基础知识
首先我们来看下栈帧的定义:
In C and modern CPU design conventions, the stack frame is a chunk of memory, allocated from the stack, at run-time, each time a function is called,
to store its automatic variables. Hence nested or recursive calls to the same function, each successively obtain their own separate frames.
Physically, a function’s stack frame is the area between the addresses contained in esp, the stack pointer, and ebp,
the frame pointer (base pointer in Intel terminology). Thus, if a function pushes more values onto the stack, it is effectively growing its frame.
在C语言和现代CPU的设计规范中,栈帧是一块由栈分配的内存块,在运行时,每当调用一次函数时,都要存储其自动变量。因此对于同一函数的递归调用在每一次都会连续的获得自己独立的栈帧。
从物理上讲,函数的栈帧是指esp和ebp之间的一块地址。因此如果一个函数把更多的值压入堆栈,实际上是在扩展它本身的栈帧。
栈帧的实际布局
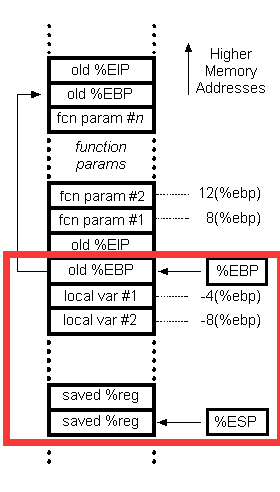
在这幅图中我们应该关注的重点就是红框中EBP上面的值,即EIP和采用__cdecl调用约定的参数。这里出现了一个新的名词__cdecl,这其实是函数调用的一种调用约定,下面罗列出来:
- __stdcall :函数采用从右到左的压栈方式,自己在退出时清空堆栈。
- __cdecl:即C调用约定(The C default calling convention),按从右至左的顺序压参数入栈,由调用者把参数弹出栈。对于传送参数的内存栈是由调用者来维护的(正因为如此,实现可变参数vararg的函数(如printf)只能使用该调用约定)。
- __fastcall: __fastcall调用的主要特点就是快,因为它是通过寄存器来传送参数的(实际上,它用ECX和EDX传送前两个双字(DWORD)或更小的参数,剩下的参数仍旧自右向左压栈传送,被调用的函数在返回前清理传送参数的内存栈)。
采用__cdecl调用约定的调用者会将参数从右到左的入栈,最后将返回地址入栈。这个返回地址是指,函数调用结束后的下一行执行的代码地址。获取参数和返回地址的话我们只需要通过EBP加偏移就可以了。当然图上的偏移量是32为系统的。
正文
上面简单的过了一下基础知识,接下来我们通过对libco中coctx_make与coctx_swap的解析,搞清楚协程切换的本质,因为学汇编的时候学习的都是32位的,我们以32位为例子进行讲解。64位只是多了一些寄存器和一些调用规则的上的不同罢了,基本的逻辑都是一样的,所以我们选择32位系统进行分析。
我们先来看看与协程切换相关的数据结构:
1 // 用于分配coctx_swap两个参数内存区域的结构体,仅32位下使用,64位下两个参数直接由寄存器传递
2 struct coctx_param_t
3 {
4 const void *s1;
5 const void *s2;
6 };
7 struct coctx_t
8 {
9 #if defined(__i386__)
10 // 上下文
11 void *regs[ 8 ];
12 #else
13 void *regs[ 14 ];
14 #endif
15 size_t ss_size;// 栈的大小
16 char *ss_sp; // 栈顶指针esp
17
18 };
coctx_t结构可以说是libco中最为重要的结构了,它直接存储了协程的上下文。
coctx_make
调用coctx_swap之前的准备工作由coctx_make设置完成,我们来看看其实现:
1 int coctx_make(coctx_t* ctx, coctx_pfn_t pfn, const void* s, const void* s1) {
2 // make room for coctx_param
3 // 此时sp其实就是esp指向的地方 其中ss_size感觉像是这个栈上目前剩余的空间,
4
5 char* sp = ctx->ss_sp + ctx->ss_size - sizeof(coctx_param_t);
6 //------- ss_sp + ss_size
7 //| |
8 //| |
9 //------- ss_sp
10 //ctx->ss_sp 对应的空间是在堆上分配的,地址是从低到高的增长,而堆栈是往低地址方向增长的,
11 //所以要使用这一块人为改变的栈帧区域,首先地址要调到最高位,即ss_sp + ss_size的位置
12
13 sp = (char*)((unsigned long)sp & -16L);// 字节对齐,16L是一个magic number,下文会做解释
14
15 // param用来给我们预留下来的参数区设置值
16 coctx_param_t* param = (coctx_param_t*)sp;
17 void** ret_addr = (void**)(sp - sizeof(void*) * 2); // 函数返回值
18 // (sp - sizeof(void*) * 2) 这个指针存放着指向ret_addr的指针
19 *ret_addr = (void*)pfn; // 新协程要执行的指令函数,也即执行完这个函数要cotx_swap要返回的值
20 param->s1 = s; //即将切换到的协程
21 param->s2 = s1; // 切换出的线程
22 //------- ss_sp + ss_size
23 //|pading| 这里是对齐区域
24 //|s2 |
25 //|s1 |
26 //|原esp |
27 //| 返回地址 |
28 //|esp实际空间|
29 //------- <- sp(原esp - sizeof(void*) * 2)
30 //| |
31 //------- ss_sp
32 // 对照着上面那个栈帧的图去看
33
34 memset(ctx->regs, 0, sizeof(ctx->regs));
35
36 // ESP指针sp向下偏移2,因为除了ebp还有一个返回地址
37 // 进入函数以后就会push ebp了
38 ctx->regs[kESP] = (char*)(sp) - sizeof(void*) * 2;
39 //sp初始指向第一个参数的起始地址
40 //函数调用,压入参数之后,还有一个返回地址要压入,所以还需要将sp往下移动8个字节,
41 //32位汇编获取参数是通过EBP+8, EBP+12来分别获取第一个参数,第二个参数的,
42 //这里减去4个字节是为了对齐这种约定,这里可以看到对齐以及参数还有4个字节的虚拟返回地址已经
43 //占用了一定的栈空间,所以实际上供协程使用的栈空间是小于分配的空间。另外协程且走调用co_swap参数入栈也会占用空间,
44 // KESP(7)在swap中是赋给esp的
45 return 0;
46 }
其实就是一个函数调用过程的模拟,功能就是给coctx_swap做一些准备工作,关键是要理解那个(sp - sizeof(void*) * 2),在理解的时候搭配着那张栈帧的图可以更有效率。
16L的哲学
然后我们来说一说那个16L的魔法数字到底有什么用,我们在代码中提到了这个magic number其实是为了字节对齐。16这个数字非常奇怪,一般来说我们的认知都是32位下字节对齐应该是4,64位系统下当然就是8了,这个16是什么情况?答案就是GCC默认的堆对齐设置的就是16字节。具体可查看这篇文章:《Why does System V / AMD64 ABI mandate a 16 byte stack alignment?》
coctx_swap
接下来我们来看看coctx_swap执行协程切换的过程:
1 movl 4(%esp), %eax
2 这里ESP获取到的是对应图中old %EIP的地址,加4对应第一个参数的地址,把这个值赋给eax,当然也隐藏着eax[0]的赋值
3
4 | *ss_sp |
5 | ss_size |
6 | regs[7] |
7 | regs[6] |
8 | regs[5] |
9 | regs[4] |
10 | regs[3] |
11 | regs[2] |
12 | regs[1] |
13 | regs[0] |
14 -------------- <---EAX
15
16 movl %esp, 28(%eax)
17 movl %ebp, 24(%eax)
18 movl %esi, 20(%eax)
19 movl %edi, 16(%eax)
20 movl %edx, 12(%eax)
21 movl %ecx, 8(%eax)
22 movl %ebx, 4(%eax)
23 // 想想看,这里eax加偏移不就是对应了regs中的值吗?这样就把所有寄存器中的值保存在了参数中
24
25
26 // ESP偏移八位就是第二个参数的偏移了,这样我们就可以把第二个参数regs中的上下文切换到寄存器中了
27 movl 8(%esp), %eax
28 movl 4(%eax), %ebx
29 movl 8(%eax), %ecx
30 movl 12(%eax), %edx
31 movl 16(%eax), %edi
32 movl 20(%eax), %esi
33 movl 24(%eax), %ebp
34 movl 28(%eax), %esp
35
36 ret
37 // 这样我们就完成了一次协程的切换
转载:
https://blog.csdn.net/weixin_43705457/article/details/106877644