机器学习简介
1.什么是机器学习
简而言之,机器学习是针对数据的一种建模技术。是一种从“数据”中抽象出“模型”的技术。机器学习并非唯一的建模技术,只是一种建模技术,是人工智能的一个特定的技术分支。
建模有很多机理性建模,但在某些领域,定律以及逻辑推理对建模的用处并不大。比如图像识别、语音识别、自然语言处理。该技术的核心思想就是在无法使用公式以及定理得到满意结果时,利用训练数据来建立模型。
2.机器学习存在的问题
有些问题很难通过使用物理定律或数学公式实现建模,如图像识别,机器学习的方法有其有效性,但也存在问题。
训练数据与输入数据之间存在差异是机器学习面临的结构性挑战。毫不夸张地说,它是机器学习所存在的一切问题的根源。深度学习存在的问题来源于机器学习本身。对于机器学习而言,获取能够充分反映实际领域数据特征的无偏训练数据至关重要。泛化是确保模型对于训练数据与输入数据能够获得一致性能的处理过程。机器学习能否成功很大程度上取决与泛化的有效程度。
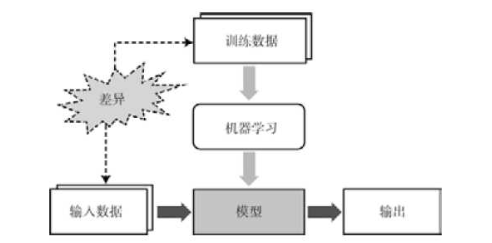
泛化过程失效的主要诱因之一是过拟合。训练数据并不是完美无瑕的,其中可能包含不同程度的噪音。下面介绍正则化或验证。
正则化是一种力求构建极简模型的数值方法。精简后的模型能以较小的性能代价避免过拟合的影响。
验证是指预留一部分训练数据,并利用其监控模型的性能的过程。交叉验证是稍加改进形成的变种。交叉验证保持验证数据的随机性。
3.机器学习分类
监督学习,无监督学习,增强学习
增强学习利用由输入、某些输出以及评分组成的数据集作为训练数据。它通常应用于需要优化折中的情况,例如控制与博弈问题。