MySQL:基础—数据分组
1.为什么要分组:
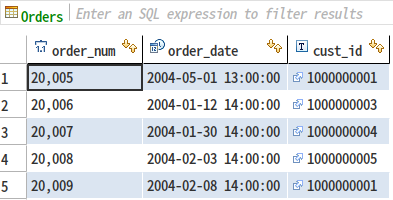
比如一个表中有多条订单记录,如上图,每条记录对应着一个商品,现在我要查询 每个商品被订购的单数 准备出货?也就是找到每个商品被订购的数量。
如果只找一个商品的话,我想是很简单的。

但是我想要表达的是,我要统计每一个商品的订单数目,而不是单单一个。效果就像这样:

此时我们就要对订单信息分类(根据ID)聚集然后进行运算,这时我们要用到分组。
说明:
使用分组可以将数据分为多个逻辑组,对每个组进行聚集计算。注意是先分为逻辑组,再进行聚集计算。
2.创建分组:
2.1语句:
GROUP BY 子句
2.2根据单个条件分组:

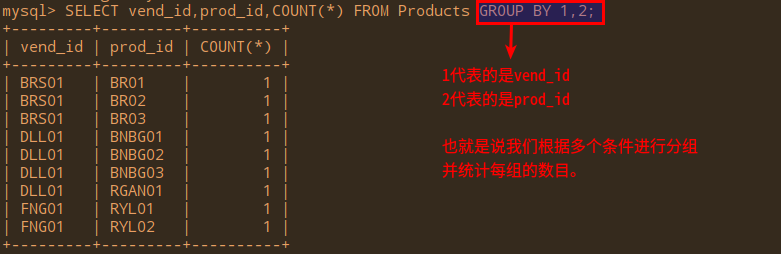
2.3根据多个条件分组:
3.过滤分组:
3.1什么是过滤分组:
我认为过滤分组表达的实质是先将记录按分组条件进行分组再根据过滤条件筛选这些分组,最后返回那些符合过滤条件的分组。
比如, 根据单个条件分组的 中,我们将每个ID的数目进行了统计输出,现在我只想要输出那些数目大于2的,就需要用到过
滤分组。
3.2HAVING语句:
这条语句就是确定过滤条件的。
如上述所说,我们显示同一个ID的产品数目大于2的。

3.3HAVING与WHERE的关系:
当我们使用时可能会有这种想法,为什么不用WHERE?那我们用WHERE试一试。

很明显语法出错,因为WHERE过滤指定的是行而不是分组。事实上,WHERE没有组的概念,而HAVING却恰恰相反。
我又有一个想法,我要进行的根据ID的分组是有条件的,比如某件商品虽然属于一个ID,但是我嫌它的价格便宜,我就不让它进行分组,这时WHERE就可以派上用场了。
有一条特性:
WHERE是在分组前进行信息过滤的,HAVING则是分组后。
