redis中压缩列表ziplist相关的文件为:ziplist.h与ziplist.c
压缩列表是redis专门开发出来为了节约内存的内存编码数据结构。源码中关于压缩列表介绍的注释也写得比较详细。
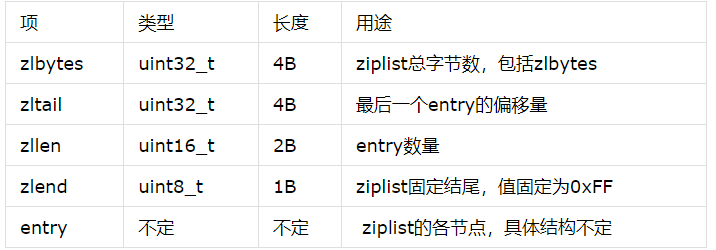
一、数据结构
压缩列表的整体结构如下
1 /*
2 <zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
3 */
各个部分的含义
关于entry
1 /**
2 * We use this function to receive information about a ziplist entry.
3 * Note that this is not how the data is actually encoded, is just what we
4 * get filled by a function in order to operate more easily.
5 */
6 typedef struct zlentry {
7 unsigned int prevrawlensize; /* Bytes used to encode the previous entry len*/
8 unsigned int prevrawlen; /* Previous entry len. */
9 unsigned int lensize; /* Bytes used to encode this entry type/len.
10 For example strings have a 1, 2 or 5 bytes
11 header. Integers always use a single byte.*/
12 unsigned int len; /* Bytes used to represent the actual entry.
13 For strings this is just the string length
14 while for integers it is 1, 2, 3, 4, 8 or
15 0 (for 4 bit immediate) depending on the
16 number range. */
17 unsigned int headersize; /* prevrawlensize + lensize. */
18 unsigned char encoding; /* Set to ZIP_STR_* or ZIP_INT_* depending on
19 the entry encoding. However for 4 bits
20 immediate integers this can assume a range
21 of values and must be range-checked. */
22 unsigned char *p; /* Pointer to the very start of the entry, that
23 is, this points to prev-entry-len field. */
24 } zlentry;
借用redis源码注释的结构简化一下
1 /*
2 <prevlen> <encoding> [<entry-data>]
3 */
prevlen表示的是前一个entry的长度,用于反向遍历,即从最后一个元素遍历到第一个元素。因每个entry的长度是不确定的,所以要记录一下前一个entry的长度。prevlen本身的长度也是不定的,与前一entry的实际长度有关。若长度小于254,只需要1B就可以了。若实际长度大于等于254,则需要5B,第1B固定为254,后面4B存储实际长度。
encoding则与entry存储的data有关。
| encoding前两位 | encoding内容 | encoding长度 | entry-data类型 | entry-data长度 |
| 00 | |00pppppp| | 1B | string | 6b能表示的数字,0~63,encoding中存储的长度为大端字节序 |
| 01 | |01pppppp|qqqqqqqq| | 2B | string | 14b能表示的数字,64~16383,encoding中存储的长度为大端字节序 |
| 10 | |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| | 5B | string | int32能表示的数字,16384~2^32-1,encoding中存储的长度为大端字节序 |
| 11 | |11000000| | 1B | int16 | 2B |
| 11 | |11010000| | 1B | int32 | 4B |
| 11 | |11100000| | 1B | int64 | 8B |
| 11 | |11110000| | 1B | int24 | 3B |
| 11 | |11111110| | 1B | int8 | 1B |
| 11 | |1111xxxx| | 1B | 无 | xxxx在[0001,1101]之间,表示0~12的数字,存储时进行+1操作 |
| 11 | |11111111| | 1B | 无 | End of ziplist special entry(源码注释) |
如一个具体的ziplist,有两个成员“2”与“5”
1 /*
2 [0f 00 00 00] [0c 00 00 00] [02 00] [00 f3] [02 f6] [ff]
3 | | | | | |
4 zlbytes zltail zllen "2" "5" end
5 */
zlbytes值为15,表示这个ziplist总长为15B
zltail的值为12,表示最后一个entry的偏移量为12
zllen的值为2,表示一共有两个entry
第一个entry的prevlen为0。因为第一个成员之前没有其它成员了,所以是0,占1B。值为“2”,可以用数字表示,且是介于[0,12]之间,故使用1111xxxx的encoding方式,无entry-data。2的二进制编码为0010,+1后为0011,实际为11110011,即0xF3。同理,5的encoding为0xF6。做为第二个entry,其前一个entry的总长为2,故其prevlen值为2。
zlend固定是0xFF。
二、基本操作
redis中使用了大量的宏定义与函数配合操作ziplist。
2.1 创建
一些重要的宏定义
1 /**
2 * Return total bytes a ziplist is composed of.
3 * 返回组成压缩列表的总的字节数
4 */
5 #define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl)))
6
7 /**
8 * Return the offset of the last item inside the ziplist.
9 * 返回最后一个元素在压缩列表中的偏移量
10 */
11 #define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))
12
13 /**
14 * Return the length of a ziplist, or UINT16_MAX if the length cannot be
15 * determined without scanning the whole ziplist.
16 * 返回压缩列表中entry的数量
17 */
18 #define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2)))
19
20 /**
21 * The size of a ziplist header: two 32 bit integers for the total
22 * bytes count and last item offset. One 16 bit integer for the number
23 * of items field.
24 * 返回压缩列表头部的大小:zlbytes + zltail + zllen ----- 4 + 4 + 2
25 */
26 #define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
27
28 /**
29 * Size of the "end of ziplist" entry. Just one byte.
30 * 返回压缩列表尾部的大小:1个字节
31 */
32 #define ZIPLIST_END_SIZE (sizeof(uint8_t))
33
34 /**
35 * Return the pointer to the first entry of a ziplist.
36 * 返回指向压缩列表中第一个entry的指针
37 */
38 #define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE)
39
40 /**
41 * Return the pointer to the last entry of a ziplist, using the
42 * last entry offset inside the ziplist header.
43 * 返回指向压缩列表中最后一个entry的指针
44 */
45 #define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl)))
46
47 /**
48 * Return the pointer to the last byte of a ziplist, which is, the
49 * end of ziplist FF entry.
50 * 返回指向压缩列表中最后一个自己的指针
51 */
52 #define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1)
53
54 /**
55 * Increment the number of items field in the ziplist header. Note that this
56 * macro should never overflow the unsigned 16 bit integer, since entries are
57 * always pushed one at a time. When UINT16_MAX is reached we want the count
58 * to stay there to signal that a full scan is needed to get the number of
59 * items inside the ziplist.
60 * 压缩列表中entry的数量增加incr,但是不可以超过UINT16_MAX,也就是2个字节
61 */
62 #define ZIPLIST_INCR_LENGTH(zl,incr) {
63 if (ZIPLIST_LENGTH(zl) < UINT16_MAX)
64 ZIPLIST_LENGTH(zl) = intrev16ifbe(intrev16ifbe(ZIPLIST_LENGTH(zl))+incr);
65 }
创建函数
1 /**
2 * Create a new empty ziplist.
3 * 创建一个压缩列表
4 */
5 unsigned char *ziplistNew(void) {
6 //zlbytes + zltail + zllen + zlend ----- 4 + 4 + 2 + 1
7 unsigned int bytes = ZIPLIST_HEADER_SIZE+1;
8 //分配内存
9 unsigned char *zl = zmalloc(bytes);
10 //设置压缩列表中的zlbytes
11 ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
12 //设置最后一个元素的偏移量zltail
13 ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
14 //设置entry的数量
15 ZIPLIST_LENGTH(zl) = 0;
16 //设置帧结束符0xFF
17 zl[bytes-1] = ZIP_END;
18 return zl;
19 }
新创建的ziplist,没有entry,只有zlbytes、zltail、zllen与zlend
1 /*
2 [0b 00 00 00] [0a 00 00 00] [00 00] [ff]
3 | | | |
4 zlbytes zltail zllen end
5 */
2.2 插入
底层插入实现函数
1 /**
2 * Insert item at "p".
3 * 在位置p处插入元素
4 */
5 unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
6 size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen;
7 unsigned int prevlensize, prevlen = 0;
8 size_t offset;
9 int nextdiff = 0;
10 unsigned char encoding = 0;
11 long long value = 123456789; /* initialized to avoid warning. Using a value
12 that is easy to see if for some reason
13 we use it uninitialized. */
14 zlentry tail;
15
16 /**
17 * Find out prevlen for the entry that is inserted.
18 * 为了出入元素,获取所要插入位置当前节点的prevlen和prevlensize
19 */
20 if (p[0] != ZIP_END) {//如果不是插在尾部
21 //取出前一个entry所占的字节数
22 ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
23 } else {//如果是插在尾部
24 //得到指向最后一个entry的指针
25 unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl);
26 if (ptail[0] != ZIP_END) {//如果链表不为空
27 //计算所有entry所占的字节数
28 prevlen = zipRawEntryLength(ptail);
29 }
30 }
31
32 /**
33 * See if the entry can be encoded
34 * 对entry尝试使用数字编码
35 */
36 if (zipTryEncoding(s,slen,&value,&encoding)) {
37 /* 'encoding' is set to the appropriate integer encoding 'encoding' 设置为适当的整数编码*/
38 reqlen = zipIntSize(encoding);
39 } else {
40 /**
41 * 'encoding' is untouched, however zipStoreEntryEncoding will use the
42 * string length to figure out how to encode it.
43 * 'encoding' 未受影响,但是 zipStoreEntryEncoding 将使用字符串长度来确定如何对其进行编码。
44 */
45 reqlen = slen;
46 }
47 /**
48 * We need space for both the length of the previous entry and
49 * the length of the payload.
50 * 获得本entry的总长度,即prevlen、encoding、entry-data长度和。
51 */
52 reqlen += zipStorePrevEntryLength(NULL,prevlen);
53 reqlen += zipStoreEntryEncoding(NULL,encoding,slen);
54
55 /**
56 * When the insert position is not equal to the tail, we need to
57 * make sure that the next entry can hold this entry's length in
58 * its prevlen field.
59 * 当插入位置不是结尾时,判断一下插入后,后一个entry的prevlen是否足够存储新entry的长度。
60 * 此处需要注意,如果原本是5B的prevlen,当前1B就足够存储,则不做任何处理,强制使用5B来存储1B能存储的数字。
61 * 而如果原来是1B,当前要5B,则还需要4B空间。
62 */
63 int forcelarge = 0;
64 nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0;
65 if (nextdiff == -4 && reqlen < 4) {
66 nextdiff = 0;
67 forcelarge = 1;
68 }
69
70 /* Store offset because a realloc may change the address of zl. */
71 offset = p-zl;
72 zl = ziplistResize(zl,curlen+reqlen+nextdiff);
73 p = zl+offset;
74
75 /**
76 * Apply memory move when necessary and update tail offset.
77 * 重新分配ziplist空间。新增加的字节数。
78 */
79 if (p[0] != ZIP_END) {
80 /* Subtract one because of the ZIP_END bytes 移动压缩列表中的元素到正确位置*/
81 memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);
82
83 /* Encode this entry's raw length in the next entry. 修正插入位置entry的prevlen*/
84 if (forcelarge)
85 zipStorePrevEntryLengthLarge(p+reqlen,reqlen);
86 else
87 zipStorePrevEntryLength(p+reqlen,reqlen);
88
89 /* Update offset for tail 修改zltail*/
90 ZIPLIST_TAIL_OFFSET(zl) =
91 intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen);
92
93 /**
94 * When the tail contains more than one entry, we need to take
95 * "nextdiff" in account as well. Otherwise, a change in the
96 * size of prevlen doesn't have an effect on the *tail* offset.
97 * 如果需要的话更新插入位置之后的每一个entry的prevlen
98 */
99 zipEntry(p+reqlen, &tail);
100 if (p[reqlen+tail.headersize+tail.len] != ZIP_END) {
101 ZIPLIST_TAIL_OFFSET(zl) =
102 intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
103 }
104 } else {
105 /* This element will be the new tail. 如果元素是插在尾部*/
106 ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl);
107 }
108
109 /* When nextdiff != 0, the raw length of the next entry has changed, so
110 * we need to cascade the update throughout the ziplist */
111 if (nextdiff != 0) {
112 offset = p-zl;
113 zl = __ziplistCascadeUpdate(zl,p+reqlen);
114 p = zl+offset;
115 }
116
117 /* Write the entry 填写新entry*/
118 p += zipStorePrevEntryLength(p,prevlen);
119 p += zipStoreEntryEncoding(p,encoding,slen);
120 if (ZIP_IS_STR(encoding)) {
121 memcpy(p,s,slen);
122 } else {
123 zipSaveInteger(p,value,encoding);
124 }
125 ZIPLIST_INCR_LENGTH(zl,1);
126 return zl;
127 }
被用户使用的ziplistInsert和ziplistPush函数调用
ziplistInsert函数
1 /* Insert an entry at "p". 在位置p插入一个entry*/
2 unsigned char *ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
3 return __ziplistInsert(zl,p,s,slen);
4 }
ziplistPush函数
1 unsigned char *ziplistPush(unsigned char *zl, unsigned char *s, unsigned int slen, int where) {
2 unsigned char *p;
3 p = (where == ZIPLIST_HEAD) ? ZIPLIST_ENTRY_HEAD(zl) : ZIPLIST_ENTRY_END(zl);
4 return __ziplistInsert(zl,p,s,slen);
5 }
假设有以下ziplist
1 /*
2 [0f 00 00 00] [0c 00 00 00] [02 00] [00 f3] [02 f6] [ff]
3 | | | | | |
4 zlbytes zltail zllen "2" "5" end
5 */
要在"2"与"5"之间插入节点“3”,则:
a.获取所要插入位置当前节点“5”的prevlen=2,prevlen_size=1
若要插入的位置是end处,则取出zltail进行偏移,取到“5”节点,直接进行计算。而如果当前是个空ziplist,直接就是0了。
b.获取节点“3”的实际长度,若其为纯数字,则可以使用数字存储,节约内存。否则直接使用外部传入的,string的长度。
这里有一点:
1 int zipTryEncoding(unsigned char *entry, unsigned int entrylen, long long *v, unsigned char *encoding) {
2 long long value;
3
4 if (entrylen >= 32 || entrylen == 0) return 0;
5 if (string2ll((char*)entry,entrylen,&value)) {
6 /* Great, the string can be encoded. Check what's the smallest
7 * of our encoding types that can hold this value. */
8 if (value >= 0 && value <= 12) {
9 *encoding = ZIP_INT_IMM_MIN+value;
10 } else if (value >= INT8_MIN && value <= INT8_MAX) {
11 *encoding = ZIP_INT_8B;
12 } else if (value >= INT16_MIN && value <= INT16_MAX) {
13 *encoding = ZIP_INT_16B;
14 } else if (value >= INT24_MIN && value <= INT24_MAX) {
15 *encoding = ZIP_INT_24B;
16 } else if (value >= INT32_MIN && value <= INT32_MAX) {
17 *encoding = ZIP_INT_32B;
18 } else {
19 *encoding = ZIP_INT_64B;
20 }
21 *v = value;
22 return 1;
23 }
24 return 0;
25 }
在尝试使用数字编码的时候,如果len >= 32,则直接不尝试,并不清楚这个32是怎么来的。
本例中,“3”可以直接使用数字编码,且在[0,12]之间,故没有entry-data
c.获得本entry的总长度,即prevlen、encoding、entry-data长度和。本处为1+1=2
d.判断一下插入后,后一个entry的prevlen是否足够存储新entry的长度。新长度为2,原entry的prevlen只有1B,足够。
此处需要注意,如果原本是5B的prevlen,当前1B就足够存储,则不做任何处理,强制使用5B来存储1B能存储的数字。而如果原来是1B,当前要5B,则还需要4B空间。
e.重新分配ziplist空间。新增加的字节数,为c、d两步之和。此处只需要额外2B的空间。
分配空间后:
1 /*
2 [11 00 00 00] [0c 00 00 00] [02 00] [00 f3] [02 f6] [ff] [00 ff]
3 | | | | | |
4 zlbytes zltail zllen "2" "5" end
5 */
重新分配空间会自动设置zlend与zlbytes
f.将“5”及之后的节点(不包括zlend)往后移:
1 /*
2 [11 00 00 00] [0c 00 00 00] [02 00] [00 f3] [02 f6] [02 f6] [ff]
3 | | | | | |
4 zlbytes zltail zllen "2" "5" "5"
5 */
g.修正当前“5”所在位置的prevlen=2:
1 /*
2 [11 00 00 00] [0c 00 00 00] [02 00] [00 f3] [02 f6] [02 f6] [ff]
3 | | | | | |
4 zlbytes zltail zllen "2" "5" "5"
5 */
h.修改zltail:
1 /*
2 [11 00 00 00] [0e 00 00 00] [02 00] [00 f3] [02 f6] [02 f6] [ff]
3 | | | | | |
4 zlbytes zltail zllen "2" "5" "5"
5 */
i.填写新entry:
1 /*
2 [11 00 00 00] [0e 00 00 00] [03 00] [00 f3] [02 f4] [02 f6] [ff]
3 | | | | | |
4 zlbytes zltail zllen "2" "3" "5"
5 */
若在此基础上,在“3”前,插入的是一个长度为256的string X,则:
a.获取“3”的prevlen与prevlen_size
prevlen=2,prevlen_size=1
b.长度大于32,使用string进行存储,实际长度data_len=256
c.获取entry总长度
此处prevlen长度为1B,encoding长度为2B ,entry-data长度为256B,共1+2+256=259
d.判断一下插入后,后一个entry的prevlen是否足够存储新entry的长度。新长度为259,超过了254,需要5B,而原本只有1B,还差了4B。即,nextdiff=4
e.分配空间。新增加字节数为259+4=263,共280B,即0x118
分配空间后:
1 /*
2 [0x118] [0xe] [03 00] [00 f3] [02 f4] [02 f6] [...] [ff]
3 | | | | | | |
4 zlbytes zltail zllen "2" "3" "5" 263B
5 4B 4B
6 */
f.memmove操作
ziplist中的memmove操作
1 memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);
操作完之后
1 /*
2 [...] [00 f3] [02 f4] [02 f6] [...] [03 00] [00 f3] [02 f4] [02 f6] [ff]
3 | | | | | | | |
4 header "2" "3" "5" 255B "2" "3" "5"
5 10B
6 */
其中header为zlbytes、zltail与tllen
其实与以下写法相同效果:
1 memmove(p+reqlen+nextdiff,p,curlen-offset-1+nextdiff);
这种写法操作完之后:
1 /*
2 [0x118] [0xe] [03 00] [00 f3] [02 f4] [02 f6] [...] [02 f4] [02 f6] [ff]
3 | | | | | | | | |
4 zlbytes zltail zllen "2" "3" "5" 259B "3" "5"
5 4B 4B
6 */
目的是一样的,把原来的节点移至正确的位置上。
g.修正当前“3”所在位置的prevlen=259,即0X103:
1 /*
2 [0x118] [0xe] [03 00] [00 f3] [...] [FE 03 01 00 00 f4] [02 f6] [ff]
3 | | | | | | |
4 zlbytes zltail zllen "2" 259B "3" "5"
5 4B 4B
6 */
h.此时节点"3"的长度发生变化,需要更新其后一个节点"5"的prevlen
1 /*
2 [0x118] [0xe] [03 00] [00 f3] [...] [FE 03 01 00 00 f4] [06 f6] [ff]
3 | | | | | | |
4 zlbytes zltail zllen "2" 259B "3" "5"
5 4B 4B
6 */
i.修改zltail
1 /*
2 [0x118] [0x115] [03 00] [00 f3] [...] [FE 00 00 01 03 f4] [06 f6] [ff]
3 | | | | | | |
4 zlbytes zltail zllen "2" 259B "3" "5"
5 4B 4B
6 */
j.填写新entry:
encoding值为:01000001 00000000 即0x4100,大端字节序
填写后:
1 /*
2 [0x118] [0x115] [03 00] [00 f3] [02 41 00 ...] [FE 00 00 01 03 f4] [06 f6] [ff]
3 | | | | | | |
4 zlbytes zltail zllen "2" X "3" "5"
5 4B 4B 259B
6 */
k.更新zllen
1 /*
2 [0x118] [0x115] [04 00] [00 f3] [02 41 00 ...] [FE 00 00 01 03 f4] [06 f6] [ff]
3 | | | | | | |
4 zlbytes zltail zllen "2" X "3" "5"
5 4B 4B 259B
6 */
若有连续几个entry的长度在[250,253]B之间,在插入新节点后可能存在连锁更新的情况。
如以下ziplist(只保留部分entry,其余节点省略):
1 /*
2 ... [FD 40 FA ...] [FD 40 FA ...] ...
3 | |
4 E1 253B E2 253B
5 */
E1的prevlen为FD,即长度为253。此时在E1之前插入一个长度为256的节点,E1需要增加prevlen的长度,从而导致E1整体长度增加。
E2的prevlen为FD,即E1的长度为253。增加4个节点之后为257,E2也需要增加prevlen的长度。
之后还可能会有E3,E4等entry需要处理,产生了连锁反应,直到到了以下情况才会停止:
i.到了zlend
ii.不需要继续扩展
iii.需要减少prevlen字节数时
连锁更新时需要多次重新分配空间,最坏情况下有n个节点的ziplist,需要分配n次空间,而每次分配的最坏情况时间复杂度为O(n),故连锁更新的最坏情况时间复杂度为O(n^2)。
2.3 查找
ziplist的查找过程其实是一次遍历,依次解析出prevlen、encoding与entry-data,然后根据encoding类型,决定是要用strcmp,还是直接使用数字的比较。在首次进行数字比较的时候,会把传入要查找的串,尝试一次转换成数字的操作。如果无法转换,就会跳过数字比较操作。
查找操作支持每隔几个entry才做一次比较操作。如,查找每5个entry中,值为“1”的entry。
1 /**
2 * Find pointer to the entry equal to the specified entry. Skip 'skip' entries
3 * between every comparison. Returns NULL when the field could not be found.
4 *
5 * ziplist的查找过程其实是一次遍历,依次解析出prevlen、encoding与entry-data,然后根据encoding类型,
6 * 决定是要用strcmp,还是直接使用数字的比较。在首次进行数字比较的时候,会把传入要查找的串,
7 * 尝试一次转换成数字的操作。如果无法转换,就会跳过数字比较操作。
8 *
9 * 查找操作支持每隔几个entry才做一次比较操作。
10 */
11 unsigned char *ziplistFind(unsigned char *p, unsigned char *vstr, unsigned int vlen, unsigned int skip) {
12 int skipcnt = 0;
13 unsigned char vencoding = 0;
14 long long vll = 0;
15
16 while (p[0] != ZIP_END) {
17 unsigned int prevlensize, encoding, lensize, len;
18 unsigned char *q;
19
20 ZIP_DECODE_PREVLENSIZE(p, prevlensize);
21 ZIP_DECODE_LENGTH(p + prevlensize, encoding, lensize, len);
22 q = p + prevlensize + lensize;
23
24 if (skipcnt == 0) {
25 /* Compare current entry with specified entry */
26 if (ZIP_IS_STR(encoding)) {
27 if (len == vlen && memcmp(q, vstr, vlen) == 0) {
28 return p;
29 }
30 } else {
31 /* Find out if the searched field can be encoded. Note that
32 * we do it only the first time, once done vencoding is set
33 * to non-zero and vll is set to the integer value. */
34 if (vencoding == 0) {
35 if (!zipTryEncoding(vstr, vlen, &vll, &vencoding)) {
36 /* If the entry can't be encoded we set it to
37 * UCHAR_MAX so that we don't retry again the next
38 * time. */
39 vencoding = UCHAR_MAX;
40 }
41 /* Must be non-zero by now */
42 assert(vencoding);
43 }
44
45 /* Compare current entry with specified entry, do it only
46 * if vencoding != UCHAR_MAX because if there is no encoding
47 * possible for the field it can't be a valid integer. */
48 if (vencoding != UCHAR_MAX) {
49 long long ll = zipLoadInteger(q, encoding);
50 if (ll == vll) {
51 return p;
52 }
53 }
54 }
55
56 /* Reset skip count */
57 skipcnt = skip;
58 } else {
59 /* Skip entry */
60 skipcnt--;
61 }
62
63 /* Move to next entry */
64 p = q + len;
65 }
66
67 return NULL;
68 }
2.4 删除
底层实现的删除函数
1 /**
2 * Delete "num" entries, starting at "p". Returns pointer to the ziplist.
3 * 底层的删除函数
4 * num:删除的元素的个数
5 * p:删除的元素数组
6 */
7 unsigned char *__ziplistDelete(unsigned char *zl, unsigned char *p, unsigned int num) {
8 unsigned int i, totlen, deleted = 0;
9 size_t offset;
10 int nextdiff = 0;
11 zlentry first, tail;
12
13 zipEntry(p, &first);
14 for (i = 0; p[0] != ZIP_END && i < num; i++) {
15 p += zipRawEntryLength(p);
16 deleted++;
17 }
18
19 totlen = p-first.p; /* Bytes taken by the element(s) to delete. */
20 if (totlen > 0) {
21 if (p[0] != ZIP_END) {
22 /* Storing `prevrawlen` in this entry may increase or decrease the
23 * number of bytes required compare to the current `prevrawlen`.
24 * There always is room to store this, because it was previously
25 * stored by an entry that is now being deleted. */
26 nextdiff = zipPrevLenByteDiff(p,first.prevrawlen);
27
28 /* Note that there is always space when p jumps backward: if
29 * the new previous entry is large, one of the deleted elements
30 * had a 5 bytes prevlen header, so there is for sure at least
31 * 5 bytes free and we need just 4. */
32 p -= nextdiff;
33 zipStorePrevEntryLength(p,first.prevrawlen);
34
35 /* Update offset for tail */
36 ZIPLIST_TAIL_OFFSET(zl) =
37 intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))-totlen);
38
39 /* When the tail contains more than one entry, we need to take
40 * "nextdiff" in account as well. Otherwise, a change in the
41 * size of prevlen doesn't have an effect on the *tail* offset. */
42 zipEntry(p, &tail);
43 if (p[tail.headersize+tail.len] != ZIP_END) {
44 ZIPLIST_TAIL_OFFSET(zl) =
45 intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
46 }
47
48 /* Move tail to the front of the ziplist */
49 memmove(first.p,p,
50 intrev32ifbe(ZIPLIST_BYTES(zl))-(p-zl)-1);
51 } else {
52 /* The entire tail was deleted. No need to move memory. */
53 ZIPLIST_TAIL_OFFSET(zl) =
54 intrev32ifbe((first.p-zl)-first.prevrawlen);
55 }
56
57 /* Resize and update length */
58 offset = first.p-zl;
59 zl = ziplistResize(zl, intrev32ifbe(ZIPLIST_BYTES(zl))-totlen+nextdiff);
60 ZIPLIST_INCR_LENGTH(zl,-deleted);
61 p = zl+offset;
62
63 /* When nextdiff != 0, the raw length of the next entry has changed, so
64 * we need to cascade the update throughout the ziplist */
65 if (nextdiff != 0)
66 zl = __ziplistCascadeUpdate(zl,p);
67 }
68 return zl;
69 }
被ziplistDelete和ziplistDeleteRange函数调用
1 /**
2 * Delete a single entry from the ziplist, pointed to by *p.
3 * Also update *p in place, to be able to iterate over the
4 * ziplist, while deleting entries.
5 * 从zl指向的 ziplist 中删除单个条目。 同时更新 *p,以便能够在删除条目的同时迭代 ziplist。
6 */
7 unsigned char *ziplistDelete(unsigned char *zl, unsigned char **p) {
8 size_t offset = *p-zl;
9 zl = __ziplistDelete(zl,*p,1);
10
11 /* Store pointer to current element in p, because ziplistDelete will
12 * do a realloc which might result in a different "zl"-pointer.
13 * When the delete direction is back to front, we might delete the last
14 * entry and end up with "p" pointing to ZIP_END, so check this. */
15 //删除之后当前位置的元素
16 *p = zl+offset;
17 return zl;
18 }
19
20 /**
21 * Delete a range of entries from the ziplist.
22 * 从压缩列表中删除一个范围中的所有entries
23 */
24 unsigned char *ziplistDeleteRange(unsigned char *zl, int index, unsigned int num) {
25 unsigned char *p = ziplistIndex(zl,index);
26 return (p == NULL) ? zl : __ziplistDelete(zl,p,num);
27 }
如有以下ziplist:
1 /*
2 [0x118] [0x115] [04 00] [00 f3] [02 41 00 ...] [FE 00 00 01 03 f4] [06 f6] [ff]
3 | | | | | | |
4 zlbytes zltail zllen "2" X "3" "5"
5 4B 4B 259B
6 */
删除的是节点“5”,因是最后一个节点,则只要先修改zltail:
1 /*
2 [0x118] [0x10F] [04 00] [00 f3] [02 41 00 ...] [FE 00 00 01 03 f4] [06 f6] [ff]
3 | | | | | | |
4 zlbytes zltail zllen "2" X "3" "5"
5 4B 4B 259B
6 */
然后resize:
1 /*
2 [0x116] [0x10F] [04 00] [00 f3] [02 41 00 ...] [FE 00 00 01 03 f4] [ff]
3 | | | | | |
4 zlbytes zltail zllen "2" X "3"
5 4B 4B 259B
6 */
最后修改zllen即可:
1 /*
2 [0x116] [0x10F] [03 00] [00 f3] [02 41 00 ...] [FE 00 00 01 03 f4] [ff]
3 | | | | | |
4 zlbytes zltail zllen "2" X "3"
5 4B 4B 259B
6 */
如果是这个ziplist:
1 /*
2 [0x118] [0x115] [04 00] [00 41 00 ...] [FE 00 00 01 03 f4] [06 f3] [02 f6] [ff]
3 | | | | | | |
4 zlbytes zltail zllen X "3" "2" "5"
5 4B 4B 259B
6 */
如果删除是的节点"3",则先要计算删除后,"3"节点后的"2"节点的prevlen长度是否足够,然后直接写入。此时长度不够,并不会直接重新分配空间,而是直接使用之前"3"节的最后4B空间:
1 /*
2 [0x118] [0x115] [04 00] [00 41 00 ...] [FE 00] [FE 00 00 01 03 f3] [02 f6] [ff]
3 | | | | | | |
4 zlbytes zltail zllen X 2B "2" "5"
5 4B 4B 259B
6 */
然后修改zltail:
1 /*
2 [0x118] [0x113] [04 00] [00 41 00 ...] [FE 00] [FE 00 00 01 03 f3] [02 f6] [ff]
3 | | | | | | |
4 zlbytes zltail zllen X 2B "2" "5"
5 4B 4B 259B
6 */
接着进行memmove操作:
1 /*
2 [0x118] [0x113] [04 00] [00 41 00 ...] [FE 00 00 01 03 f3] [02 f6] [02 f6] [ff]
3 | | | | | | |
4 zlbytes zltail zllen X "2" "5" "5"
5 4B 4B 259B
6 */
resize操作:
1 /*
2 [0x116] [0x113] [04 00] [00 41 00 ...] [FE 00 00 01 03 f3] [02 f6] [ff]
3 | | | | | |
4 zlbytes zltail zllen X "2" "5"
5 4B 4B 259B
6 */
最后要更新节点"2"及其之后entry的prevlen:
1 /*
2 [0x116] [0x113] [04 00] [00 41 00 ...] [FE 00 00 01 03 f3] [06 f6] [ff]
3 | | | | | |
4 zlbytes zltail zllen X "2" "5"
5 4B 4B 259B
6 */
注意此时更新也是有可能产生连锁反应。
删除操作支持删除从指定位置开始,连续n个entry,操作类似。
参考文章
https://www.cnblogs.com/chinxi/p/12272173.html