案例一:词频统计
要求:统计Harry Potter.txt文件中出现最多单词前十位
内容样例:

def WordCount(): Unit ={ val conf=new SparkConf().setMaster("local[6]").setAppName("wordCount") val sc=new SparkContext(conf) val result=sc.textFile("dataset/HarryPotter.txt") .flatMap(item=>item.split(" ")) .filter(item=>StringUtils.isNotEmpty(item)) .map(item=>(item,1)) .reduceByKey((curr,agg)=>curr+agg) .sortBy(item=>item._2,ascending = false) .map(item=>s"${item._1},${item._2}") .take(10) result.foreach(println(_)) }
结果:

案例二:日志信息统计
要求:统计某一日志文件里出现的IP的次数Top10,最多,最少
内容样例:
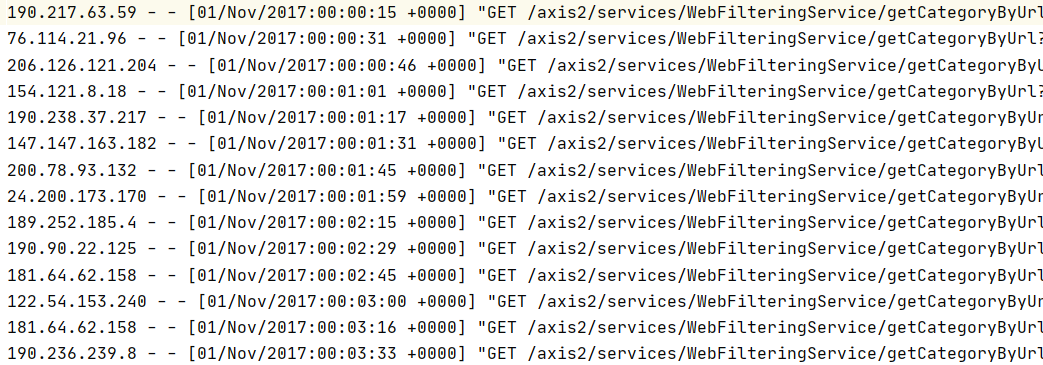
def logIpTop10(): Unit ={ val conf=new SparkConf().setMaster("local[6]").setAppName("sparkCoreTest") val sc=new SparkContext(conf) sc.setCheckpointDir("checkpoint") val result=sc.textFile("dataset/access_log_sample.txt") .map(item=>(item.split(" ")(0),1)) .filter(item=>StringUtils.isNoneEmpty(item._1)) .reduceByKey((curr,agg)=>curr+agg) .cache() result.checkpoint() val top10=result.sortBy(item => item._2, ascending = false).take(10) top10.foreach(println(_)) val max=result.sortBy(item => item._2, ascending = false).first() val min=result.sortBy(item => item._2, ascending = true).first() println("max:"+max+" min:"+min) }
结果:

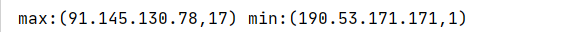
案例三:学生成绩统计
要求:统计学生数,课程数,学生平均成绩
内容样例:
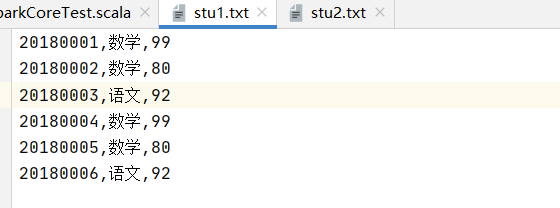

def stuGrade(): Unit ={ val conf=new SparkConf().setMaster("local[6]").setAppName("sparkCoreTest") val sc=new SparkContext(conf) val stu1=sc.textFile("dataset/stu1.txt") val stu2=sc.textFile("dataset/stu2.txt") val stu=stu1.union(stu2) val stuNum=stu.map(item=>(item.split(",")(0),(item.split(",")(1),item.split(",")(2)))) .groupByKey() .count() val courseNum=stu.map(item=>(item.split(",")(1),(item.split(",")(0),item.split(",")(2)))) .groupByKey() .count() println("学生数:"+stuNum+" 课程数:"+courseNum) val result=stu.map(item=>(item.split(",")(0),item.split(",")(2).toDouble)) .combineByKey( createCombiner = (curr: Double) => (curr, 1), mergeValue = (curr: (Double, Int), nextValue: Double) => (curr._1 + nextValue, curr._2 + 1), mergeCombiners = (curr: (Double, Int), agg: (Double, Int)) => (curr._1 + agg._1, curr._2 + agg._2) ) .map(item=>(item._1,item._2._1/item._2._2)) .collect() result.foreach(println(_)) }
结果:


案例四:统计某省PM
要求:按年月统计某省PM总数
内容样例:

def pmProcess(): Unit ={ val conf=new SparkConf().setMaster("local[6]").setAppName("sparkCoreTest") val sc=new SparkContext(conf) val source = sc.textFile("dataset/pmTest.csv") val result = source.map( item => ((item.split(",")(1), item.split(",")(2)), item.split(",")(6)) ) .filter( item => StringUtils.isNotEmpty(item._2) && ! item._2.equalsIgnoreCase("NA") ) .map( item => (item._1, item._2.toInt) ) .reduceByKey( (curr, agg) => curr + agg ) .sortBy( item => item._2, ascending = false) .map(item=> s"${item._1._1},${item._1._2},${item._2}") .collect() result.foreach(println(_)) }
结果:
