1.libco简介
libco是微信后台大规模使用的c/c++协程库,2013年至今稳定运行在微信后台的数万台机器上,使得微信后端服务能同时hold大量请求,被誉为微信服务器稳定性的基石。libco在2013年的时候作为腾讯六大开源项目首次开源。libco源码地址
libco首先能解决CPU利用率与IO利用率不平衡,比用多线程解决IO阻塞CPU问题更高效。因为用户态协程切换比线程切换性能高:线程切换保存恢复的数据更多,需要用户态和内核态切换。 其次libco又避免了异步调用和回调分离导致的代码结构破碎。
libco采用epoll多路复用使得一个线程处理多个socket连接,采用钩子函数hook住socket族函数,采用时间轮盘处理等待超时事件,采用协程栈保存、恢复每个协程上下文环境。
本文以源码为主介绍libco,内容偏底层细节。
2.设计思想
2.1协程切换
2.1.1 函数栈
首先复习下进程的地址空间,如图2.1.1.1所示,与本文相关的有代码段、堆、栈。代码段包含应用程序的汇编代码,指令寄存器eip存的是代码段中某一条汇编指令地址,cpu从eip中取出汇编指令的地址,并在代码段中找到对应汇编指令开始执行。CPU执行指令时在栈里存参数、局部变量等数据。代码通过malloc、new在堆上申请内存空间。

图2.1.1.1
图2.1.1.2所示C代码,通过gcc -m32 test.c -o test.o在i386下编译,然后执行gdb test.o。disas main可看到图2.1.1.3所示的main函数汇编码,disas sum可看到图2.1.1.4所示sum函数的汇编代码。调用sum时,main和sum的函数栈如图2.1.1.5所示。图2.1.1.5的表共有两列,第一列为内存地址,第二列为该地址存的内容,除了用“…”省略的内存地址,其他每一行均比上一行低4byte,因为栈地址从高到低增长。

图2.1.1.2

图2.1.1.3

图2.1.1.4

从图2.1.1.5可以看出:一,每个函数的栈在ebp栈底指针和esp栈顶指针之间;二,存在调用关系的两个函数的栈内存地址是相邻的;三,ebp指针指的位置存储的是上级函数的ebp地址,例如sum的ebp 0xffffd598位置存的是main的ebp0xffffd5c8,目的是sum执行后可恢复main的ebp,而main的esp可通过sum的ebp + 4恢复;四,sum的ebp + 4位置,即main的esp位置存的是sum执行后的返回地址0x08048415,该地址不在图2.1.1.1中的栈(Stack)里,而在图2.1.1.1中的代码段里,sum执行后,leave指令恢复ebp、esp,ret指令将esp处的内容0x08048415放到寄存器eip,cpu从eip里取出下一条待执行的指令地址,并根据指令地址从代码段里获取指令执行;五,sum的参数y、x按高地址到低地址,依次存在sum的ebp + 12、ebp + 8位置处。
2.1.2 协程栈
共享栈下文介绍,此处介绍非共享栈。在非共享栈模式下,每个非主协程有自己的栈,而该栈是在堆上分配的,并不是系统栈,但主协程的栈仍然是系统栈,每两个协程的栈地址不相邻。协程栈切换分为第1次、第k次(k>=2)换到目的协程TargetCoroutine。
因为主协程即当前线程的第1次运行是系统调度的,后续才是用户调度的,而非主协程每次都由用户调度。所以每次主协程切回的行为都一样,且和非主协程第k次(k>=2)的切回行为一致。
第1次切到TargetCoroutine之前, coctx_make(图2.1.2.1)将函数地址pfn写入协程变量regs[ kEIP ],pfn即为CoRoutineFunc的指针。CoRoutineFunc函数(图2.1.2.2)在第448行调进用户自定义的协程函数UserCoRoutineFunc(图2.1.2.3)。图2.1.2.1中ss_sp为128K协程栈低地址,ss_size为128K,将ss_sp + ss_size – sizeof(coctx_param_t) – sizeof(void*)作为esp开始位置,记录在regs[kESP]。因为栈从高到低增长,所以真正的栈空间从高地址ss_sp + ss_size – sizeof(coctx_param_t) – sizeof(void*)增长到低地址ss_sp。这部分空间虽然是协程栈,但实际是通过stack_mem->stack_buffer = (char*)malloc(stack_size)申请的堆空间。CoRoutineFunc、其调用的函数、其调用的函数再调用的函数…的函数栈均在该128K的堆空间里。

图2.1.2.1
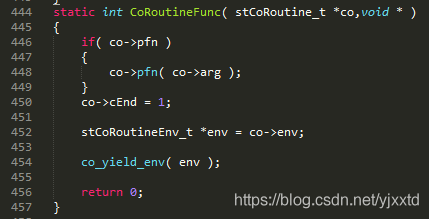
图2.1.2.2
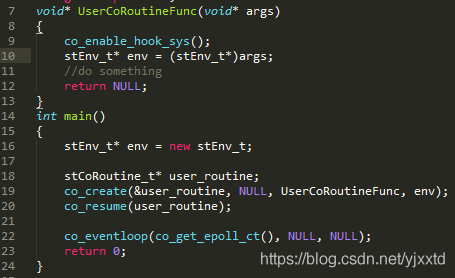
图2.1.2.3
第1次切换到TargetCoroutine时。图2.1.2.4第50行将esp指向TargetCoroutine.coctx_t.regs,此时esp指向的地址如图2.1.2.5所示。第54行从regs[0]弹出返回地址,即CoRoutineFunc函数地址0x08043212。第65行 弹出esp地址即ss_sp + ss_size – sizeof(coctx_param_t) – sizeof(void*)。第67行pushl %eax做两件事情:一,将esp地址减4,即esp = ss_sp + ss_size – sizeof(coctx_param_t) – sizeof(void*) – 4;二,在esp新位置压入CoRoutineFunc函数地址。第71行ret从esp取出CoRoutineFunc函数地址放入eip寄存器,cpu从eip寄存器取出CoRoutineFunc函数第一条指令地址开始执行指令,CoRoutineFunc函数第一条指令的地址就是CoRoutineFunc函数地址。
图2.1.2.1中没有对regs[kEBP]赋初值,因此切到TargetCoroutine时弹出的ebp是0,导致CoRoutineFunc函数栈存的上级函数的ebp是0,但没有影响。CoRoutineFunc(图2.1.2.2)只能执行到第454行:co_yield_env(env),然后切到其他协程,不会执行到456行。上级函数的ebp是在CoRoutineFunc执行后,用于恢复上级函数的esp,但在这里CoRoutineFunc函数在return 0之前已经切到其他协程,因此上级函数的ebp是0不会导致错误。

图2.1.2.4
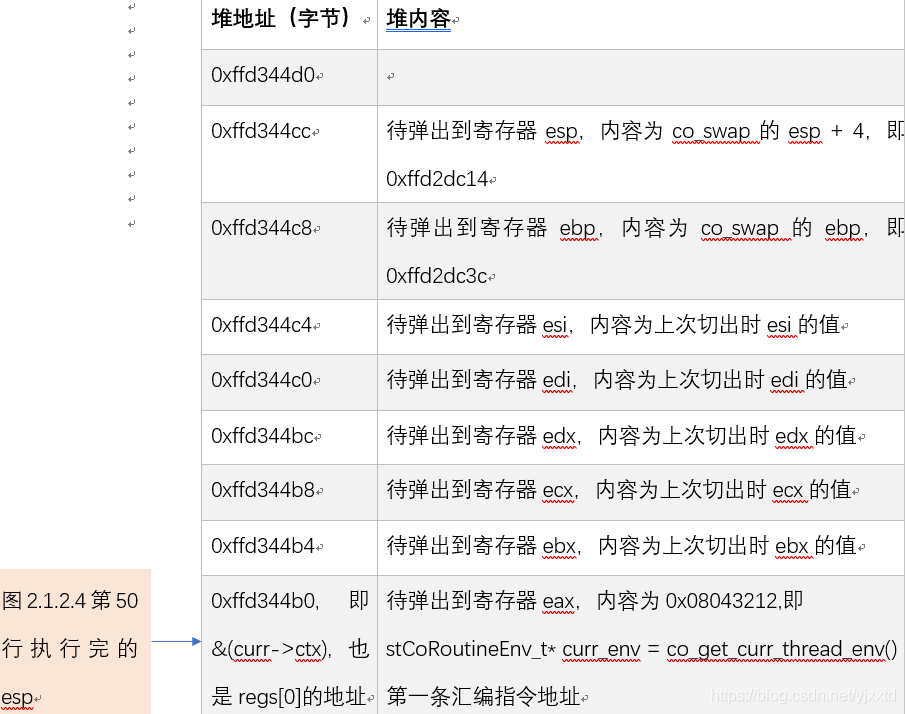
图2.1.2.5 第1次切到TargetCoroutine
TargetCoroutine在第k-1次被coctx_swap切出时,TargetCoroutine是图2.3.2.4的源协程curr。切出TargetCoroutine时会调进coctx_swap,在执行图2.1.2.4第34行之前,函数栈如图2.1.2.6所示。然后将co_swap(注意不是coctx_swap,因为这里没有像图2.1.1.4的第3、4、5行修改ebp和esp)栈顶地址+4即0xffd2dc14通过第38行写入到regs[kESP]。将co_swap(不是coctx_swap,原因同上)栈底地址ebp即0xffd2dc3c通过第40行写入regs[kEBP]。将stCoRoutineEnv_t* curr_env = co_get_curr_thread_env()的第一条汇编指令地址0x08043212通过第47行写入regs[ kEIP ]。此时regs数组内容如图2.1.2.7所示,在此期间esp的变化如图2.1.2.7左侧所示。

图2.1.2.6 co_swap函数栈

图2.1.2.7 第k(k>=2)次切到TargetCoroutine
第k(k>=2)次切回TargetCoroutine时,图2.1.2.4第54行弹出eax,即stCoRoutineEnv_t* curr_env = co_get_curr_thread_env()的第一条汇编指令地址0x08043212。第61行弹出ebp即图2.3.2.6所示的0xffd2dc3c。图2.3.2.4第65行弹出esp,即图2.1.2.6所示的0xffd2dc14(不是0xffd2dc10,因为图2.3.2.4第38行的压入的eax是0xffd2dc10 + 4)。第67行做两件事情,首先esp减4得到切出时的栈地址0xffd2dc10,再将eax存的汇编指令地址0x08043212写到esp即0xffd2dc10处。最后ret从esp取出汇编指令地址0x08043212放入eip寄存器,cpu从eip寄存器取出指令地址开始执行指令。因为TargetCoroutine切回时,首先执行 stCoRoutineEnv_t* curr_env = co_get_curr_thread_env(),而TargetCoroutine在之前切出时,最后执行的代码是coctx_swap(&(curr->ctx),&(pending_co->ctx) ),因此协程在切回后能接着之前切出时的代码继续执行。对比图2.1.2.5和2.1.2.7发现:第1次切到TargetCoroutine时ebp、esp、返回地址、以及其他寄存器和第k(k>=2)次均不同。
libco在stCoRoutineEnv_t定义了pCallStack数组,大小为128,数组里的每个元素均为协程。pCallStack用于获取当前协程pCallStack[iCallStackSize - 1];获取当前协程挂起后该切到的协程pCallStack[iCallStackSize - 2]。pCallStack存的是递归调用(暂且称之为递归,并不是递归)的协程,pCallStack[0]一定是主协程。例如主协程调用协程1,协程1调用协程2…协程k-1调用协程k,这种递归关系的k最大为127,调到协程127时,此时pCallStack[0]存主协程,pCallStack[1]存协程1…pCallStack[k]存协程k…pCallStack[127]存协程127。但递归如此之深的协程实际中不会遇到,更多的场景应该是主协程调用协程1,协程1挂起切回主协程,主协程再调用协程2,协程2挂起切回主协程,主协程再调用协程3…因此主协程调到协程k时,pCallStack[0]是主协程,pCallStack[1]是协程k,其他元素为空;协程k挂起切回主协程时,pCallStack[0]是主协程,其他元素为空。因此128大小的pCallStack足够上万甚至更多协程使用。
2.1.3 主协程
主协程即为当前线程,用stCoRoutine_t. cIsMain标记。主协程的栈在图2.1.1.1所示的栈(Stack)区,而其他协程的栈在图2.1.1.1所示的堆(Heap)区。图2.1.2.4中切出主协程时38-47行寄存器存在regs数组里(不在128K的协程栈里,另外申请的堆空间)。切回主协程时,第61、65行弹出的ebp、esp指向的是系统栈里的内存,因此主协程的栈始终在系统栈上,用不到128K的协程栈。
那是否有必要将当前协程标记为主协程?图2.1.3.1的第1024、1033行是代码仅有的两处需要判断主协程。如果声明了协程私有变量,但没有创建其他协程时,co为NULL,此时通过1026行获取主协程私有变量。但在程序运行到某段代码时开始创建协程,如果不标记主协程,因为co不为NULL,代码会通过第1028行获取主协程私有变量,此时因为拿不到以前设置的主协程私有变量而导致错误。例如若将图2.1.3.1第1024、1033行的co->cIsMain条件删掉,图2.1.3.2第24行输出的主协程私有变量为11,而第30行输出0。
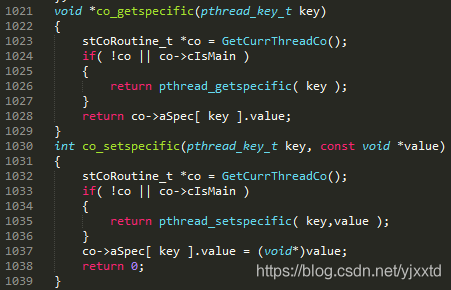
图2.3.3.1

图2.3.3.2
2.1.4 共享栈
每个协程申请一个固定128K的栈,在协程数量很大时,存在内存压力。因此libco引入共享栈模式,示例代码可参看example_copystack.cpp。共享栈对主协程没有影响,共享栈仍然是在堆上,而主协程的栈在系统栈上。
采用共享栈时,每个协程的栈从共享栈拷出时,需要分配空间存储,但按需分配空间。因为绝大部分协程的栈空间都远低于128K,因此拷出时只需分配很小的空间,相比私有栈能节省大量内存。共享栈可以只开一个,但为了避免频繁换入换出,一般开多个共享栈。每个共享栈可以申请大空间,降低栈溢出的风险。
假设开10个共享栈,每个协程模10映射到对应的共享栈。假设协程调用顺序为主协程、协程2、协程3、协程12。协程2切到协程3时,因为协程2、3使用的共享栈分别是第2、3个共享栈,没有冲突,所以协程2的栈内容仍然保留在第2个共享栈,并不拷出来,但协程2的寄存器会被coctx_swap保存在regs数组。调用到协程12时,协程12和协程2都映射到第2个共享栈,因此需要将协程2的栈内容拷出,并将协程12的栈内容拷贝到第2个共享栈中。所以共享栈多了拷出协程2的栈、拷进协程12的栈两个操作,即用拷贝共享栈的时间换取每个协程栈的空间。
图2.4.1在609行将curr的stack_sp指向c的地址,记录当前协程栈的低位置,当前协程栈的高位置是ss_sp + ss_size – sizeof(coctx_param_t) – sizeof(void*),存的是CoRoutineFunc函数第一条汇编指令。curr协程拷出协程时,需要拷贝从curr->stack_sp(即&c)到ss_sp + ss_size – sizeof(coctx_param_t) – sizeof(void*)的栈内容。以后从其他协程再切换回curr协程时,如果共享栈里有curr协程,则只通过coctx_swap恢复寄存器即可;否则如图2.4.1第657行所示,需要将curr保存在curr->save_buffer的协程栈复制到从curr->stack_sp到ss_sp + ss_size – sizeof(coctx_param_t) – sizeof(void*)的内存空间。
图2.1.4.1从curr协程切到pending_co协程时,如果是共享栈模式,先拿到pending_co的共享栈stack_mem里已有的协程occupy_co,如果occupy_co非空且不是pending_co,则保存已有的协程save_stack_buffer(occupy_co),将stack_mem指向的协程换为pending_co。并将pending_co和occupy_co均保存在env里,不能用局部变量记录,因为局部变量在coctx_swap之前属于curr协程,但coctx_swap后协程栈已经被切换,curr的所有局部变量无法被pending_co访问。如果occupy_co和pending_co不是同一个协程,需要将occupy_co在共享栈里的数据拷贝到occupy_co->save_buffer。协程的数据除了在栈里还分布在寄存器,如果occupy_co不是curr,则在occupy_co之前被切换到其他协程时寄存器已经被coctx_swap保存;否则,则其寄存器在本次执行coctx_swap被保存。

图2.1.4.1
2.1.5 线程切换 VS 协程切换
IO密集时也可以使用多个线程。但线程有两个不足:一,切换代价大(保存恢复上下文、线程调度);二,占用资源多。
线程往往需要对公共数据加锁,锁会导致线程调度。因为用户的线程是在用户态执行,而线程调度和管理是在内核态实现,所以线程调度需要从用户态转到内核态,再从内核态转到用户态。切到内核态时需要保存用户态上下文,再切到用户态时,需要恢复用户态上下文,而线程的用户态上下文比协程上下文大得多。另外线程调度也需要耗时。
线程栈默认为1M大于协程栈128K,另外线程还需要各种struct存一些状态,实测每个pthread_create创建的线程大约占8M左右内存,因此线程占用资源也远比协程多。
2.2 协程控制
2.2.1 epoll多路复用IO模型
协程使用epoll多路复用IO模型。常见的同步调用是同步阻塞模型,异步调用是异步IO模型。以read为例说明以下三种IO模型的区别,read分为两个阶段:一,等待数据;二,将数据从kernel拷贝到用户线程。
同步调用read使用同步阻塞IO,kernel等待数据到达,再将数据拷贝到用户线程,这两个阶段用户线程都被阻塞。异步调用read使用异步IO模型,用户线程调用read后,立刻可以去做其它事, kernel等待数据准备完成,然后将数据拷贝到用户内存,都完成后,kernel通知用户read完成,然后用户线程直接使用数据,两个阶段用户线程都不被阻塞。而协程调用read使用多路复用IO模型,用户线程调用read后,第一阶段也不会被阻塞,但第二个阶段会被阻塞,epoll多路复用IO模型可以在一个线程管理多个socket。
同步调用在两个阶段都会阻塞用户线程,因此效率低。虽然可以为每个连接开个线程,但连接数多时,线程太多导致性能压力,也可以开固定数目的线程池,但如果存在大量长连接,线程资源不被释放,后续的连接得不到处理。异步调用时,因为两个阶段都不阻塞用户线程,因此效率最高,但异步的调用逻辑和回调逻辑需要分开,在异步调用多时,代码结构不清晰。而协程的epoll多路复用IO模型,虽然会阻塞第二个阶段,但因为第二阶段读数据耗时很少,因此效率略低于异步调用。协程最大的优点是在接近异步效率的同时,可以使用同步的写法(仅仅是同步的写法,不是同步调用)。例如read函数的调用代码后,紧接着可以写处理数据的逻辑,不用再定义回调函数。调用read后协程挂起,其他协程被调用,数据就绪后在read后面处理数据。
系统select/poll、epoll函数都提供多路IO复用方案,协程使用的是epoll。select、poll类似,监视writefds、readfds、exceptfds文件描述符(fd)。调用select/poll会阻塞,直到有fd就绪(可读、可写、有except),或超时。select/poll返回后,通过遍历fd集合,找到就绪的fs,并开始读写。poll用链表存储fd,而select用fd标记位存储,因此poll没有最大连接数限制,而select限制为1024。select/poll共有的缺点是:一,返回后需要遍历fd集合找到就绪的fd,但fd集合就绪的描述符很少;二,select/poll均需将fd集合在用户态和内核态之间来回拷贝。epoll的引入是为了解决select/poll上述两个缺点,epoll提供三个函数epoll_create、epoll_ctl、epoll_wait。epoll_create在内核的高速cache中建一棵红黑树以及就绪链表(activeList)。epoll_ctl的add在红黑树上添加fd结点,并且注册fd的回调函数,内核在检测到某fd就绪时会调用回调函数将fd添加到activeList。epoll_wait将activeList中的fd返回。epoll_ctl每次只往内核添加红黑树节点,不需像select/poll拷贝所有fd到内核,epoll_wait通过共享内存从内核传递就绪fd到用户,不需像select/poll拷贝出所有fd并遍历所有fd找到就绪的。
2.2.2 非阻塞IO
协程的epoll多路复用IO模型使用的是非阻塞IO,发起read操作后,可立即挂起协程,并调度其他协程。非阻塞IO是通过fcntl函数设置O_NONBLOCK,影响socket族read、write、connect、sendto、recvfrom、send、recv函数。因为read、recv、recvfrom实现类似,write、send实现类似。因此接下来介绍read、write、connect三个函数。
2.2.2.1 钩子函数read
如图2.2.2.1.1所示,用户自定义的read函数hook住系统read函数。Read时分三种情况:一,用户未开启hook,直接在337行调用系统read;二,如果用户指定了O_NONBLOCK,也直接在343行调用系统read,此时是非阻塞的;三,如果用户既开启了hook,又没有指定O_NONBLOCK,如果libco不做任何处理,即使通过353行poll了,但如果协程是超时返回,第355行还是会被阻塞,实际上就是需要实现用户态的阻塞。所以只要用户开启hook,socket函数(图2.2.2.1.2)会在234行调用fcntl函数,最终调用图2.2.2.1.3的第696行,悄悄的设置O_NONBLOCK,但user_flag并没有记录O_NONBLOCK,这样就可以和第二种情况区分。然后图2.2.2.1.1第353行调用poll将当前协程挂起,直到有数据可读或者超时,协程才会重新调度。在第二种情况下,不能先将协程挂起,等待就绪后再切回,因为用户显示的设置O_NONBLOCK是为了立即返回,如果挂起,就绪或超时后再切回,与用户需要立即获得返回结果的初衷违背。

图2.2.2.1.1
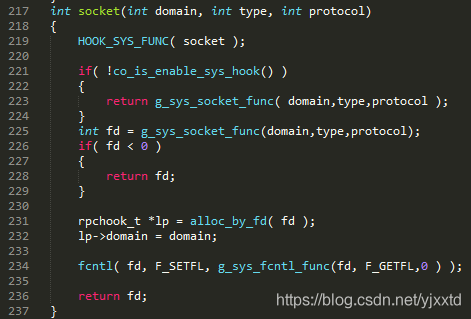
图2.2.2.1.2
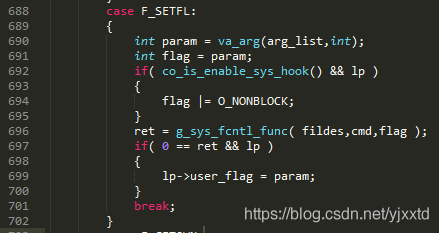
图2.2.2.1.3
2.2.2.2 钩子函数write
非阻塞write在发送缓冲区没有空间时直接返回,发送缓冲区有空间时,则拷贝全部或部分(空间不够)数据,返回实际拷贝的字节数。
如图2.2.2.2.1所示,分三种情况:一,用户未开启hook,在372行调用系统write;二,如果用户指定了O_NONBLOCK,在378行调用系统write,此时是非阻塞的,这种情况与第三种情况区分的原因见2.2.2.1;三,如果用户既开启了hook,又没有指定O_NONBLOCK,由2.2.2.1可知,libco已悄悄设置O_NONBLOCK,只要数据没有完全写入缓冲区,就通过第402行poll将协程挂起,等待有空余空间唤醒协程或者超时唤醒。 writeret记录本次调用写入的字节数,wrotelen记录总共写入的字节数,如果本次写入没有空间或出错,则直接返回。因为write明确知道要写入数据的长度nbyte,而一次可能无法写入全部数据,所以write在while循环里不断写数据,直到数据写完、写出错,才会停止写数据。而2.2.2.1的read不知要读多少数据,因此读一次就返回。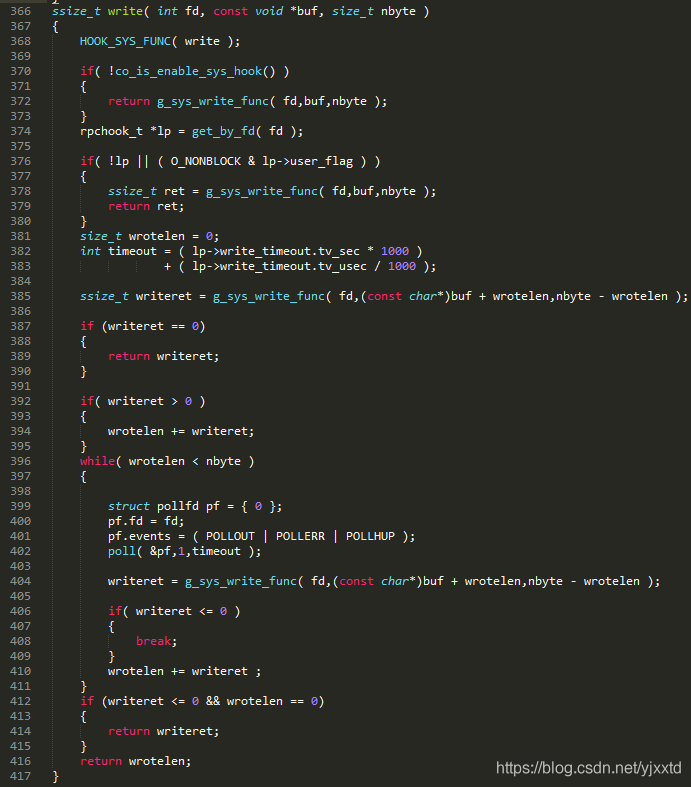
图2.2.2.2.1
2.2.2.3 钩子函数connect
图2.2.2.3.1所示为libco自定义connect函数片段。如果用户启用hook,且未设置O_NONBLOCK,libco悄悄帮用户设置了O_NONBLOCK,但调用connect后不能立即返回,因为connect有三次握手的过程,内核中对三次握手的超时限制是75秒,超时则会失败。libco设置O_NONBLOCK后,立即调用系统connect可能会失败,因此在图2.2.2.3.1中循环三次,每次设置超时时间25秒,然后挂起协程,等待connect成功或超时。

图2.2.2.3.1
2.2.3 epoll激活协程
协程hook住了底层socket族函数,设置了O_NONBLOCK,调用socket族函数后,调用poll注册epoll事件并挂起协程,让其他协程执行,所有协程都挂起后通过epoll,在主协程里检查注册的IO事件,若就绪或超时则切到对应协程。
poll最终会调进co_poll_inner,图2.2.3.1、图2.2.3.2分别为co_poll_inner函数上、下部分。该函数的参数ctx为epoll的环境变量,包含: epoll描述符iEpollFd,超时队列pTimeOut,已超时队列pstTimeoutList,就绪队列pstActiveList,epoll_wait就绪事件集合result。其余参数fds为socket文件描述符集合,nfds为socket文件描述符数目,timeout超时时间,pollfunc为系统poll函数。
第908行epfd是epoll_create创建的epoll描述符,相当于红黑树、就绪链表的标识,后文通过epfd管理所有fd。919到927行是在nfds少于3个时直接在栈上分配空间(更快),否则在堆上分配。第930行记录就绪fd的回调函数OnPollProcessEvent,该回调函数会切回对应的协程。第940行记录切回协程之前的预处理函数OnPollPreparePfn。第948行将每个fd通过epoll_ctl加入红黑树。第968行将arg加入超时队列pTimeOut,在980行挂起协程。等到所有协程均挂起,主协程开始运行。
图2.2.3.1
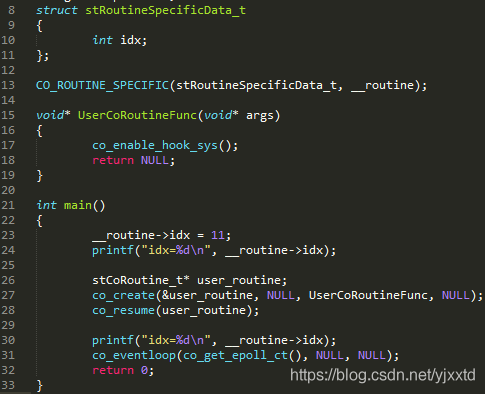
图2.2.3.2
图2.2.3.3为主协程调用的co_eventloop函数片段。co_epoll_wait找出所有就绪fd,调用pfnPrepare即OnPollPreparePfn,将就绪fd从超时队列pTimeOut移除,并加入就绪队列pstActiveList。801行用不到。TakeAllTimeout拿出超时队列里所有超时元素,并在第817行加入pstActiveList。824行到833行将807行取出的未超时事件再加回超时队列,因为TakeAllTimeout拿出的不一定都是超时事件,超时队列底层实现是60000大小的循环数组,存放每毫秒(共60000毫秒)的超时事件,每个数组的元素均是一条链表,循环数组的目的是便于通过下标找到所有超时链表。例如超时时间是10毫秒的所有事件均记录在数组下标为9(在循环数组实际的下标可能不是9,仅举个例子)的链表里,所有超时时间大于60000毫秒的事件均记录在数组下标为59999的链表里。如果取出超时时间是60000毫秒的事件,TakeAllTimeout会把超时时间大于60000毫秒的也取出来,因此需要再把超时时间大于60000毫秒的重新加回超时队列。在第836行是在协程超时或fd就绪时调用pfnProcess即OnPollProcessEvent切回协程。协程切回后,由上文2.1.2可知,协程接着co_yield_env里co_swap里的stCoRoutineEnv_t* curr_env = co_get_curr_thread_env()继续执行,co_yield_env执行完后从图2.2.3.2的第981行继续执行。第986行应该是多余的,因为pfnPrepare已经从超时队列删除事件。992行调用epoll删除当前协程的就绪fd。
注意到co_poll_inner传入的fd数组,而arg只是链表中的一个元素。假设co_poll_inner传入10个文件描述符,如果只有1个fd就绪,OnPollPreparePfn从pTimeOut删除arg,则10个文件fd都从超时队列删除,在图2.2.3.2切回协程时在第987到995行将10个描述符都从红黑树删除,然后应用层需要将9个未就绪的fd重新调用co_poll_inner再加入红黑树。如果每次只就绪一个fd,这样共需要加入红黑树:10 + 9+ 8 +… +1次,效率低于10次poll,每次只poll一个fd。co_poll_inner提供传入fd数组的原因是,co_poll_inner是poll调用的,而poll是hook的系统函数,不能改变系统的语义。系统poll支持数组的原因是,调用系统poll一次,可检查多个fd,比调用系统poll多次,每次检查一个fd,效率更高。因此系统poll适合一次poll多个fd,但libco自定义的钩子函数poll不适合一次poll多个fd,所以libco使用poll时需避免一次poll多个fd。

图2.2.3.3
2.2.4 信号量激活协程
libco提供信号量机制,类似golang的channel。example_cond.cpp举了生产者和消费者的例子,一个协程做生产者,另一个做消费者,生产者产生数据后,唤醒消费者。
主协程首先创建消费者协程,并通过co_resume切换到消费者协程函数Consumer,co_resume会调用到coctx_swap保存主协程的栈内容,并将消费者协程初始化在regs里的esp、ebp、返回地址等数据弹到寄存器和消费者协程栈里,此时开始调度消费者协程。Consumer在检查到task_queue为空时,将消费者协程通过co_cond_timedwait,加入超时队列pTimeout,并加入信号量队列env->cond,然后通过co_yield_ct切换回主协程,co_yield_ct调用到coctx_swap函数,保存消费者协程,并恢复主协程。主协程接着创建生产者协程,通过co_resume切换到生产者协程。生产者协程函数Producer在task_queue里添加数据后,通过co_cond_signal从pTimeOut、env->cond里删掉消费者协程,并加入就绪队列pstActiveList,然后通过poll挂起将生产者协程加入超时队列pTimeout,并在co_poll_inner通过co_yield_env切回到主协程。主协程在co_eventloop遍历就绪队列pstActiveList,调度消费者协程消费task_queue里数据。
2.2.5 超时激活协程
当前协程通过语句poll(NULL, 0, duration),可设置协程的超时时间间隔duration。poll是被hook住的函数,执行poll之后,当前协程会被加到超时队列pTimeOut,并被切换到其他协程,所有协程挂起后,主协程扫描超时队列,找到超时的协程,并切换。因此可用poll实现协程的睡眠。注意不可用sleep,因为sleep会睡眠线程,线程睡眠了,协程无法被调度,所有的协程也都不会执行了。
2.2.6 回调激活协程
使用libco需要hook住socket族函数,但业务代码一般使用现成的非libco网络库,如果改该网络库使其hook住socket族函数,工作量太大。因此业务侧可在协程里异步调用,异步调用后挂起协程,所有的异步回调使用同一函数,在同一回调函数里,根据异步调用时的标记决定唤醒哪个协程。该方案也可做到不分离异步调用和处理异步调用返回的数据。但需要业务侧添加一个统一的异步回调函数,并在该函数里根据标识调度协程。
2.3 协程池
协程池的好处是不用每次使用协程时都创建新的协程。创建新协程主要开销有两个:一,需要malloc协程控制块stCoRoutine_t,stCoRoutine_t有4K大小的协程私有变量数组;二,协程栈128K。每次创建新的协程要分配这么大的空间需要有时间开销,另外频繁申请、销毁会导致内存碎片的产生。即使在共享栈模式下不用为每个协程申请协程栈,也会有第一部分stCoRoutine_t的开销。每次从协程池取出协程后,将stCoRoutine_t.pfn重新初始化为用户自定义的协程函数即可。
2.4 协程私有变量
协程私有变量为每个协程独享,不会被其他协程修改,可参看example_specific.cpp。协程私有变量通过宏CO_ROUTINE_SPECIFIC定义,然后重载操作符->实现set/get。该宏首先定义线程私有变量,声明pthread_key_t类型的变量,并通过pthread_once_t保证pthread_key_t类型变量只被create一次。如果当前没有创建过协程,或者当前协程是主协程,则通过co_pthread_setspecific/pthread_getspecific来set/get线程私有变量。否则在当前协程的aSpec数组里set/get协程私有变量,pthread_key_t类型的变量作为数组下标。
pthread_once控制pthread_key_create在多线程环境中只会执行一次。_routine_init_##name控制一个线程的多个协程只会调用pthread_once一次,避免每次set、get变量时均调用pthread_once。
因为协程私有变量需要重载操作符->,因此CO_ROUTINE_SPECIFIC第一个参数必须为结构体或类。虽然aSpec有1024个容量,但通过pthread_key_create创建的key是从1开始,因此协程私有变量实际可容纳1023个元素。
3 注意事项
3.1 共享栈下内容篡改
图3.1.1所示代码,协程RoutineFuncA、RoutineFuncB共用一个共享栈。运行代码,第7行输出1,第14行输出2,但在第14行之前只在RoutineFuncA里将global_ptr指向的内容设置为1。原因是在RoutineFuncA里global_ptr指向routineidA的地址,而在RoutineFuncB里,因为是共享栈,所以routineidB和routineidA的地址一样,而该地址处的值被第13行修改为2,因此第14行打印出来2。所以共享栈模式下,需避免协程之前传递地址,因为地址的内容会被篡改。

图3.3.1
3.2 poll效率
libco自定义的钩子函数poll,虽然支持传入fd数组,但一次poll多个fd的效率,不如多次poll每次poll一个fd的效率,原因见2.2.3。
3.3 栈溢出
每个协程栈使用128K的堆内存,128K是malloc使用brk和mmap分配堆内存的分界线。但128K的空间可能不够一个协程使用,导致协程栈溢出,以下有三种解决方案。
3.3.1 堆内存
大内存不在协程栈上分配,通过malloc、new在堆上分配,可以使用编译参数-Wstack-usage检查使用较大栈空间的变量。另外栈以外空间的非法读写不一定会Crash,因此在128K协程栈上下添加保护页,并通过mprotect设置保护页权限,非法读写保护页时,程序会立即Crash,推荐使用该方案。
3.3.2 自动扩容协程栈
在协程调用的所有函数入口检查栈使用率,如果栈使用率超过阈值,就自动扩容协程栈。在进入函数时,声明一个临时变量,获取该变量的地址varaddr,因为协程栈空间高地址为stack_mem->stack_bp,低地址为stack_mem->stack_buffer,因此使用率为(stack_mem->stack_bp - varaddr) / (stack_mem->stack_bp - stack_mem->stack_buffer)。如果使用率超过阈值,重新申请大空间的新协程栈,并将旧协程栈拷贝到新协程栈。
但如果协程函数里使用了指针,比如指针ptr指向旧协程栈内存地址0xffd344c0,栈拷贝后,访问ptr的内容仍然是访问旧协程栈0xffd344c0,导致非法访问。在协程函数里使用指针的概率很大,比如声明数组,因此该方案风险较大。
golang支持协程栈的自动扩容,1.3之前是分段栈,即老栈保留,另外再开辟新栈,老栈新栈一起使用,超出老栈的数据用新栈保存。使用分段栈存在hot split问题,所以1.3及之后采用连续栈,老栈不够用时,申请大空间的新栈,并将老栈数据拷贝到新栈。拷贝老栈到新栈时,golang也面临指针失效的问题,原文参考。 但golang的编译器会管理每个指针的位置,原文参考。只要知道每个指针在老栈的位置,算出相对协程栈顶偏移量,即可将指针迁移到新栈的位置。
4 进程、线程和协程之间的区别和联系
4.1 进程
进程,直观点说,保存在硬盘上的程序运行以后,会在内存空间里形成一个独立的内存体,这个内存体有自己独立的地址空间,有自己的堆,上级挂靠单位是操作系统。操作系统会以进程为单位,分配系统资源(CPU时间片、内存等资源),进程是资源分配的最小单位,是操作系统调度的最小单位。

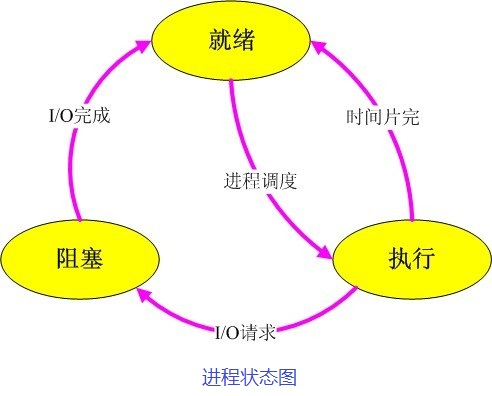
【进程间通信(IPC)】:
- 管道(Pipe)、命名管道(FIFO)、消息队列(Message Queue) 、信号量(Semaphore) 、共享内存(Shared Memory);套接字(Socket)。
4.2 线程
线程,有时被称为轻量级进程(Lightweight Process,LWP),是CPU调度、执行的最小单位。

4.3 进程和线程的区别与联系
【区别】:
- 调度:线程作为CPU调度和执行的基本单位,进程作为资源分配和操作系统调度的基本单位;
- 并发性:不仅进程之间可以并发执行,同一个进程的多个线程之间也可并发执行;
- 拥有资源:进程是拥有资源的一个独立单位,线程不拥有系统资源,但可以访问隶属于进程的资源,同时也有自己的私有存储区域,线程局部存储(TLS)。进程所维护的是程序所包含的资源(静态资源), 如:地址空间,打开的文件句柄集,文件系统状态,信号处理handler等;线程所维护的运行相关的资源(动态资源),如:运行栈,调度相关的控制信息,待处理的信号集等;
- 系统开销:在创建或撤消进程时,由于系统都要为之分配和回收资源,导致系统的开销明显大于创建或撤消线程时的开销。但是进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响,而线程只是一个进程中的不同执行路径。线程有自己的堆栈和局部变量,但线程之间没有单独的地址空间,一个线程死掉会导致所属的进程死亡,就等于所有的线程死掉,所以多进程的程序要比多线程的程序健壮,但在进程切换时,耗费资源较大,效率要差一些。
【联系】:
- 一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程;
- 资源分配给进程,同一进程的所有线程共享该进程的所有资源;
- 处理机分给线程,即真正在处理机上运行的是线程;
- 线程在执行过程中,需要协作同步。不同进程的线程间要利用消息通信的办法实现同步。
4.3.1 TLS--线程局部存储
概念:线程局部存储(Thread Local Storage,TLS)用来将数据与一个正在执行的指定线程关联起来。
进程中的全局变量与函数内定义的静态(static)变量,是各个线程都可以访问的共享变量。在一个线程修改的内存内容,对所有线程都生效。这是一个优点也是一个缺点。说它是优点,线程的数据交换变得非常快捷。说它是缺点,一个线程死掉了,其它线程也性命不保; 多个线程访问共享数据,需要昂贵的同步开销,也容易造成同步相关的BUG。
如果需要在一个线程内部的各个函数调用都能访问、但其它线程不能访问的变量(被称为static memory local to a thread 线程局部静态变量),就需要新的机制来实现。这就是TLS。
线程局部存储在不同的平台有不同的实现,可移植性不太好。幸好要实现线程局部存储并不难,最简单的办法就是建立一个全局表,通过当前线程ID去查询相应的数据,因为各个线程的ID不同,查到的数据自然也不同了。大多数平台都提供了线程局部存储的方法,无需要我们自己去实现:
1 linux:
2 int pthread_key_create(pthread_key_t *key, void (*destructor)(void*));
3 int pthread_key_delete(pthread_key_t key);
4 void *pthread_getspecific(pthread_key_t key);
5 int pthread_setspecific(pthread_key_t key, const void *value);
功能:它主要是为了避免多个线程同时访存同一全局变量或者静态变量时所导致的冲突,尤其是多个线程同时需要修改这一变量时。为了解决这个问题,我们可以通过TLS机制,为每一个使用该全局变量的线程都提供一个变量值的副本,每一个线程均可以独立地改变自己的副本,而不会和其它线程的副本冲突。从线程的角度看,就好像每一个线程都完全拥有该变量。而从全局变量的角度上来看,就好像一个全局变量被克隆成了多份副本,而每一份副本都可以被一个线程独立地改变。
4.4 进程/线程之间的亲缘性
亲缘性的意思是进程/线程只在某个cpu上运行(多核系统),比如:
1 BOOL WINAPI SetProcessAffinityMask(
2 _In_ HANDLE hProcess,
3 _In_ DWORD_PTR dwProcessAffinityMask
4 );
5 /*
6 dwProcessAffinityMask 如果是 0 , 代表当前进程只在cpu0 上工作;
7 如果是 0x03 , 转为2进制是 00000011 . 代表只在 cpu0 或 cpu1上工作;
8 */
使用CPU亲缘性的好处:设置CPU亲缘性是为了防止进程/线程在CPU的核上频繁切换,从而避免因切换带来的CPU的L1/L2 cache失效,cache失效会降低程序的性能。
4.6 协程

协程,是一种比线程更加轻量级的存在,协程不是被操作系统内核所管理,而完全是由程序所控制(也就是在用户态执行)。这样带来的好处就是性能得到了很大的提升,不会像线程切换那样消耗资源。
子程序,或者称为函数,在所有语言中都是层级调用,比如A调用B,B在执行过程中又调用了C,C执行完毕返回,B执行完毕返回,最后是A执行完毕。所以子程序调用是通过栈实现的,一个线程就是执行一个子程序。子程序调用总是一个入口,一次返回,调用顺序是明确的。而协程的调用和子程序不同。
协程在子程序内部是可中断的,然后转而执行别的子程序,在适当的时候再返回来接着执行。
1 void A()
2 {
3 printf("%c
", '1');
4 printf("%c
", '2');
5 printf("%c
", '3');
6 }
7
8 void B()
9 {
10 printf("%c
", 'x');
11 printf("%c
", 'y');
12 printf("%c
", 'z');
13 }
假设由协程执行,在执行A的过程中,可以随时中断,去执行B,B也可能在执行过程中中断再去执行A,结果可能是:1 2 x y 3 z。
协程的特点在于是一个线程执行,那和多线程比,协程有何优势?
- 极高的执行效率:因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显;
- 不需要多线程的锁机制:因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
4.7 小结

5 协程的优势
5.1 从编程风格的角度看
很多人在理解协程的时候,都会觉得协程就像个语法糖。很多的时候就像是一个异步调用的实现,等一个“I/O阻塞”的方法完成后,再切回来恢复上下文继续完成接下来的逻辑。所以总结来说,这种风格的编程更易于理解,而且一样方便于代码的复用。
5.2 从性能的角度看
1.在学习的过程中,让我最疑惑的一点是协程能否解决因“I/O阻塞”引起的性能问题?
总所周知,在我们实际的程序中遇到一些“I/O阻塞”的操作时,我们总是希望对应的线程能自觉的让出CPU时间片给其他线程,直到I/O完成后通过一些机制唤醒之前挂起的线程,这样能够提升CPU的利用率,提升程序的性能。
一个线程可以拥有多个协程,当协程运行过程中遇到了“I/O阻塞”的操作,如果协程无法让出时间片,将会导致其他的协程仍然无法运行,那么协程实际并没有解决“I/O阻塞”引起的性能问题。
所以,假若协程想解决这个问题,那么协程实现库必须是实现了一些底层的监听,例如发现当前协程即将要进行“网络I/O”时(假设当前操作系统的网络IO模型是epoll),协程库能劫持该系统调用,把这些IO操作注册到系统网络IO的epoll事件中(包括IO完成后的回调函数),注册完成则把当前协程挂起,让出cpu资源给其他协程。直到该IO操作完成,通过异步回调的方式通知该协程库去恢复之前挂起的协程,协程继续执行。
在实际场景中,不只是网络IO,硬盘的读写也会引起IO阻塞,包括我们常用的数据库读写、文件读写等。所以协程能否在这方面提升性能,要看对应协程库能否感知该操作,能否支持异步。
2.协程的同步写法却能拥有异步的性能?
这个问题实际上在上面已经得到解答了。虽然协程的使用是通过同步的写法实现的。如果希望得到性能上的提升,实际上还是通过异步回调的支持,只不过这个异步回调是底层模型上完成的。所以协程关于同步异步的性能是建立在底层的异步模型上的。
3.协程占用的空间可以比线程小
协程是用户定义的,所以在设计协程时,协程的最小空间占用可以比线程小很多。在一个服务器很难创建10W个线程,但是可以轻松的创建10W个协程。
4.协程切换比线程的切换更轻量
先控制一下变量,不考虑阻塞的问题
假设4核的cpu,100个任务并发执行
(1)创建100个线程:100个线程参与cpu调度。
(2)创建10个线程,每个线程创建10个协程:10个线程参与cpu调度,每个协程内的10个协程由协程库自己进行调度。
理论上,进程拥有100个线程时,每个线程的时间片会比拥有10个线程时短,也就意味着在相同时间里,拥有100个线程时的上下文切换次数比拥有10个线程时多。
所以协程并发模型与多线程同步模型相比,在一定条件下会减少线程切换次数,但是增加了协程切换次数,由于协程的切换是由协程库调度的,所以很难说协程切换的代价比省去的线程切换代价小,合理的方式应该是通过测试工具在具体的业务场景得出一个最好的平衡点。
6 那么什么场景使用多线程,什么场景使用协程呢(Asyncio)?
如果是 I/O 密集型,且 I/O 请求比较耗时的话,使用协程。
如果是 I/O 密集型,且 I/O 请求比较快的话,使用多线程。
如果是 计算 密集型,考虑可以使用多核 CPU,使用多进程。
参考文章:
https://blog.csdn.net/yjxxtd/article/details/93477576?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EsearchFromBaidu%7Edefault-3.pc_relevant_baidujshouduan&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EsearchFromBaidu%7Edefault-3.pc_relevant_baidujshouduan
https://blog.csdn.net/daaikuaichuan/article/details/82951084
https://www.cnblogs.com/stli/archive/2010/11/03/1867852.html
https://blog.csdn.net/u010841296/article/details/89608492
https://www.jianshu.com/p/5bbefcac9e0b