fscrawler是ES的一个文件导入插件,只需要简单的配置就可以实现将本地文件系统的文件导入到ES中进行检索,同时支持丰富的文件格式(txt.pdf,html,word...)等等。下面详细介绍下fscrawler是如何工作和配置的。
一、fscrawler的简单使用:
1、下载: wget https://repo1.maven.org/maven2/fr/pilato/elasticsearch/crawler/fscrawler/2.2/fscrawler-2.2.zip
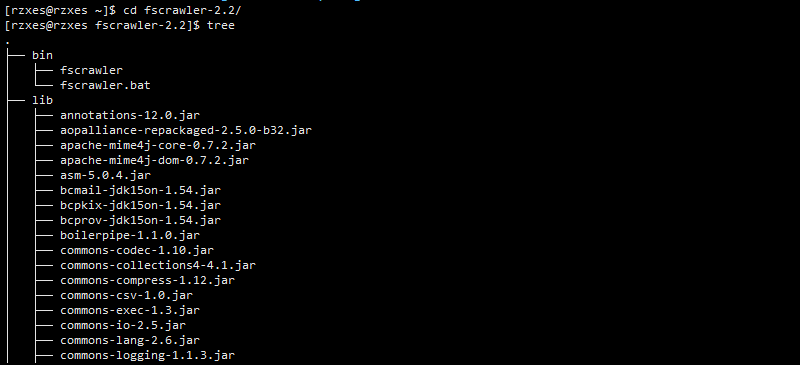
2、解压: unzip fscrawler-2.2.zip 目录如下:bin下两个脚本,lib下全部是jar包。
3、启动: bin/fscrawler job_name job_name需要自己设定,第一次启动这个job会创建一个相关的_setting.json用来配置文件和es相关的信息。如下:

- 编辑这个文件: vim ~/.fscrawler/job_1/_settting.json 修改如下:
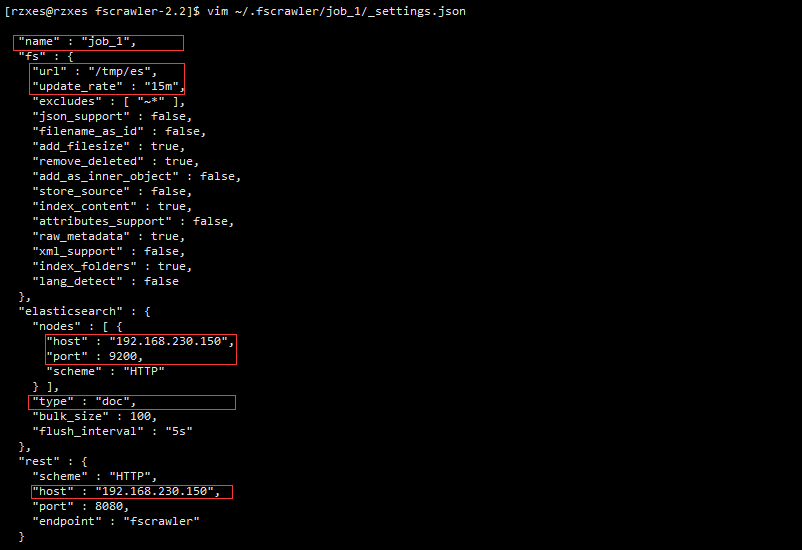
name表示的是一个job的name同时也是ES数据的的index,URL:代表需要导入的文件所在的文件夹。update_rate:表示多久刷新一次,host:连接es的IP地址和端口号。type:代表的就是ES的type。改完之后保存就可以运行,fs就会将数据导入了。
- 导入数据(会开启一个线程,根据设定的时间进行数据刷新,我们修改文件ES也能得到新的数据):bin/fscrawler job_name
二、fscrawler配置IK分词器和同义词过滤:
- 初始化一个job后系统会生成三个配置文件:doc.json,folder.json,_setting.json(1,2,5代表ES的版本号,我们是5.x版本就修改5文件夹下的配置文件。)这三个文件用来创建index,mapping。

- 配置IK分词首先在_default/5/_setting.json中配置analysis:删掉原有的配置文件,添加如下内容:
-
{ "settings": { "analysis": { "analyzer": { "by_smart": { "type": "custom", "tokenizer": "ik_smart", "filter": [ "by_tfr", "by_sfr" ], "char_filter": [ "by_cfr" ] }, "by_max_word": { "type": "custom", "tokenizer": "ik_max_word", "filter": [ "by_tfr", "by_sfr" ], "char_filter": [ "by_cfr" ] } }, "filter": { "by_tfr": { "type": "stop", "stopwords": [ " " ] }, "by_sfr": { "type": "synonym", "synonyms_path": "analysis/synonyms.txt" } }, "char_filter": { "by_cfr": { "type": "mapping", "mappings": [ "| => |" ] } } } } }
跟前面几篇博客中提到的自定义分词器创建同义词过滤一模一样,里面的filter可以选择删除,保留必要的部分,这样我们自定义了两种分词器:by_smart,by_max_word.
- 修改_default/5/doc.json:删除掉所有字段的分词器;analyzer:"xxx",因为在这里只有一个字段需要分词那就是content(文件的内容),给content节点添加加分词器。如下:
-
"content" : { "type" : "text", "analyzer":"by_max_word" #添加此行。。。 },
- 配置就完成了,同样的再次启动job: bin/fscrawler job_name
- 访问9100:可以看到index已经创建好,如下图:

- 同义词查询:我在同义词中配置了西红柿和番茄,在/tmp/es文件夹下中添加了一个包含西红柿和番茄的文件,9100端口用以下语句查询:
-
{ "query": { "match": { "content": "番茄" } }, "highlight": { "pre_tags": [ "<tag1>", "<tag2>" ], "post_tags": [ "</tag1>", "</tag2>" ], "fields": { "content": {} } } }
结果如下:
-
{ "hits": [ { "_index": "jb_8", "_type": "doc", "_id": "3a15a979b4684d8a5d86136257888d73", "_score": 0.49273878, "_source": { "content": "我爱吃西红柿鸡蛋面。还喜欢番茄炒蛋饭", "meta": { "raw": { "X-Parsed-By": "org.apache.tika.parser.DefaultParser", "Content-Encoding": "UTF-8", "Content-Type": "text/plain;charset=UTF-8" } }, "file": { "extension": "txt", "content_type": "text/plain;charset=UTF-8", "last_modified": "2017-05-24T10: 22: 31", "indexing_date": "2017-05-25T14: 08: 10.881", "filesize": 55, "filename": "sy.txt", "url": "file: ///tmp/es/sy.txt" }, "path": { "encoded": "824b64ab42d4b63cda6e747e2b80e5", "root": "824b64ab42d4b63cda6e747e2b80e5", "virtual": "/", "real": "/tmp/es/sy.txt" } }, "highlight": { "content": [ "我爱吃<tag1>西红柿</tag1>鸡蛋面。还喜欢<tag1>番茄</tag1>炒蛋饭" ] } } ] }
-
完整的IK分词同义词过滤就配置完成了。
- 如下图是txt,html格式,其他格式亲测可用,但是文件名中文会乱码。
注意:
要选择fs2.2的版本,2.1的版本在5.3.1的ES上连接失败。