- 爬取网站:http://www.dianping.com/xian/ch0
- 反爬措施:对于某些数字和中文不是直接使用文本显示,如下图,对于"189条点评"中的8和9两个数字,"人均¥283"中的2、8和3三个数字,对于 "灞临路营背后西北200米"中的五个中文,都是经过一层字体加密
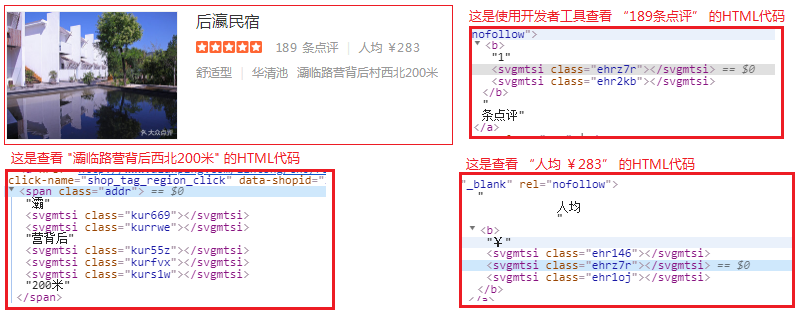
1 <!--HTML代码--> 2 <b>1<svgmtsi class="ehrz7r"></svgmtsi><svgmtsi class="ehr2kb"></svgmtsi></b>条点评 3 4 人均<b>¥<svgmtsi class="ehr146"></svgmtsi><svgmtsi class="ehrz7r"></svgmtsi><svgmtsi class="ehr1oj"></svgmtsi></b> 5 6 <span class="addr"> 7 灞 8 <svgmtsi class="kur669"></svgmtsi> 9 <svgmtsi class="kurrwe"></svgmtsi> 10 营背后 11 <svgmtsi class="kur55z"></svgmtsi> 12 <svgmtsi class="kurfvx"></svgmtsi> 13 <svgmtsi class="kurs1w"></svgmtsi> 14 200米 15 </span>
- 解决方法:F12打开谷歌浏览器的开发者工具,找到Network,检索其中的css文件和svg文件
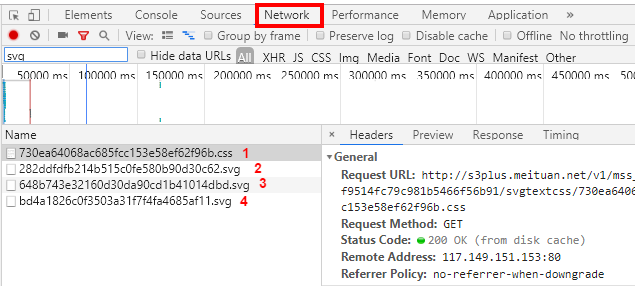
- 对于破解中文和破解数字方法是一样的,上述文件中css文件属于定位文件,根据在css中获取的位置信息查找svg中对应位置的数据
- CSS定位文件解析
1 /*CSS文件中部分CSS定位信息*/ 2 .ehrz7r{background:-19.0px -100.0px;} 3 .ehr2kb{background:-163.0px -100.0px;} 4 .kur669{background:-300.0px -145.0px;} 5 .kurrwe{background:-348.0px -96.0px;}
1 '获取定位信息' 2 def get_coordinate_value(css_url, class_): 3 'css_url为css文件链接;class_为需要获取坐标值的class值,如ehrz7r;返回值为一个二维坐标' 4 # 比如ehrz7r这个class值,获取对应的坐标值为 19,100 5 css_html = requests.get(css_url).text 6 info_css = re.findall(r'%s{background:-(d+).0px -(d+).0px' % class_, css_html, re.S)[0] 7 return info_css
- 包含数字的svg文件,以及对应HTML源代码,和根据样式类解析出数字的python函数

1 <?xml version="1.0" encoding="UTF-8" standalone="no"?> 2 <!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 1.1//EN" "http://www.w3.org/Graphics/SVG/1.1/DTD/svg11.dtd"> 3 <svg xmlns="http://www.w3.org/2000/svg" version="1.1" xmlns:xlink="http://www.w3.org/1999/xlink" width="650px" height="180.0px"> 4 <style>text {font-family:Microsoft YaHei,Hiragino Sans GB;font-size:12px;fill:#999;}</style> 5 <text x="12 24 36 48 60 72 84 96 108 120 132 144 156 168 180 192 204 216 228 240 252 264 276 288 300 312 324 336 348 360 372 384 396 408 420 432 444 456 468 480 492 504 516 528 540 552 564 576 588 600 612 624 636 648 660 672 684 696 708 720 732 744 756 768 780 792 6 804 816 828 840 852 864 876 888 900 912 924 936 948 960 972 984 996 1008 1020 1032 1044 1056 1068 1080 1092 1104 1116 1128 1140 1152 1164 1176 1188 1200 1212 1224 1236 1248 1260 1272 1284 1296 1308 1320 1332 1344 1356 1368 1380 1392 1404 1416 1428 1440 " 7 y="49">22463826571078658658528825346040036308750917596095</text> 8 <text x="12 24 36 48 60 72 84 96 108 120 132 144 156 168 180 192 204 216 228 240 252 264 276 288 300 312 324 336 348 360 372 384 396 408 420 432 444 456 468 480 492 504 516 528 540 552 564 576 588 600 612 624 636 648 660 672 684 696 708 720 732 744 756 768 780 792 9 804 816 828 840 852 864 876 888 900 912 924 936 948 960 972 984 996 1008 1020 1032 1044 1056 1068 1080 1092 1104 1116 1128 1140 1152 1164 1176 1188 1200 1212 1224 1236 1248 1260 1272 1284 1296 1308 1320 1332 1344 1356 1368 1380 1392 1404 1416 1428 1440 " 10 y="85">52284412679211790342481439513122587316130759384393</text> 11 <text x="12 24 36 48 60 72 84 96 108 120 132 144 156 168 180 192 204 216 228 240 252 264 276 288 300 312 324 336 348 360 372 384 396 408 420 432 444 456 468 480 492 504 516 528 540 552 564 576 588 600 612 624 636 648 660 672 684 696 708 720 732 744 756 768 780 792 12 804 816 828 840 852 864 876 888 900 912 924 936 948 960 972 984 996 1008 1020 1032 1044 1056 1068 1080 1092 1104 1116 1128 1140 1152 1164 1176 1188 1200 1212 1224 1236 1248 1260 1272 1284 1296 1308 1320 1332 1344 1356 1368 1380 1392 1404 1416 1428 1440 " 13 y="124">98461097490779670416</text> 14 </svg>
1 def get_completed_nums(svg_num_url, css_url, class_list): 2 'svg_num_url为包含数字的svg文件链接;css_url为css文件链接;class_list为需要进行处理获取对应数字的的class值集合' 3 completed_nums = '' 4 result_svg = requests.get(svg_num_url).text 5 6 # svg页面源码中text标签内的文本值 7 # a:22463826571078658658528825346040036308750917596095 8 # b:52284412679211790342481439513122587316130759384393 9 # c:98461097490779670416 10 a, b, c = re.findall('y=.*?>(.*?)<', result_svg, re.S) 11 12 # text标签内的y属性值 13 # 示例: 49, 85, 124 14 y1, y2, y3 = re.findall('y="(.*?)">', result_svg, re.S) 15 16 # 字体大小 # 示例:x = 12,...... 17 divisor = eval(re.search('x="(d{2}) ', result_svg, re.S).group(1)) 18 19 for class_ in class_list: 20 # 比如ehrz7r这个class值,获取对应的坐标值为 19,100,则是c[19//12]=c[1]=8 21 # 比如ehr2kb这个class值,获取对应的坐标值为 163,100,则是c[163//12]=c[13]=9 22 x, y = get_coordinate_value(css_url, class_) # 获取某一个class值的坐标值 23 x, y = int(x), int(y) 24 if y < int(y1): 25 completed_nums += a[x // divisor] 26 elif y < int(y2): 27 completed_nums += b[x // divisor] 28 elif y < int(y3): 29 completed_nums += c[x // divisor] 30 return completed_nums
- 包含中文的svg文件,以及对应HTML源代码,和根据样式类解析出中文的python函数

1 <?xml version="1.0" encoding="UTF-8" standalone="no"?> 2 <!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 1.1//EN" "http://www.w3.org/Graphics/SVG/1.1/DTD/svg11.dtd"> 3 <svg xmlns="http://www.w3.org/2000/svg" version="1.1" xmlns:xlink="http://www.w3.org/1999/xlink" width="650px" height="280.0px"> 4 <style>text {font-family:Microsoft YaHei,Hiragino Sans GB;font-size:12px;fill:#999999;}</style> 5 <text x="0" y="41">辽香金莞关华夏振宾头北和桂创肇徐健家迎潍康黑汕晋教二七远乐疆永昌汉博庆层光郑赣林民佛沿绵温府南盐乡阳</text> 6 <text x="0" y="74">泰苏皇绍宁龙凰义京花通茂石衡县银威开韶九衢一黄州军才平谊站重川东岳岛港济充肃保长河爱弄生凤常台连园津</text> 7 <text x="0" y="120">场昆洛江体农名鞍学武惠合齐市泉淄沈蒙幸嘉进古业大中机庄解三路年隆主上建曙育福放湾滨圳兴四团富公肥浙天</text> 8 <text x="0" y="169">谐六木号山无村风省门楼前文红明镇厦交源深杭吉扬八湛临拥遵工安治设春区沙廊云环坊淮冈鲁人青尔西城宜孝珠</text> 9 <text x="0" y="212">太澳锦新心湖结五胜梅内朝襄信藏陕邢哈街成迁旗烟德感海波化广十清向锡定秦宿友徽汾乌封贵甘道祥都利</text> 10 </svg>
1 def get_completed_font_425(svg_font_url, css_url, class_list): 2 """ 3 svg_font_url:字体的svg文件链接;css_url为css文件链接;class_list为需要进行处理获取对应数字的的class值集合 4 处理文字 测试期间规律:svg源码中通过y确定偏移字体所在文本行, 然后通过text[x//divisor]获取正常字符 5 """ 6 completed_font = '' 7 svg_font_text = re.sub('<?xml.*??>', '', requests.get(svg_font_url).text) 8 9 # 获取y、text值组成的元组列表 10 y_text_list = re.findall('y="(.*?)">(.*?)<', svg_font_text, re.S) 11 12 # 获取字体大小12 13 divisor = eval(re.search('font-size:(d+)px', svg_font_text, re.S).group(1)) 14 15 for class_ in class_list: 16 # class对应坐标值 比如kur669的坐标为300,145;kurrwe的坐标为348,96 17 x, y = get_coordinate_value(css_url, class_) 18 x, y = int(x), int(y) 19 # 获取当前class对应y_text_list中文字所在文本行 20 class_text = [tup[-1] for tup in y_text_list if y < int(tup[0])][0] 21 # 根据偏移量获取最终需要的文字 300//12=25 22 target_text = class_text[x // divisor] 23 completed_font += target_text 24 return completed_font