最近迷上了抓娃娃,去富国海底世界抓了不少,完全停不下来,还下各种抓娃娃的软件,梦想着有一天买个抓娃娃的机器存家里~.~
今天顺便抓了下马爸爸家抓娃娃机器的信息,晚辈只是觉得翻得手酸,本来100页的数据,就抓了56条,还希望马爸爸莫怪。。。。
有对爬虫的感兴趣的媛友,可以作为参考哦!
1 # coding:utf-8
2
3 import pymongo
4 import time
5 import re
6 from selenium import webdriver
7 from bs4 import BeautifulSoup
8 from selenium.webdriver.common.by import By
9 from selenium.common.exceptions import TimeoutException
10 from selenium.webdriver.support.ui import WebDriverWait
11 from selenium.webdriver.support import expected_conditions as EC
12 # 使用无界面浏览器
13 from selenium.webdriver.chrome.options import Options
14 # 创建驱动对象
15 chrome_options = webdriver.ChromeOptions()
16 # 设置代理
17 # chrome_options.add_argument('--proxy-server=http://ip:port')
18 # 加载浏览器头
19 # 更换头部
20 chrome_options.add_argument('User-Agent="Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36"')
21 # 不加载图片
22 prefs = {"profile.managed_default_content_settings.images":2}
23 chrome_options.add_experimental_option("prefs",prefs)
24 # 设置无界面浏览器
25 chrome_options = Options()
26 chrome_options.add_argument('--headless')
27 chrome_options.add_argument('--disable--gpu')
28 driver = webdriver.Chrome(chrome_options=chrome_options)
29
30 # 设置显示等待时间
31 wait = WebDriverWait(driver,1)
32
33 # 翻页 在底部输入框输入页数进行翻页
34 def next_page(page_num):
35 try:
36 print ('正在翻第----%s------页' %page_num)
37 # 获得页码输入框 try是否超时报错
38 input = wait.until(
39 EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.form > input'))
40 )
41 # 清空输入框的内容
42 input.clear()
43 # 输入框输入页码
44 input.send_keys(page_num)
45 # 获得确定按钮
46 btn = driver.find_element_by_class_name('.btn J_Submit')
47 # 点击确定按钮
48 btn.click()
49 # 根据对应页码高亮部分判断是否成功
50 # 获得高亮部分
51 wait.until(
52 EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > ul > li.item.active > span'))
53 )
54 parse_html(driver.page_source)
55 except TimeoutException:
56 # 报错重新请求
57 return next_page(page_num)
58
59 def save_mongo(data):
60 client = pymongo.MongoClient('60.205.211.210',27017)
61 # 连接数据库
62 db = client.test
63 # 连接集合
64 collection = db.taobao
65 # 插入数据
66 collection.insert(data)
67
68 def parse_html(html):
69 html_page = BeautifulSoup(html,'lxml')
70 items = html_page.select('.m-itemlist .items .item')
71 for item in items:
72 # 图片url
73 img_url = item.select('.pic .pic-link')[0].attrs['href']
74 if img_url.startswith('//'):
75 img_url = 'https:' + img_url
76 # print (img_url)
77 # 价格
78 price = item.select('.price')[0].text.strip()[1:]
79 # print (price)
80 # 销量
81 sales = re.search(r'(d+)',item.select('.deal-cnt')[0].text).group(1)
82 # print (sales)
83 # 商品描述
84 desc = item.select('.title .J_ClickStat')[0].text.strip()
85 # print (desc)
86 # 店铺
87 shop = item.select('.shop .dsrs + span')[0].text.strip()
88 # print (shop)
89 # 地址
90 address = item.select('.location')[0].text.strip()
91 # print(address)
92 product_data = {
93 'img_url':img_url,
94 'price':price,
95 'desc':desc,
96 'sales':sales,
97 'shop':shop,
98 'address':address
99 }
100 print (product_data)
101 save_mongo(product_data)
102
103 def get_page(url):
104 try:
105 driver.get(url)
106 search_input = wait.until(
107 # 参数为元祖
108 EC.presence_of_element_located((By.ID,'q'))
109 )
110 search_input.send_keys(u'抓娃娃')
111 btn = driver.find_element_by_class_name('btn-search')
112 btn.click()
113 # 实现翻页 需要把总页数return出去
114 total_pages = driver.find_element_by_css_selector('#mainsrp-pager > div > div > div > div.total').text
115 total_pages_num = re.compile(r'(d+)').search(total_pages).group(1)
116 # print (total_pages_num)
117 parse_html(driver.page_source)
118 return total_pages_num
119 except TimeoutException as e:
120 print (e.msg)
121
122 def main():
123 url = 'https://www.taobao.com'
124 try:
125 page_num = get_page(url)
126 # for i in range(2,int(page_num)+1):
127 for i in range(2, int(page_num) - 96):
128 next_page(i)
129 except Exception as e:
130 print (e.message)
131 finally:
132 driver.close()
133
134 if __name__ == '__main__':
135 main()
要是环境配置好了,可以直接跑一下哦!
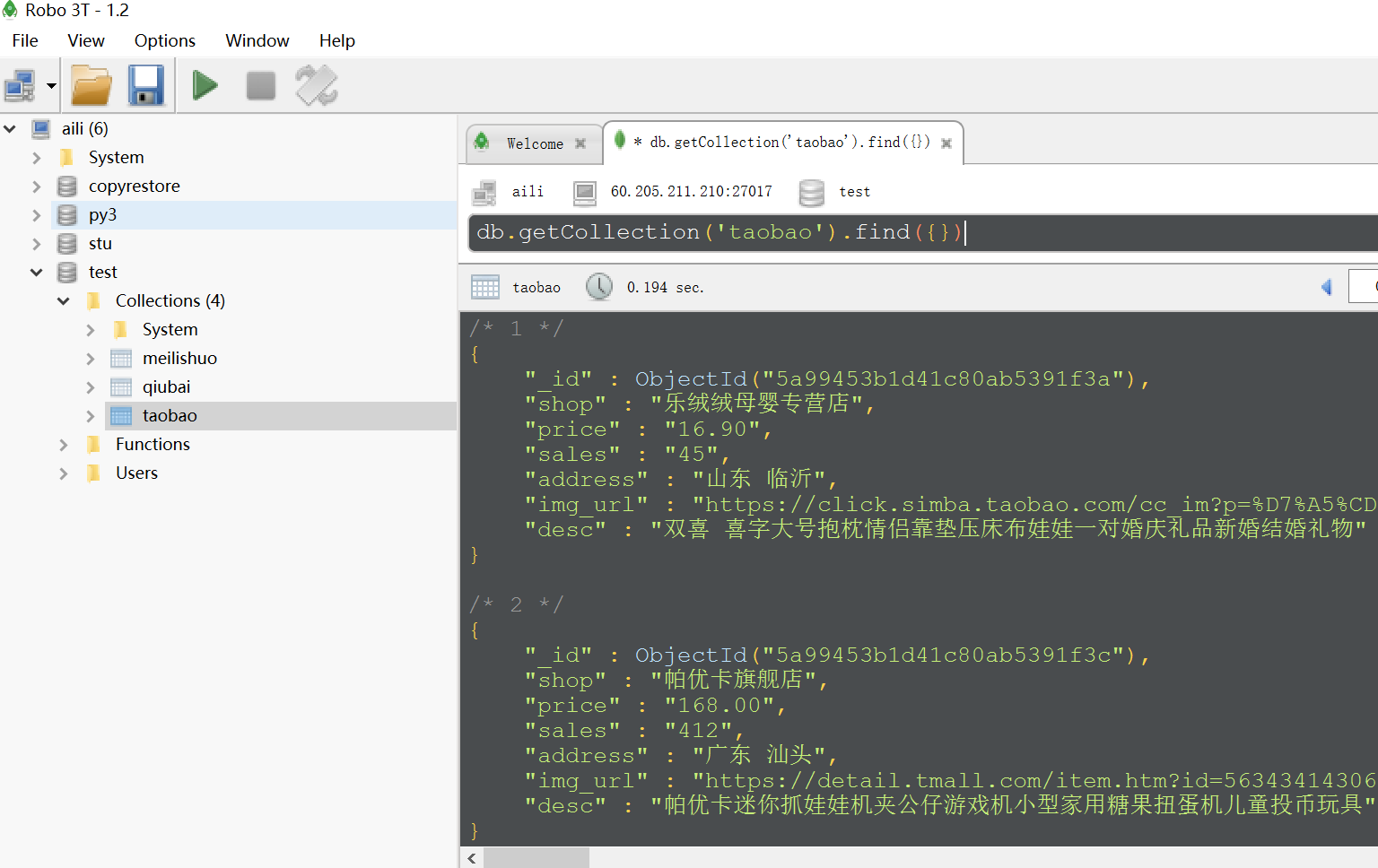
下面是mongo数据库数据: