时候, 在 Action 算子内部, 会使用 sc.runJob() 调用 SparkContext 中的 runJob 方法, 这个方法又会调用 DAGScheduler 中的 runJob, 后在 DAGScheduler 中使用消息驱动的形式创建 Job
简而言之, Job 在 RDD 调用 Action 算子的时候生成, 而且调用一次 Action 算子, 就会生成一个 Job, 如果一个 SparkApplication 中调用了多次 Action 算子, 会生成多个 Job 串行执行, 每个 Job 独立运作, 被独立调度, 所以 RDD 的计算也会被执行多次
Job 是什么 ?
如果要将 Spark 的程序调度到集群中运行, Job 是粒度最大的单位, 调度以 Job 为最大单位, 将 Job 拆分为 Stage 和 Task 去调度分发和运行, 一个 Job 就是一个 Spark 程序从 读取 → 计算 → 运行 的过程
一个 Spark Application 可以包含多个 Job, 这些 Job 之间是串行的, 也就是第二个 Job 需要等待第一个 Job
- 一个Job有多个Stage
- Stage之间是串行的
Spark高级特性
闭包
累加器
全局累加器
val config = new SparkConf().setAppName("ip_ana").setMaster("local[6]") val sc = new SparkContext(config) val counter = sc.longAccumulator("counter") sc.parallelize(Seq(1, 2, 3, 4, 5)) .foreach(counter.add(_)) // 运行结果: 15 println(counter.value)
注意点:
-
-
只能在 Driver 中才能调用 value来获取数值
-
累加器只有在 Action 执行的时候才会被触发
广播变量
作用
广播变量允许开发者将一个 Read-Only 的变量缓存到集群中每个节点中, 而不是传递给每一个 Task 一个副本.
-
集群中每个节点, 指的是一个机器
-
每一个 Task, 一个 Task 是一个 Stage 中的最小处理单元, 一个 Executor 中可以有多个 Stage, 每个 Stage 有多个 Task
创建
val b = sc.broadcast(1)
方法
获取数据 b.value
删除数据 b.unpersist
释放内存空间 b.destroy