基于数据的多重抽样的分类器
可以将不通的分类器组合起来,这种组合结果被称为集成方法(ensemble method)或者元算法(meta-algorithom)
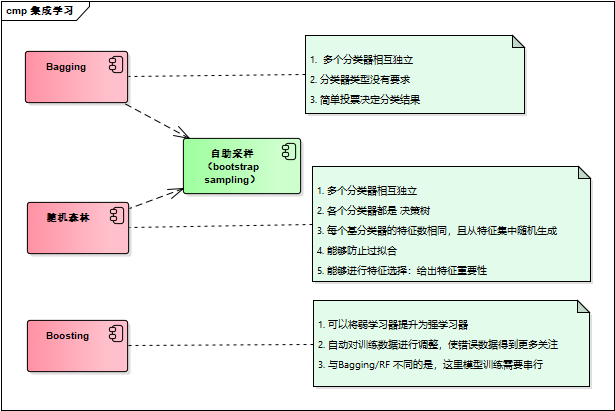
bagging : 基于数据随机抽样的分类器构建方法
自举汇聚法,也称bagging方法,从原始数据集通过随机抽样选择s次后得到s个新数据集,然后基于每个采样集训练出一个基学习器,再将这些基学习器进行结合。新数据和原始数据集的大小相等。
在S个数据集建好之后,将某个学习算法分别用于每个数据集得到S个分类器。当我们选择分类时,可以应用这S个分类器进行分类,于此同时选择选择分类器投票结果中最多的类别作为最后的分类结果
随机森林:
在以决策树为基学习器构建bagging集成的基础上,加入随机属性选择
方法:传统决策树在选择划分属性时时在当前节点的属性集合中选择最优属性,而在随机森林中,对基决策树的每个节点,先从该节点的属性集合中随机选择k个属性子集,再从子集中选择最优的属性用于划分。
随机森林中的基学习器的多样性不仅来自样本的扰动,还来自属性的扰动,使得最终集成的泛化性能通过个体学习器之间差异的增加进一步提升。
boosting:
不论是boosting还是bagging,所使用的多个分类器的类型是一致的。boosting分类器是通过串行训练而获得的,每个新分类器都根据以训练出的分类器的性能来进行训练。boosting是通过集中关注被已有分类器错分的那些数据来获得新的分类器。
boosting方法有多个,最流行的版本是AdaBoost(adaptive boosting)
1、输入训练数据和结果,以及最大迭代的次数,迭代结束的错误率(当错误率小于该阈值时不再计算)
2. 内部为每个数据分配一个权重(刚开始各个数据的权重相同),这些权重构成向量D
3. 在数据上训练第一个弱分类器,并计算错误率,并根据错误率计算分类器的权重的alpha1
4. 根据公式(需要知道alpha)重新计算数据权重,并根据此权重计算出分类器2,并计算出它的错误率和alpha2
5. 同上进行第三次迭代,得到分类器3。此时错误率小于要求的最小错误率,迭代结束。
6. 得到三个分类器以及它们的权重,当新的数据来时,迭代器可以直接用着三个迭代器计算并乘以他们的权值得到最终预测结果。
具体的Adaboost分类器的执行结果如下图所示:

基于单层决策树构建弱分类器
单层决策树:仅基于单个特征值来做决策
下面的例子中,数据只有两个特征(X1,X2):
数据加载
def loadSimpData(): datMat = matrix([[ 1. , 2.1], [ 2. , 1.1], [ 1.3, 1. ], [ 1. , 1. ], [ 2. , 1. ]]) classLabels = [1.0, 1.0, -1.0, -1.0, 1.0] return datMat,classLabels
基于单个特征值的弱分类器:
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):#just classify the data retArray = ones((shape(dataMatrix)[0],1)) if threshIneq == 'lt': retArray[dataMatrix[:,dimen] <= threshVal] = -1.0 else: retArray[dataMatrix[:,dimen] > threshVal] = -1.0 return retArray
上面的函数中输入:
dataMatrix:训练矩阵
dimen:矩阵的某一列,仅通过该列来对结果进行决策判断
threshVal: 阈值,
threshIneq: 比较的类型,有两个值 ‘lt’ 和 ‘gt’
当dimen为0,threshVal 为2,threshIneq 为 ‘lt’时,表示,将第一列(X0)小于2的元素都分为 –1 类。
对于上面的分类函数我们无法知道阈值到底选择为多大,才能够有更好的分类效果。同时,也无法知道到底按照X0进行分类好还是按照X1进行分类好。
下面的这个函数就是为了专门计算出满足条件的分类器参数:
def buildStump(dataArr,classLabels,D): dataMatrix = mat(dataArr); labelMat = mat(classLabels).T m,n = shape(dataMatrix) numSteps = 10.0; #尝试阈值,从最小值到最大值分成10步 bestStump = {}; #存放最佳结果的参数信息的 map bestClasEst = mat(zeros((m,1))) minError = inf #init error sum, to +infinity for i in range(n): #loop over all dimensions rangeMin = dataMatrix[:,i].min(); #当前列最小值 rangeMax = dataMatrix[:,i].max(); #当前列最大值 stepSize = (rangeMax-rangeMin)/numSteps #步长 for j in range(-1,int(numSteps)+1): #loop over all range in current dimension for inequal in ['lt', 'gt']: #go over less than and greater than threshVal = (rangeMin + float(j) * stepSize) predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal)#call stump classify with i, j, lessThan errArr = mat(ones((m,1))) errArr[predictedVals == labelMat] = 0 weightedError = D.T*errArr #calc total error multiplied by D #print "split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError) if weightedError < minError: #保存最优解 minError = weightedError bestClasEst = predictedVals.copy() bestStump['dim'] = i bestStump['thresh'] = threshVal bestStump['ineq'] = inequal return bestStump,minError,bestClasEst
完整的AdaBoost算法实现
上面的算法用于计算出最佳的分类的列和阈值,那么将AdaBoost算法和单层决策树结合起来呢?
#dataArr : 测试数据
#classLabels : 测试数据的标签
#numIt: 实现弱分类器的个数
def adaBoostTrainDS(dataArr,classLabels,numIt=40): weakClassArr = [] m = shape(dataArr)[0] D = mat(ones((m,1))/m) #init D to all equal aggClassEst = mat(zeros((m,1))) for i in range(numIt): bestStump,error,classEst = buildStump(dataArr,classLabels,D) #build Stump print "D:",D.T alpha = float(0.5*log((1.0-error)/max(error,1e-16)))#calc alpha, throw in max(error,eps) to account for error=0 bestStump['alpha'] = alpha weakClassArr.append(bestStump) #store Stump Params in Array #print "classEst: ",classEst.T expon = multiply(-1*alpha*mat(classLabels).T,classEst) #exponent for D calc, getting messy D = multiply(D,exp(expon)) #Calc New D for next iteration D = D/D.sum() #calc training error of all classifiers, if this is 0 quit for loop early (use break) # adaboost 将多个弱分类器结果进行相加(每个决策带有权重) aggClassEst += alpha*classEst #print "aggClassEst: ",aggClassEst.T # 通过adaboost 将多个单层决策树相加进行决策的错误率 aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1))) errorRate = aggErrors.sum()/m print "total error: ",errorRate if errorRate == 0.0: break return weakClassArr,aggClassEst
参考 :
《机器学习实战》
集成学习方法: https://www.cnblogs.com/pinard/p/6131423.html
集成学习 英文介绍: http://scikit-learn.org/dev/modules/ensemble.html#ensemble-methods