大数据平台是对海量结构化、非结构化、半机构化数据进行采集、存储、计算、统计、分析处理的一系列技术平台。大数据平台处理的数据量通常是TB级,甚至是PB或EB级的数据,这是传统数据仓库工具无法处理完成的,其涉及的技术有分布式计算、高并发处理、高可用处理、集群、实时性计算等,汇集了当前IT领域热门流行的各类技术。
大数据平台常见的一些工具汇集
主要包含:语言工具类、数据采集工具、ETL工具、数据存储工具、分析计算、查询应用及运维监控工具等。以下对各工具作为简要的说明。
一语言工具类
1、Java编程技术
Java编程技术是目前使用最为广泛的网络编程语言之一,是大数据学习的基础。Java具有简单性、面向对象、分布式、健壮性、安全性、平台独立与可移植性、多线程、动态性等特点,拥有极高的跨平台能力,是一种强类型语言,可以编写桌面应用程序、Web应用程序、分布式系统和嵌入式系统应用程序等,是大数据工程师最喜欢的编程工具,最重要的是,Hadoop以及其他大数据处理技术很多都是用Java,因此,想学好大数据,掌握Java基础是必不可少的。
2、Python与数据分析
Python是面向对象的编程语言,拥有丰富的库,使用简单,应用广泛,在大数据领域也有所应用,主要可用于数据采集、数据分析以及数据可视化等,因此,大数据开发需学习一定的Python知识。
二、数据采集类工具
1)Nutch是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具,包括全文搜索和Web爬虫。
2)Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。大数据的采集需要掌握Nutch与Scrapy爬虫技术。
三、ETL工具
1、Sqoop
Sqoop是一个用于在Hadoop和关系数据库服务器之间传输数据的工具。它用于从关系数据库(如MySQL,Oracle)导入数据到Hadoop HDFS,并从Hadoop文件系统导出到关系数据库,学习使用Sqoop对关系型数据库数据和Hadoop之间的导入有很大的帮助。
2、Kettle
Kettle是一个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。作为Pentaho的一个重要组成部分,现在在国内项目应用上逐渐增多。其数据抽取高效稳定。
四、数据存储类工具
1、Hadoop分布式存储与计算
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,MapReduce则为海量的数据提供了计算,因此,需要重点掌握,除此之外,还需要掌握Hadoop集群、Hadoop集群管理、YARN以及Hadoop高级管理等相关技术与操作!
2、Hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。相对于用Java代码编写MapReduce来说,Hive的优势明显:快速开发,人员成本低,可扩展性(自由扩展集群规模),延展性(支持自定义函数)。十分适合数据仓库的统计分析。对于Hive需掌握其安装、应用及高级操作等。
3、ZooKeeper
ZooKeeper 是一个开源的分布式协调服务,是Hadoop和HBase的重要组件,是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组件服务等,在大数据开发中要掌握ZooKeeper的常用命令及功能的实现方法。
4、HBase
HBase是一个分布式的、面向列的开源数据库,它不同于一般的关系数据库,更适合于非结构化数据存储的数据库,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,大数据开发需掌握HBase基础知识、应用、架构以及高级用法等。
5、Redis
Redis是一个Key-Value存储系统,其出现很大程度补偿了Memcached这类Key/Value存储的不足,在部分场合可以对关系数据库起到很好的补充作用,它提供了Java,C/C++,C#,PHP,JavaScript,Perl,Object-C,Python,Ruby,Erlang等客户端,使用很方便,大数据开发需掌握Redis的安装、配置及相关使用方法。
6、Kafka
Kafka是一种高吞吐量的分布式发布订阅消息系统,其在大数据开发应用上的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。大数据开发需掌握Kafka架构原理及各组件的作用和使用方法及相关功能的实现。
在在国内项目应用上逐渐增多。其数据抽取高效稳定。
五、数据分析类工具
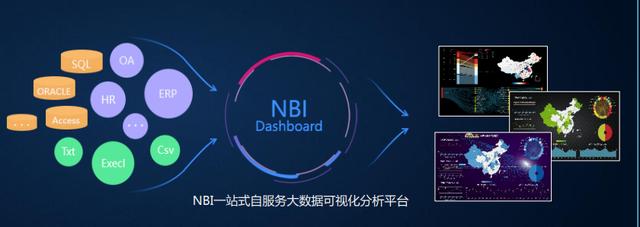
NBI一站式大数据可视化分析构建平台
NBI一站式大数据分析平台作为国内领先 的新一代自助式、探索式分析工具,在产品设 计理念上始终从用户的角度出发,一直围绕简 单、易用,强调交互分析为目的的新型产品。 我们将数据分析的各环节(数据准备、自服务 数据建模、探索式分析、权限管控)融入到系 统当中,让企业有序的、安全的管理数据和分 析数据。
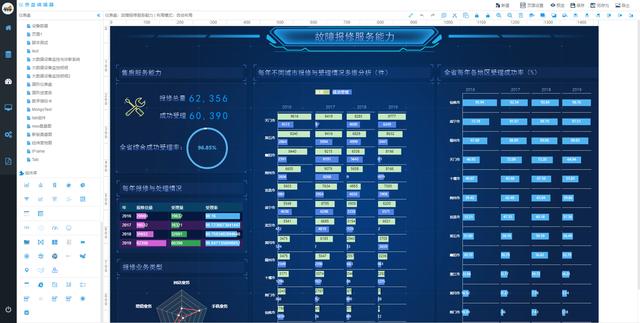
NBI一站式自服务大数据可视化分析平台 NBI数据分析决策大屏 咨询与定制化服务 只需在系统中通过拖拽式或点击的方式,即可在 几分钟内随心所欲的构建一张张精美的数据可视 化分析报告。
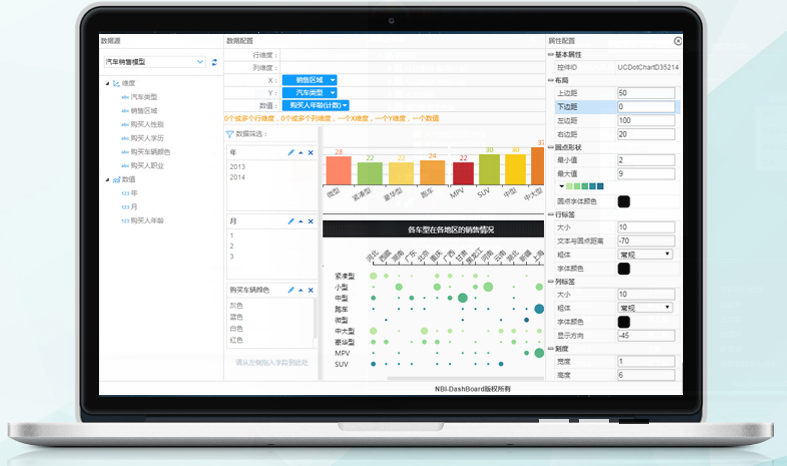
NBI拥有几十种传统图形和新型大数据图形组件(如桑 基图, treemap、层级聚类图、旭日图、热力矩 阵、日历矩阵、gis等等)能让您轻松构建各类炫 酷的数据大屏。
产品特点:

案例展示:

全方位数据接入,轻量级数据建模
无缝连接企业各种数据,告别数据孤岛,拖拽式数据建模,数据准备
就是这么简单。

简单易用的可视化分析工具
无需技术背景,只需通过拖拽方式,立刻将繁复的基础数据转换成简单易
懂的各类图形,实时了解企业经营状况,从而及时的做出更明智的决策。