首先感谢这位博主整理的Andrew Ng的deeplearning.ai的相关作业:https://blog.csdn.net/u013733326/article/details/79827273
开一个我的github传送门,可以看到代码。
https://github.com/VVV-LHY/deeplearning.ai/tree/master/improveNeuralNetwork/InitializeRegularize
L2正则化
待分类的数据点集;
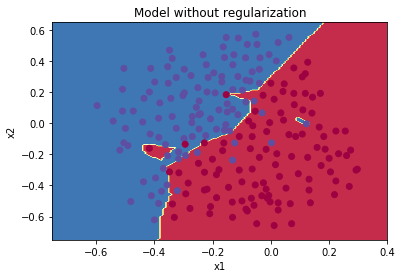
未使用L2正则化的模型迭代过程和accuracy:

使用L2正则化的模型迭代过程和accuracy:

未使用L2正则化的训练集分类效果:
使用L2正则化的训练集分类效果:

明显可以看出,未使用L2正则化的模型在训练集上过拟合了数据,使用L2正则化可以有效避免过拟合问题。
所谓L2正则化就是减小了训练集的过拟合程度,lambd参数可以让决策边界更加平滑,当然如果参数过大会导致过度平滑从而加大偏差。
L2正则化依赖于假设”较小权重的模型比较大权重的模型更简单“,因此通过削减成本函数中权重的平方值,即乘lambd(lambd < 1)来将权重逐渐变小。
L2正则化的影响:
1.成本计算花费更多
2.反向传播的花费更多
3.权重衰减,权重被逐渐改变的较小的范围
dropout正则化:
所谓dropout正则化就是随机删除隐含层单元节点的方法,可以对一个网络中的不同隐含层设置随机删除节点的百分比,这样在每一次迭代中部分节点会随机失效。
其作用是,让每一个节点相对于其他所有节点的敏感性下降,因为每次迭代中失效的节点都是随机的,其他节点在任意时间都有可能失活。
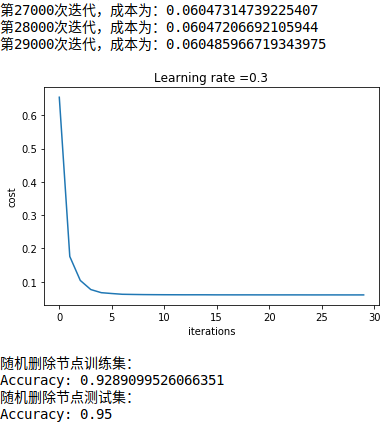
使用dropout正则化的模型迭代过程和accuracy:
使用dropout正则化的训练集分类效果:
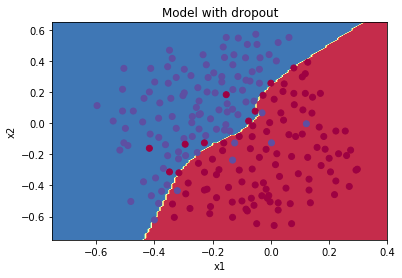
随机删除节点的正则化方法会降低训练集的准确率,但会提升测试集的准确率,所以适当的使用正则化方法不失为一种降低过拟合,提升准确率的选择。